AI 에이전트/LLM 제품의 단위경제는 CAC보다 먼저 COGS(추론비용)에서 흔들립니다. 문제는 대부분의 팀이 “모델을 더 싸게”가 아니라 “작업을 어디로 보낼지(라우팅)”와 “RAG가 프로덕션에서 깨지는 방식” 때문에 10배 단가를 자발적으로 지불한다는 점입니다. dev.to의 두 글이 그 구조를 데이터와 운영 경험으로 찌릅니다.
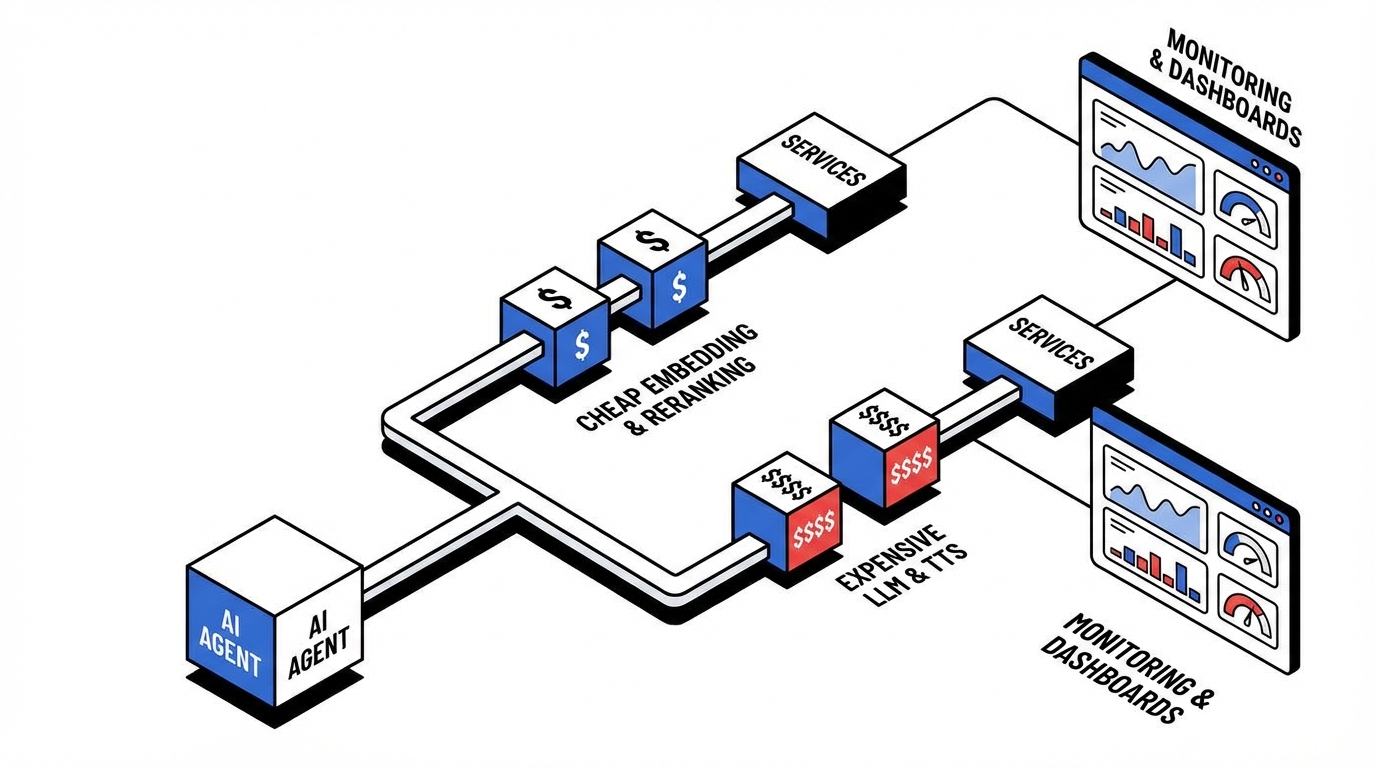
첫 번째 소스(‘70/30 Rule’)의 핵심은 간단합니다. 실제 워크로드의 70%는 분류·필터링·변환처럼 ‘추론’이 아니라 ‘판별’에 가깝고, 이건 임베딩/리랭킹 같은 저비용 티어로도 충분합니다. 그런데 에이전트는 관성적으로 그 70%까지 LLM로 밀어 넣어, 콜당 100~1000배 비싼 경로를 타게 됩니다(출처: dev.to/gpubridge).
