프로덕션 환경에서 RAG(Retrieval-Augmented Generation) 시스템을 운영할 때 직면하는 가장 치명적인 병목은 '검색 성능' 자체가 아니라, 생성된 응답이 실제로 검색된 컨텍스트에 기반하고 있는지 증명하는 '컨텍스트 귀속도(Context Attribution)'의 검증이다. LLM이 그럴듯한 답변을 내놓았을 때, 이것이 파이프라인이 주입한 문서에서 기인한 것인지, 아니면 모델의 파라메트릭 메모리(Parametric Memory)에서 발현된 환각(Hallucination)인지 실시간으로 판별하는 것은 극히 어렵다. 기존의 LLM-as-a-Judge나 사람의 개입을 요구하는 평가 방식은 재현성(Reproducibility)이 떨어지며, 대리 모델(Surrogate Model)을 활용하는 방식은 수백 번의 Forward Call을 유발하여 서빙 환경의 P99 지연 시간(Latency)과 컴퓨팅 비용을 파괴한다. 이러한 맥락에서 최근 제안된 ARC-JSD(Attributing Response to Context via Jensen-Shannon Divergence) 방법론은 추가적인 미세조정이나 막대한 연산 오버헤드 없이 환각을 정량적으로 평가할 수 있는 강력한 통계적 대안을 제시한다.
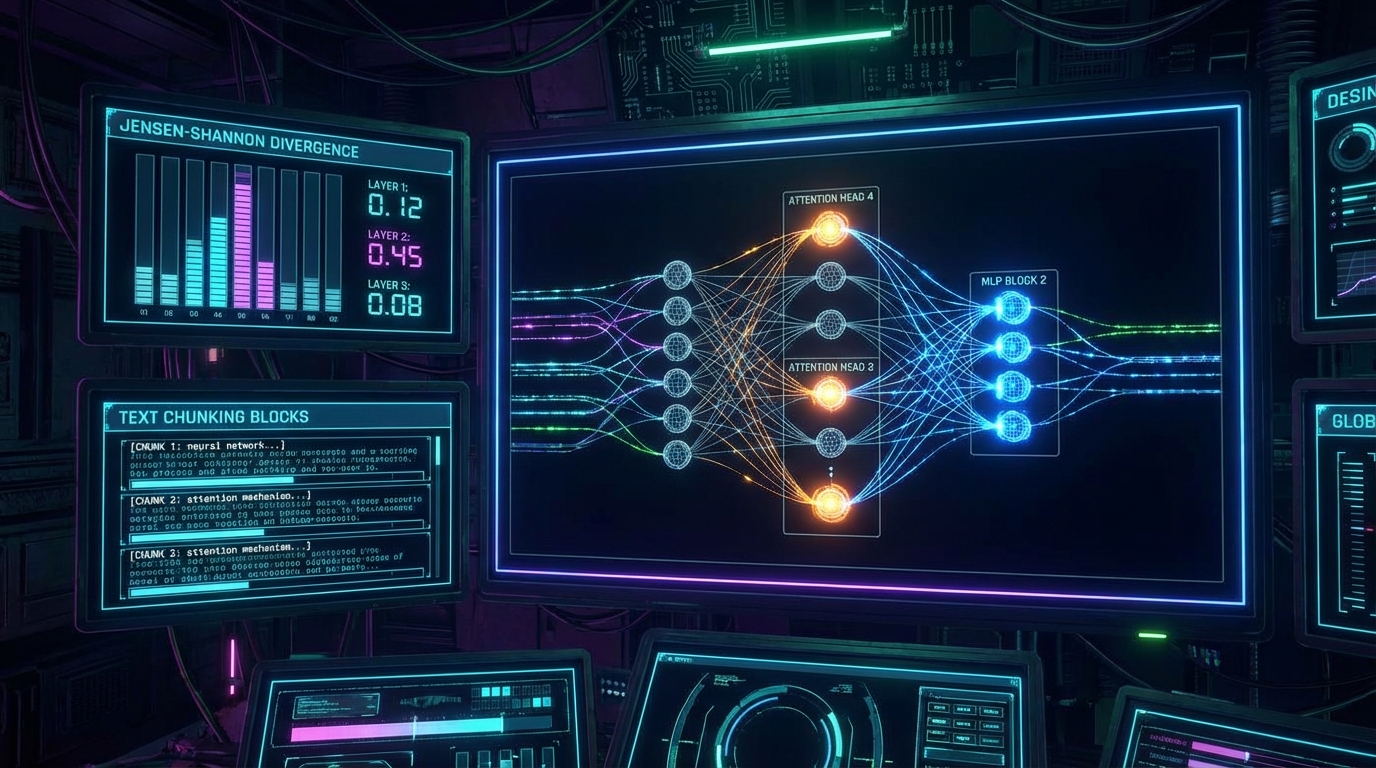
이러한 기계론적(Mechanistic) 평가가 유의미한 통계적 신뢰도를 확보하기 위해서는 데이터 파이프라인 최단의 텍스트 분할(Chunking) 전략이 선행되어야 한다. LangChain의 RecursiveCharacterTextSplitter와 같은 도구는 단순히 LLM의 컨텍스트 윈도우에 텍스트를 욱여넣기 위한 수단이 아니다. 정량적 분석 관점에서 청크(Chunk)는 어트리뷰션 평가의 '최소 독립 변수'로 작용한다. 문서 로딩 단계에서 메타데이터를 보존하고, 계층적 구분자(Separators)를 통해 의미론적 무결성을 유지하며 청크 크기와 오버랩(Overlap)을 설정하는 과정은 향후 Ablation 실험의 해상도를 결정짓는다. 청크 사이즈가 너무 크면 환각의 정확한 발생 지점을 특정할 수 없고(Underfitting), 너무 작으면 컨텍스트 단편화로 인해 JSD 측정 시 노이즈가 급증(Overfitting)하는 트레이드오프가 발생한다.
