'AI가 UI를 만든다'는 말이 마케팅 수사에서 실제 프로덕션 아키텍처로 이동하고 있다. 그런데 막상 구현 단계에서 맞닥뜨리는 현실은 생각보다 까다롭다. LLM에게 UI 구조와 데이터를 동시에 생성하게 하면, 토큰 비용은 폭발하고 응답 속도는 느려지며 할루시네이션 리스크는 높아진다. Generative UI가 가진 가능성만큼이나, 아무 생각 없이 구현하면 오히려 기술 부채를 쌓는 가장 빠른 방법이 되어버린다.
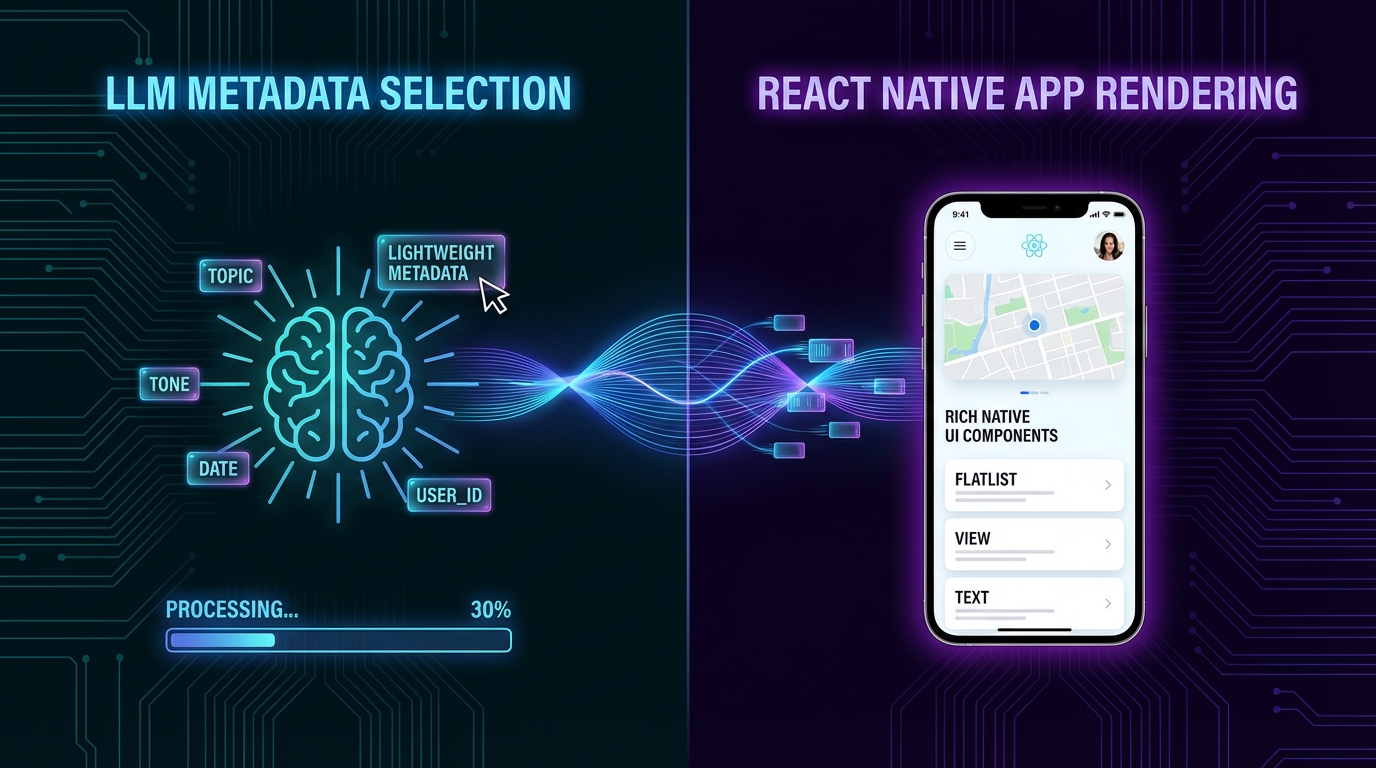
dev.to에 공개된 Fonyx 모바일 앱 사례는 이 문제를 정면으로 다룬다. 핵심 전략은 단순하다: LLM에게 데이터를 생성하게 하지 말고, 어떤 UI를 렌더링할지만 결정하게 하라. 이른바 'Metadata over Data' 원칙이다. LLM이 {"tool": "line_history_values", "args": {"fund_code": "AFT", "limit": 30}} 같은 경량 메타데이터만 반환하면, 실제 데이터 페칭과 렌더링은 클라이언트가 처리한다. 결과적으로 LLM이 생성해야 할 토큰은 2,000~5,000개에서 20~40개 수준으로 줄어든다. 100배 이상의 비용 절감이 이론이 아닌 구조적으로 달성 가능해지는 것이다.
