데모는 된다. 그런데 팀에 붙이면 왜 무너지나
Claude Code 세션을 3~4개 띄워놓고 작업하다 보면 반드시 벽이 온다. 터미널 탭은 전부 'claude'라는 이름이고, 어느 탭이 프론트엔드 담당인지 기억에 의존해야 한다. 브라우저를 닫으면 컨텍스트가 증발하고, 토큰 한도를 넘으면 에이전트가 조용히 멈춘다. 이건 특정 도구의 버그가 아니라 멀티 에이전트 운영을 '세션 여러 개 열기'로 접근할 때 필연적으로 만나는 구조적 마찰이다.
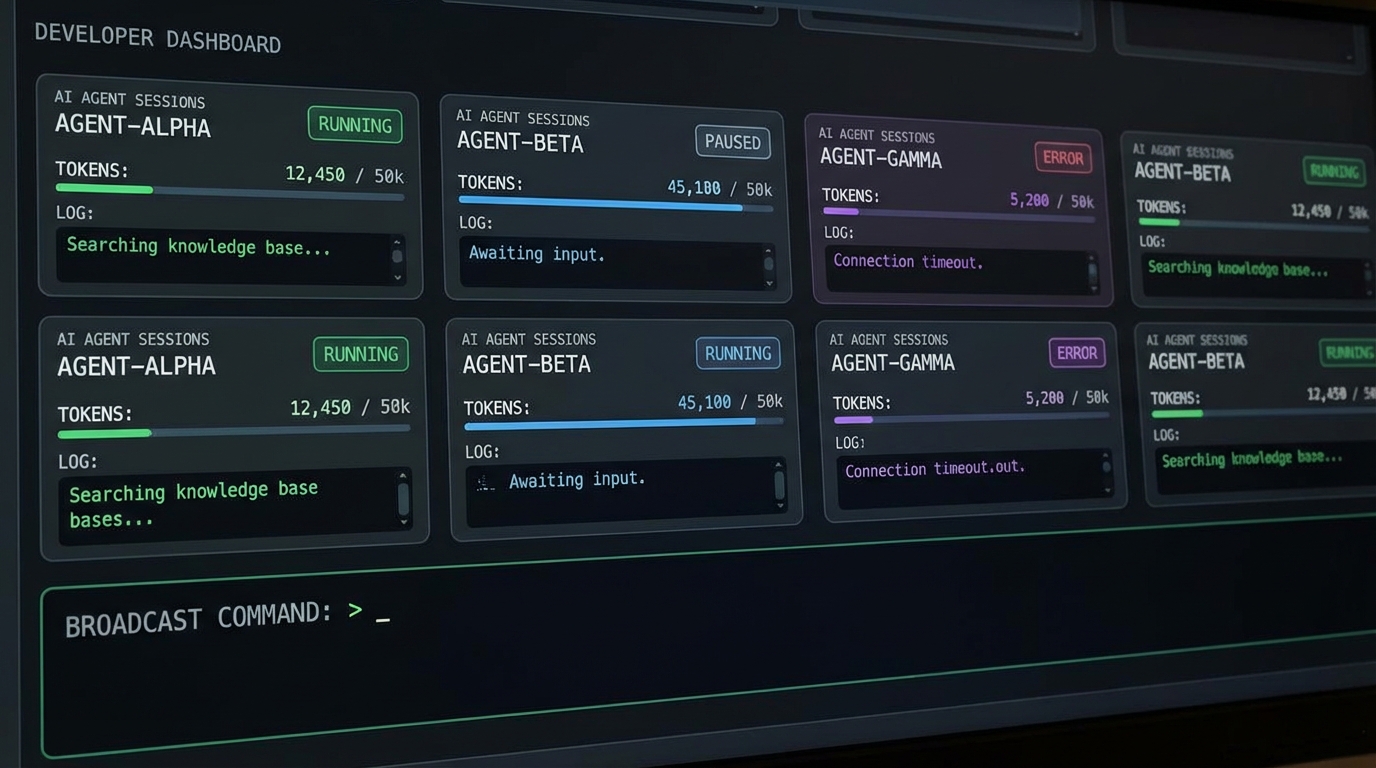
그 마찰을 직접 해결하려고 나온 사례가 velog에 공개된 Claude Cockpit이다. 개발자가 세션 5~6개를 동시에 굴리다 답답함이 쌓여 직접 만든 웹 대시보드로, 브라우저(xterm.js) → WebSocket → PTY → tmux → Claude CLI로 이어지는 최소한의 스택 위에 실용적인 기능을 얹었다. 사이드바에서 세션에 이름과 디렉토리를 붙이고, 그룹으로 묶어 브로드캐스트 명령을 한 번에 보내고, 토큰 사용량을 헤더 배지로 10초마다 갱신하고, Rate Limit 메시지를 감지해 카운트다운 후 자동 재전송한다. '완성된 제품'이 아니라 '불편함을 참다가 만든 도구'라는 점이 오히려 이 도구의 신뢰도를 높인다. 현장에서 실제로 발생하는 마찰 지점들이 기능 목록 그대로 녹아 있기 때문이다.