청크 파이프라인이 정규화되었다면, ARC-JSD는 본격적으로 '블랙박스' 내부의 확률 분포 변화를 측정한다. 작동 원리는 직관적이면서도 수학적으로 엄밀하다. 전체 컨텍스트를 주었을 때의 응답 확률과, 특정 청크(문장 단위)를 마스킹(Masking)했을 때의 응답 확률 간의 차이를 Jensen-Shannon Divergence(JSD)로 계산하는 것이다. KL Divergence가 특정 확률이 0에 수렴할 때 값이 무한대로 발산하는 페널티를 안고 있고, TV Distance가 분포의 미세한 변화에 지나치게 둔감한 반면, JSD는 0과 1 사이로 정규화(Bounded)되어 있으며 대칭성을 띠어 벤치마크 지표로 삼기에 최적의 특성을 지닌다. 특정 청크를 제거했을 때 JSD 값이 임계치를 돌파하며 급변한다면, 시스템은 해당 청크를 생성 응답의 '결정적 근거'로 정량화할 수 있다.
더욱 주목해야 할 점은 ARC-JSD가 단순한 외부 관찰(Output Distribution)을 넘어, LLM 내부 구조에 대한 기계론적 해석(Mechanistic Interpretability)을 시도했다는 것이다. JSD 기반 분석을 Logit Lens 기법과 결합하여 신경망 내부를 프로빙(Probing)한 결과, 컨텍스트 귀속과 정보 통합 작업은 주로 모델의 중상위 레이어에 위치한 특정 Attention Head와 MLP(Multilayer Perceptron) 계층에서 발생함이 확인되었다. 이는 LLM이 단순히 검색된 텍스트를 복사-붙여넣기(Copy-paste)하는 것이 아니라, 명확한 연산 경로를 통해 정보를 종합하고 있음을 데이터로 증명한 것이다. 프로덕션 관점에서 이는 매우 중요한 시사점을 갖는다. 환각 발생 시 단순히 프롬프트를 수정하는 '기도 메타(Hope-based Engineering)'에서 벗어나, 특정 MLP 계층의 활성화 패턴을 모니터링하여 구조적 오류를 진단할 수 있는 길이 열린 것이다.
이 아키텍처는 비용-성능 트레이드오프 측면에서 명확한 우위를 점한다. JSD 점수를 일종의 '신뢰도 게이트(Confidence Gate)'로 활용하면, 모든 청크의 JSD 점수가 기준치 미만일 경우 시스템은 즉각적으로 "주어진 컨텍스트 내에 근거가 부족하다"는 예외 처리(Fallback)를 트리거할 수 있다. 비결정적인 LLM의 텍스트 생성에 의존하여 환각을 판단하는 대신, 로짓(Logit) 레벨의 수학적 다이버전스를 기준으로 라우팅 전략(Routing Strategy)을 결정하게 되는 것이다. 이는 API 호출 낭비를 방지하고, 에이전트 시스템에서 발생할 수 있는 '환각의 연쇄 증폭' 현상을 사전에 차단하여 추론 예산을 획기적으로 절감한다.
결론적으로, 효율적인 RAG 시스템은 Retrieval의 정확도와 Generation의 품질을 독립된 축으로 분리하여 평가할 수 있어야 한다. LangChain 기반의 정교한 텍스트 청킹이 양질의 인덱싱(Indexing)을 보장한다면, ARC-JSD는 응답과 컨텍스트 간의 인과관계를 계산 비용 효율적으로 입증한다. 앞으로의 AI 엔지니어링은 모델의 파라미터 크기에 의존하는 단계를 지나, 출력의 확률 분포를 통제하고 기계론적 지표를 기반으로 동적 라우팅을 수행하는 '데이터 및 확률 중심의 오케스트레이션'으로 진화할 것이다. 이는 곧 시스템의 신뢰성과 직결되며, 엔터프라이즈 환경에서 생성형 AI를 도입하기 위한 필수적인 감사(Audit) 파이프라인의 표준이 될 것이다.