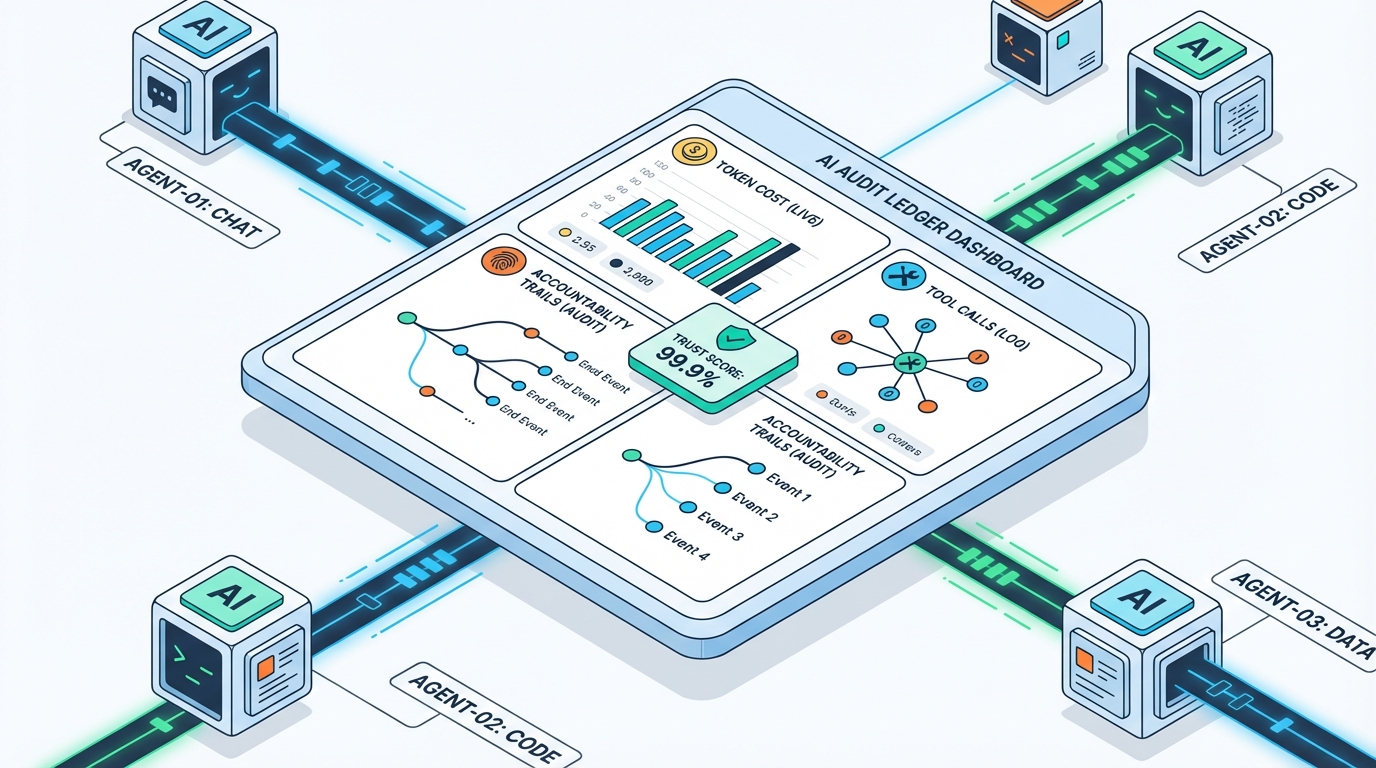
프로덕션에서 AI 에이전트가 ‘잘 돌아간다’는 말은 대개 위험한 착각입니다. 출력이 멀쩡해 보이는 동안 토큰/툴 호출 비용이 조용히 새고(COGS↑), 멀티에이전트가 얽히면 “누가 무엇을 했는지”가 흐려져 환불·지원티켓·이탈이 늘어납니다. 결국 성장의 상한선은 기능이 아니라 운영 단위경제와 신뢰(감사·책임추적)가 결정합니다.
