대시보드 탈출, 이제 진짜로 가능해졌다
프로덕션 에러가 터졌을 때의 흐름을 떠올려보자. Sentry 대시보드 열고, 스택 트레이스 복사하고, 에디터로 돌아와 붙여넣고, 다시 컨텍스트를 복원한다. 이 맥락 전환(context switch)의 비용은 단순한 시간 낭비가 아니다. 집중력이 끊기는 순간, 디버깅의 실마리도 같이 끊긴다.
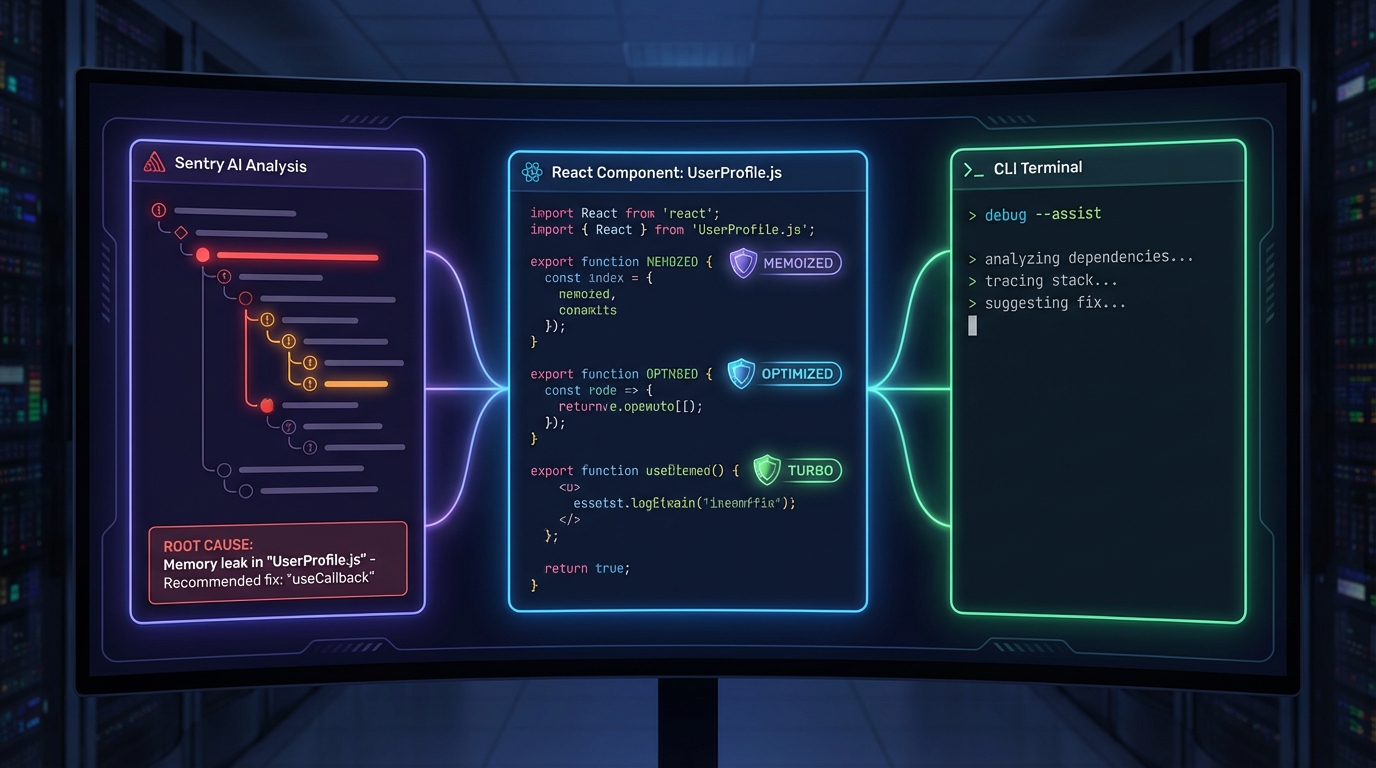
Sentry가 공식 MCP 서버(getsentry/sentry-mcp)를 내놓으면서 이 흐름이 바뀌기 시작했다. Cursor나 Claude Desktop 같은 AI 에디터에서 에이전트가 직접 Sentry 이슈를 조회하고, Seer(Sentry의 AI)를 호출해 근본 원인 분석까지 에디터 안에서 수행할 수 있다. 설치도 필요 없다. mcp.sentry.dev를 MCP 서버 URL로 등록하고 OAuth 2.0으로 브라우저 인증만 하면 끝이다. 토큰을 JSON 파일에 평문으로 저장하던 불안한 관행 대신, 스코프가 제한되고 언제든 폐기 가능한 OAuth 방식은 MCP 서버가 마땅히 따라야 할 표준을 제시한다.
약 20개의 도구가 조직·프로젝트 탐색부터 이슈 검색, 이벤트 분석, 세션 리플레이 조회까지 촘촘하게 커버한다. 특히 get_issue_analysis를 통해 Seer를 호출하면 스택 트레이스를 보여주는 데 그치지 않고 왜 에러가 발생했는지, 어떻게 고쳐야 하는지까지 제안한다. 새벽 2시 인시던트 대응에서 이 차이는 꽤 크다.
하지만 MCP 서버에는 숨겨진 비용이 있다
여기서 한 가지 불편한 진실을 직면해야 한다. MCP 서버를 연결할수록 컨텍스트 윈도우가 잠식된다. Apideck 팀이 공개한 분석에 따르면, GitHub·Slack·Sentry 세 개의 MCP 서버를 연결하면 에이전트가 첫 메시지를 읽기도 전에 55,000토큰 이상이 도구 정의(tool definitions)로 소모된다. Claude의 200k 컨텍스트 기준으로 28% 이상이 날아가는 셈이다.
