대부분의 RAG(Retrieval-Augmented Generation) 튜토리얼은 문서를 고정된 크기로 청킹(Chunking)하여 벡터 DB에 넣고 Top-K 결과를 LLM에 던지는 방식을 제안한다. 그러나 데이터 중심의 엄밀한 시각에서 보면, 이는 프로덕션 환경에서 통계적으로 실패가 예정된 안티 패턴이다. 단순 Top-K 검색은 사용자의 쿼리가 지식베이스의 도메인을 벗어났을 때도 무조건 K개의 무의미한 컨텍스트를 반환하며, 이는 필연적으로 LLM의 할루시네이션(Hallucination)을 유발한다. 또한, 실서비스 환경에서 빈번히 발생하는 데이터베이스의 동시성(Concurrency) 병목은 RAG 시스템의 P99 지연 시간(Latency)을 치명적으로 악화시키는 주범이다.
최근 dev.to에 공유된 프로덕션 RAG 구축 사례들은 이 문제를 해결하기 위한 정량적 접근법을 명확히 제시한다. 첫 번째 핵심은 검색의 신뢰도(Reliability) 확보다. 의미론적 단절을 막기 위해 재귀적 청킹(Recursive Chunking)을 도입하고, 단순 Top-K 대신 '유사도 임계값(Similarity Threshold)'을 적용해야 한다. 임계값을 넘지 못하는 결과는 과감히 버림으로써 모델에 주입되는 노이즈를 원천 차단하는 것이다. 나아가 타겟 개수의 3배수를 초과 검색(Over-fetch)한 뒤 교차 인코더(Cross-encoder)나 어휘 오버랩 기반으로 재정렬(Re-ranking)하는 파이프라인은 연산 비용(Computational Cost)을 소폭 증가시키지만, RAG의 핵심 평가 지표인 컨텍스트 정밀도(Context Precision)를 비약적으로 상승시킨다.
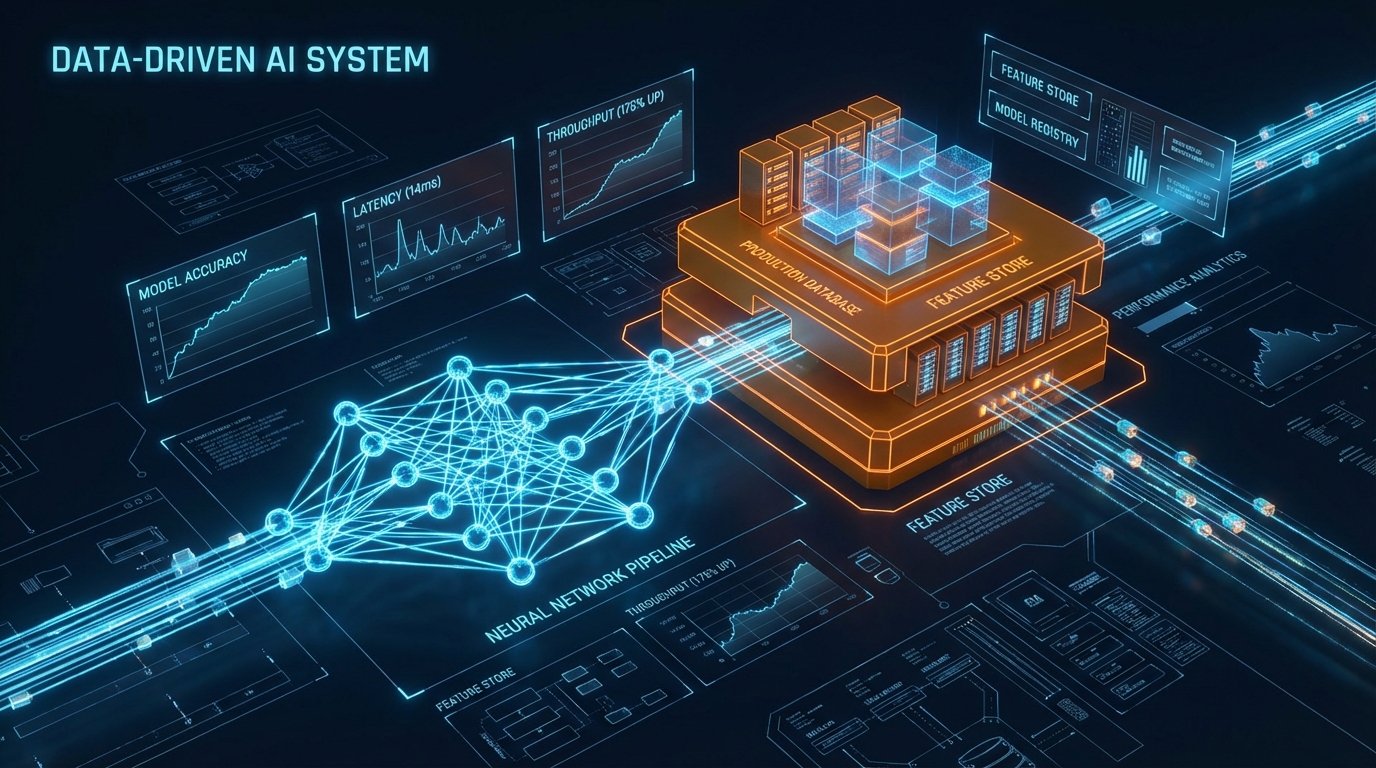