왜 이런 과지출이 생기냐? (1) GPT-4 망치 문제: 모든 입력을 “생각해야 할 문제”로 착각합니다. (2) 모니터링 세금: 헬스체크/하트비트 같은 ‘가치 낮은 호출’에 LLM을 쓰면 고정비가 폭발합니다. (3) 콜드스타트 회피를 핑으로 해결하면서도, 그 핑이 비싼 모델이면 역효과입니다. (4) 결정타는 Cost Observability 부재—월말 청구서만 보고 태스크별 원가를 모릅니다.
해법은 ‘티어드 라우팅’입니다. 요청을 한 번 임베딩으로 스코어링해(결정 비용은 거의 0에 수렴), 유사도가 높으면 저가 티어(임베딩/리랭크/OCR/필터)로, 아니면 고가 티어(LLM 생성/추론)로 보냅니다. 소스는 1,000콜/일 기준 월 $90 → $27까지 떨어지는 수치를 제시합니다(출처: dev.to/gpubridge). 성장 관점에서 이건 “비용 절감”이 아니라 ‘가격 실험 상한선’과 ‘무료 플랜 여지’를 여는 레버입니다.
두 번째 소스는 “RAG는 주말에 만들고, 프로덕션은 몇 주를 태운다”는 현실을 설명합니다. 가장 큰 레버는 청킹입니다. 도메인 구조를 무시한 500토큰 분할은 코드/법률/로그에서 의미를 찢어 retrieval을 망가뜨립니다. 그리고 더 무서운 건, retrieval 품질은 조용히 망가지며(Looking plausible), LLM이 자신 있게 거짓을 합성한다는 점입니다(출처: dev.to/diven_rastdus…).
RAG가 깨지면 COGS는 어떻게 오르냐? 첫째, 잘못된 컨텍스트로 재시도/재질문이 증가해 쿼리 수가 불어납니다. 둘째, “그냥 많이 넣자”로 컨텍스트 윈도우를 키워 입력 토큰이 폭발합니다(비용·지연 동시 증가). 셋째, 임베딩 모델 버전 드리프트로 인덱스가 ‘다른 벡터 공간’이 되면, 정확도 하락→재시도→지원 티켓까지 이어집니다. 즉 RAG 품질은 곧 COGS와 리텐션을 같이 때립니다.
여기서 실행 과제는 기술 최적화가 아니라 ‘실험/트래킹’으로 번역돼야 합니다. 당장 할 일 4가지: (1) 태스크 타입 라벨링: 전체 호출을 분류/검색/추론/생성/모니터링으로 쪼개고, 각 타입별 Cost-per-success를 이벤트로 남기세요. (2) 라우팅 A/B: “임베딩 프리필터→저가 티어” 비율을 30%→50%→70%로 단계적으로 올리며, 정답률/재시도율/전환율을 같이 봅니다. (3) RAG CI 평가셋(50~100문항) 구축: 인덱스 재빌드/청킹 변경/임베딩 버전 변경 시 recall이 떨어지면 배포를 막습니다. (4) 컨텍스트 예산제: top-20 retrieve 후 top-5만 컨텍스트에 넣는 식으로 ‘입력 토큰 상한’을 강제하고, p95 지연과 함께 대시보드화하세요.
국내에서도 음성 에이전트가 빠르게 상용화되는 흐름(매트릭스클라우드의 AI콜/보이스 에이전트 출시, 전자신문 보도)은 이 이슈를 더 날카롭게 만듭니다. 음성은 TTS/ASR까지 붙어 콜당 원가가 커지고, 인바운드/아웃바운드는 모니터링·상태체크·세션 유지로 ‘가치 낮은 호출’이 많습니다. 그래서 라우팅과 관측 가능성 없이는, “잘 대화하는 데모”가 “적자나는 프로덕션”으로 직행합니다.
전망은 분명합니다. 앞으로의 경쟁력은 ‘가장 똑똑한 모델’이 아니라, (1) 싸게 판단하고(프리필터), (2) 정확히 가져오며(RAG 품질), (3) 태스크별 원가를 계측해(코스트 옵저버빌리티), (4) 그 결과를 가격/패키징/퍼널 실험으로 연결하는 팀이 가져갑니다. 에이전트 COGS 절감은 인프라 최적화가 아니라, 성장 지표를 회복시키는 운영 능력의 싸움입니다.