이 아키텍처가 작동하는 방식은 3개 레이어의 명확한 책임 분리에 기반한다. LLM은 의사결정 엔진이다—어떤 컴포넌트를 렌더링할지 선택하는 역할만 한다. 클라이언트는 오케스트레이터다—tool call을 받아 실제 API를 호출하고 데이터를 가져온다. UI 컴포넌트는 자율적 실행자다—자기 자신의 데이터 페칭과 로딩 상태, 렌더링을 스스로 책임진다. 이 분리가 무너지는 순간, 즉 LLM에게 데이터까지 생성하게 하는 순간, 시스템 전체가 불안정해진다.
여기서 간과하기 쉬운 부분이 있다. LLM 출력을 절대 맹신해선 안 된다는 점이다. tool call의 인자를 Zod 같은 스키마 검증 라이브러리로 반드시 검증해야 한다. fund_code의 길이를 제한하고, limit에 기본값을 부여하는 식의 방어 로직이 없으면, 할루시네이션된 파라미터가 그대로 UI에 흘러들어가 런타임 크래시로 이어진다. Generative UI는 '믿음'이 아닌 '검증' 위에서만 안정적으로 동작한다.
그런데 이 아키텍처 패턴을 보면서 자연스럽게 떠오르는 질문이 있다. 이 모든 걸 설계하는 주체는 누구인가? LLM이 무엇을 렌더링할지 결정한다 해도, 어떤 tool을 정의하고, 레이어 간 경계를 어디에 그으며, 어떤 시스템 프롬프트로 LLM의 행동을 제약할지—이 설계는 여전히 인간 개발자의 몫이다. dev.to의 또 다른 글에서 표현한 것처럼, AI는 별(코드)을 만들지만 중력(구조)은 만들지 못한다. AI가 생성하는 코드의 양이 늘어날수록, 그 코드에 질서를 부여하는 설계 능력의 가치는 오히려 올라간다.
국내 개발자가 주말 동안 Claude Code와 Codex를 병행해 게임 개발 플랫폼 Funnable을 만든 사례도 같은 맥락을 가리킨다. 24시간 동안 117개의 커밋이 쌓였고, 웹 UI, API 연동, i18n, 인프라 연동 모두 에이전트가 빠르게 처리했다. 하지만 게임 밸런싱—'적이 너무 빠른지', '이 구간이 너무 긴지'—은 끝내 에이전트가 판단하지 못했다. 플레이 경험이라는 감각을 에이전트는 갖지 않기 때문이다. 구현 속도는 AI가 가져갔지만, 경험의 질을 결정하는 판단은 인간이 위임받았다.
Generative UI 아키텍처를 실제로 설계할 때 프론트엔드 개발자가 집중해야 할 것은 세 가지로 요약된다. 첫째, tool 정의의 정밀도다. LLM이 어떤 tool을 선택할지는 description의 품질에 달려 있다. 모호한 설명은 엉뚱한 컴포넌트 선택으로 이어진다. 둘째, 시스템 프롬프트의 제약 설계다. 'Never generate datasets. Only select tools and return minimal metadata'처럼 LLM의 행동 범위를 명시적으로 좁히는 전략이 신뢰성을 결정적으로 높인다. 셋째, 캐싱과 관측 가능성(observability)이다. 동일한 사용자 의도에 대해 매번 LLM을 호출하는 것은 낭비다. tool decision cache로 중복 호출을 막고, 토큰 사용량·레이턴시·에러율을 추적하는 트레이싱 미들웨어를 프로덕션 단계부터 심어야 한다.
Generative UI는 프론트엔드 개발을 단순화하지 않는다. 오히려 더 정교한 아키텍처 판단을 요구한다. LLM을 'UI 결정 엔진'으로 좁게 정의하고, 나머지 책임을 클라이언트 레이어로 명확히 분리하는 설계—이것이 비용과 신뢰성과 UX를 동시에 잡는 유일한 경로다. 그리고 그 설계의 주도권은, 여전히 프론트엔드 개발자가 쥐고 있다.