더 극단적인 사례도 있다. 한 팀은 MCP 서버 세 개가 200,000토큰 중 143,000토큰을 잡아먹어 실제 대화와 추론에 쓸 수 있는 공간이 57,000토큰밖에 남지 않았다고 보고했다. Scalekit의 벤치마크는 같은 작업을 MCP와 CLI로 각각 수행했을 때 토큰 비용이 4~32배 차이 난다는 걸 실측으로 보여줬다. 저장소의 사용 언어를 조회하는 단순 작업 하나가 CLI로는 1,365토큰인데 MCP로는 44,026토큰이었다. 차이의 대부분은 매 대화마다 맥락에 주입되는 43개의 도구 스키마다.
이 문제에 대한 업계의 대응은 크게 세 방향이다. 스키마 압축 및 동적 로딩(MCP를 유지하면서 필요할 때만 도구 정의를 불러오는 미들웨어 구축), 코드 실행 방식(에이전트가 SDK 문서를 읽고 직접 코드를 작성해 실행하는 Duet의 접근법), 그리고 CLI 인터페이스다. 세 번째 방식이 가장 실용적인 균형점이다. CLI는 본질적으로 점진적 공개(progressive disclosure) 시스템이다. --help 플래그를 통해 에이전트가 필요한 시점에 필요한 정보만 80~200토큰씩 가져온다. Apideck CLI의 에이전트 시스템 프롬프트 전체가 약 80토큰인 것과 MCP가 같은 API 표면을 10,000토큰 이상으로 설명하는 것의 차이는, 개발자가 API 레퍼런스 전체를 암기하는 것과 --help를 필요할 때 치는 것의 차이와 정확히 같다.
React Compiler가 조용히 코드를 바꾸고 있을 때
IDE 안에서의 AI 워크플로우 이야기를 하면서 React Compiler를 빼놓을 수 없다. 컴파일러는 자동 메모이제이션을 통해 useMemo와 useCallback을 직접 관리하던 부담을 덜어주는 것이 목표다. 하지만 그 과정에서 예기치 않은 런타임 이슈가 생기는 경우가 있다.
핵심 문제는 메모이제이션 의존성의 충돌이다. 개발자가 "이 객체는 반드시 동일한 참조를 유지해야 한다"고 가정하고 코드를 짰는데, 컴파일러가 다른 방식으로 최적화하면 useEffect가 의도치 않게 재실행되거나 무한 루프가 발생할 수 있다. React Compiler는 안전하지 않다고 판단하면 최적화를 건너뛰는 보수적 전략을 택하지만, 그 판단이 빗나가는 경우가 바로 런타임 이슈로 나타난다.
디버깅 워크플로우는 이렇다. 의심 컴포넌트에 "use no memo" 디렉티브를 추가해 컴파일러 최적화를 일시적으로 제외한다. 이슈가 사라지면 컴파일러와 관련된 문제이고, 그래도 남아 있으면 원래 코드에 React 규칙 위반이 있는 것이다. 다음 단계는 수동 메모이제이션(useMemo, useCallback, memo)을 전부 제거해보는 것이다. 메모이제이션 없이도 버그가 재현된다면 컴파일러가 문제가 아니라 코드 자체가 문제다. React DevTools에서 최적화된 컴포넌트에 표시되는 ✨ 배지는 컴파일러가 정상 작동 중이라는 시각적 신호로 활용할 수 있다.
이 디버깅 흐름에서 AI 에이전트의 역할이 자연스럽게 생긴다. 컴포넌트 단위로 "use no memo" 범위를 좁혀가는 이진 탐색 과정, ESLint가 잡지 못한 미묘한 규칙 위반 패턴 탐지, 최소 재현 예제 작성—이 모든 단계가 에디터 안에서 에이전트와 협업할 수 있는 구조적 작업이다.
워크플로우 재설계의 방향
세 가지 흐름이 가리키는 방향은 하나다. IDE가 단순한 편집기에서 디버깅·최적화·관찰의 허브로 진화하고 있다. Sentry MCP는 프로덕션 에러를 에디터로 끌어들이고, CLI 기반 토큰 최적화 전략은 에이전트의 추론 공간을 확보하며, React Compiler 디버깅 패턴은 컴파일 타임 최적화와 런타임 동작 사이의 간극을 에디터 안에서 좁히는 방법을 제시한다.
실무적으로 취할 수 있는 즉각적인 행동은 명확하다. Sentry를 이미 쓰고 있다면 mcp.sentry.dev를 에디터에 연결하는 데 5분이면 충분하다. MCP 서버를 여러 개 연결하고 있다면 컨텍스트 비용을 측정해보자. 컨텍스트의 절반 이상이 도구 스키마에 잠식되고 있다면 CLI 기반 인터페이스로의 전환을 검토할 시점이다. React Compiler를 도입했거나 도입 예정이라면 "use no memo" 디버깅 패턴을 팀의 표준 트러블슈팅 절차에 포함시켜두는 것이 낫다.
물론 아직은 거친 부분이 있다. Sentry MCP는 748개 이상의 GitHub 이슈가 쌓여 있는 v0.29.0이고, 크로스 프로젝트 쿼리는 여전히 제한적이다. MCP의 컨텍스트 문제에 대한 표준 해법도 아직 수렴 중이다. React Compiler 역시 커뮤니티가 엣지 케이스를 함께 발굴하는 단계다. 하지만 방향은 분명하다. 에디터 밖으로 나가야 했던 모든 순간들이 하나씩 에디터 안으로 흡수되고 있다. 지금은 그 전환의 초입이다.