그러나 검색 파이프라인의 고도화는 필연적으로 데이터베이스의 부하를 가중시킨다. AI 지식 관리 시스템 LedgerMind의 사례(dev.to)는 프로덕션 환경에서 I/O 병목이 어떻게 런타임 장애로 이어지는지 수치로 증명한다. 다수의 에이전트가 동시에 지식 DB에 접근할 때 발생하는 TOCTOU(Time-Of-Check-To-Time-Of-Use) 경쟁 상태(Race Condition)와 SQLite의 락(Lock) 현상은 시스템을 완전히 마비시켰다. 이들은 단순한 애플리케이션 레벨의 재시도(Retry) 로직에 의존하는 대신, 트랜잭션 단위의 엄밀한 ACID 보장, 인덱스 튜닝, 메타데이터 배치 처리 및 벡터 스토어 지연 로딩(Deferred Loading)을 아키텍처 수준에서 도입했다.
결과는 명확한 데이터로 나타났다. 인덱스 튜닝 전 풀 테이블 스캔으로 인해 초당 2,000에 머물렀던 검색 OPS(Operations Per Second)는 최적화 후 5,500 이상으로 175% 향상되었으며, 쓰기 지연 시간은 500ms에서 14ms로 무려 97% 감소했다. 이는 리랭킹과 같은 복잡한 연산이 파이프라인에 추가되더라도, 기저에 있는 데이터베이스의 I/O 처리량이 뒷받침된다면 전체 시스템의 스루풋(Throughput)을 성공적으로 방어할 수 있음을 시사한다. 또한, 늘어난 백엔드 연산 시간으로 인한 사용자 경험 저하는 LLM의 스트리밍(Streaming) 응답 처리를 통해 체감 지연 시간을 효과적으로 은닉함으로써 상쇄할 수 있다.
생성형 AI 시스템의 최적화는 단순한 프롬프트 엔지니어링이나 최신 프레임워크 도입만으로 완성되지 않는다. 검색 정확도(Retrieval Accuracy)와 생성 품질(Generation Quality)을 독립적인 메트릭으로 분리하여 측정하고, 리랭킹이 유발하는 컴퓨팅 비용과 DB 아키텍처 개선으로 얻는 레이턴시 이득 간의 트레이드오프를 정밀하게 통제해야 한다. '작동하는 데모'를 넘어 '신뢰할 수 있는 프로덕션 RAG'를 구축하려면, 결국 통계적 유의성에 기반한 평가 파이프라인과 엄밀한 인프라 엔지니어링의 결합이 필수적이다.