에이전트가 데모 이후에 실패하는 진짜 이유
dev.to에 올라온 글 Why Most AI Agents Fail After the Demo는 이 현상을 네 가지로 압축한다. 모호한 지시, 툴 장애, 긴 추론 체인의 오류 누적, 컨텍스트 한도 초과. 공통점은 하나다—데모는 통제된 환경이고, 프로덕션은 그렇지 않다는 것. 에이전트가 데모에서 인상적으로 보이는 이유는 입력이 정제되어 있고, API는 안정적이며, 작업이 짧기 때문이다. 팀 워크플로우에 붙이는 순간 그 세 가지 전제가 동시에 무너진다.
해당 글이 제안하는 처방은 '완전한 자율성'을 포기하고 가드레일과 체크포인트를 설계하는 것이다. 작업을 검증 가능한 작은 단위로 쪼개고, 툴 접근을 제한하고, 불확실성이 높을 때는 사람에게 되돌리는 구조. 프로덕션에서 에이전트에게 필요한 덕목은 '얼마나 영리한가'가 아니라 '언제 멈춰야 하는지 아는가'다.
프로세스로 제어하는 에이전트 하네스
GeekNews에서 소개된 oh-my-agent는 이 철학을 프레임워크 수준으로 구조화한 시도다. 핵심 아이디어는 에이전트 문제를 '프롬프트 한 줄'이 아니라 '프로세스'로 푼다는 것. 가장 눈에 띄는 메커니즘은 Clarification Debt(CD) 스코어링이다. 에이전트가 요구사항을 오해하거나 범위를 벗어나면 점수가 쌓인다—단순 확인 질문은 +10, 의도 오해로 방향을 바꾸면 +25, 범위 이탈로 롤백 후 재시작하면 +40. 50점을 넘으면 Root Cause Analysis 작성이 강제되고, 80점을 넘으면 세션이 중단된다. 여기서 나온 교훈은 lessons-learned.md에 누적되어 다음 세션부터 자동으로 반영된다.
Clarification Protocol도 실용적이다. 요구사항 모호도를 LOW/MEDIUM/HIGH로 분류해 LOW면 바로 진행, MEDIUM이면 선택지 제시, HIGH면 작업을 멈추고 명확화를 요청한다. /coordinate(속도 우선, 7단계 루프)와 /ultrawork(품질 우선, 17단계 중 11단계가 리뷰) 두 가지 오케스트레이션 모드를 두고 상황에 따라 선택한다. .agents/ 디렉토리를 SSOT로 삼아 특정 IDE에 종속되지 않고 Claude Code, Cursor, Codex CLI 등을 모두 지원한다.
테크 리드가 챙겨야 할 실전 시사점
세 글감을 같이 읽으면 하나의 메시지로 수렴한다. 멀티 에이전트는 '몇 개 띄우냐'의 문제가 아니라 '어떻게 관찰하고 개입하냐'의 문제다.
첫째, 가시성부터 확보해야 한다. Claude Cockpit이 보여주는 것처럼, 세션 상태·토큰 소모·마지막 활동 시각을 한 화면에서 볼 수 없으면 에이전트가 무엇을 하고 있는지 파악 자체가 안 된다. 관찰 불가능한 에이전트는 운영할 수 없다.
둘째, 자율성의 범위를 명시적으로 제한해야 한다. oh-my-agent의 CD 스코어링이나 dev.to 글의 체크포인트 설계 모두 같은 원칙을 가리킨다. 에이전트가 '알아서 잘 하겠지'라는 가정 위에서 팀 워크플로우를 설계하면 예외 처리 비용이 전부 사람에게 돌아온다.
셋째, 실패 로그를 자산으로 만들어야 한다. lessons-learned.md처럼 에이전트의 오판 패턴을 누적하고 다음 세션에 반영하는 구조가 없으면, 같은 실수를 매번 처음 겪는 팀이 된다. 에이전트는 학습하지 않는다. 학습 루프를 설계하는 건 팀의 몫이다.
전망: 오케스트레이션 레이어가 다음 전쟁터다
개별 AI 코딩 에이전트의 능력은 이제 어느 정도 수렴하고 있다. 다음 차별화 지점은 여러 에이전트를 어떻게 조율하고, 실패를 어떻게 감지하고, 인간의 개입 지점을 어디에 설계하느냐다. Claude Cockpit 같은 관찰 도구, oh-my-agent 같은 하네스 프레임워크, 그리고 가드레일 설계 원칙이 함께 팀 인프라로 굳어지는 시기가 빠르게 다가오고 있다.
지금 당장 할 수 있는 가장 현실적인 첫 걸음은 단순하다. 팀에서 Claude 세션을 가장 많이 쓰는 사람에게 "지금 가장 불편한 게 뭐야?"라고 물어보는 것. 그 답이 곧 팀 에이전트 인프라의 설계 출발점이다.