dev.to의 Gary Botlington 글(“AI가 AI를 감사했더니”)이 날카로운 지점을 찌릅니다. 문제는 ‘못 만들었기 때문’이 아니라 ‘감사하지 않기 때문’입니다. 새벽에 맞춘 설정이 그대로 크론 잡으로 굴러가며 GPT-4급 모델이 이메일 제목에 “unsubscribe” 있는지 확인하는 데 쓰이고, MEMORY/TOOLS 문서를 매번 통째로 로드해 토큰을 태웁니다. 결과는 정상이니 아무도 모릅니다—토큰 장부를 열기 전까지.
이 글이 제시한 비용 누수 패턴은 성장 관점에서 바로 “마진을 잠식하는 숨은 CAC”입니다. (1) 기계적 작업에 고급 모델을 쓰는 ‘모델 미스매치’, (2) 전부 넣고 보자는 ‘컨텍스트 비만’, (3) 쓰지도 않을 툴 정의를 싣는 ‘툴 로딩 세금’, (4) seen-state 부재로 같은 일을 반복하는 ‘중복 실행’, (5) API 대신 브라우저 자동화로 태우는 ‘토큰 폭탄’. 흥미로운 건, 이 낭비가 UX 문제로 드러나지 않는다는 점입니다. 그래서 더 위험합니다.
여기서 신뢰 이슈가 결합됩니다. 또 다른 dev.to 글(“멀티 에이전트의 책임 레이어 부재”)은 멀티에이전트의 #1 실패 모드로 ‘공유 상태의 조용한 덮어쓰기’를 지목합니다. A가 v2를 썼는데 B가 v1 기반으로 덮어써도 에러가 안 나고, 그 결과는 “아무도 책임지지 않는 실패”가 됩니다. 이건 단순 버그가 아니라 운영 비용으로 환산됩니다: 재시도 토큰, 장애 대응 인력, 고객 CS, 신뢰 하락에 따른 전환율/리텐션 하락.
시사점은 명확합니다. 에이전트 운영은 이제 “성능 최적화”가 아니라 “단위경제+감사 가능성 최적화”입니다. 우선순위는 기능 추가가 아니라 계측입니다. 잡/스텝 단위로 토큰·툴콜·재시도·브라우저 세션·컨텍스트 로드량을 태깅하고, 작업 유형별로 모델 티어를 라우팅해야 합니다(예: 경량 모델=룩업/포맷, 상위 모델=판단/합성). 동시에 책임 레이어를 깔아야 합니다: propose→validate→commit 같은 원자적 상태 업데이트, 권한 게이팅, 모든 툴 호출/상태 변경의 감사 로그. “누가(어떤 에이전트가) 어떤 근거로 무엇을 바꿨는지”가 조회 가능해야 환불과 분쟁을 줄일 수 있습니다.
전망: 2026년형 프로덕션 에이전트 경쟁력은 더 똑똑한 프롬프트가 아니라 ‘운영 규율’에서 갈립니다. 비용은 라우팅·컨텍스트·툴 표면적·중복 실행에서 계속 새고, 신뢰는 상태 조정·권한·감사 추적이 없으면 반드시 무너집니다. 팀이 해야 할 다음 단계는 간단합니다. (1) 2주만이라도 토큰 장부를 잡 단위로 쪼개 공개하고, (2) 상위 20% 비용 잡부터 모델/컨텍스트/툴을 다이어트하며, (3) 멀티에이전트에는 원자적 커밋과 감사 로그를 ‘기능’이 아니라 ‘성장 인프라’로 붙이세요. COGS를 내리면 가격·무료플랜·온보딩 실험의 레버리지가 커지고, 책임 레이어를 깔면 CS/환불/이탈이 줄어 전환과 리텐션이 동시에 올라갑니다.