화학자가 70일 만에 10만 줄짜리 C# 멀티플레이어 게임을 혼자 완성했다. 코딩 경력도, 전문 개발 팀도 없이. 이 이야기가 흥미로운 건 AI가 대단해서가 아니다. 그가 AI에게 무엇을 어떻게 먹였느냐가 핵심이다.
dev.to에 공개된 'Codified Context' 사례(arXiv:2602.20478)에 따르면, Aristidis Vasilopoulos는 Claude Code만으로 108,256줄, 405개 파일, 283회 세션을 소화했다. 주목할 숫자는 따로 있다. 코드 대비 컨텍스트 문서 비율이 24.2%였다는 것. 코드 4줄을 쓸 때마다 컨텍스트 1줄이 따라붙었다. 이건 부산물이 아니라 설계 철학이다.
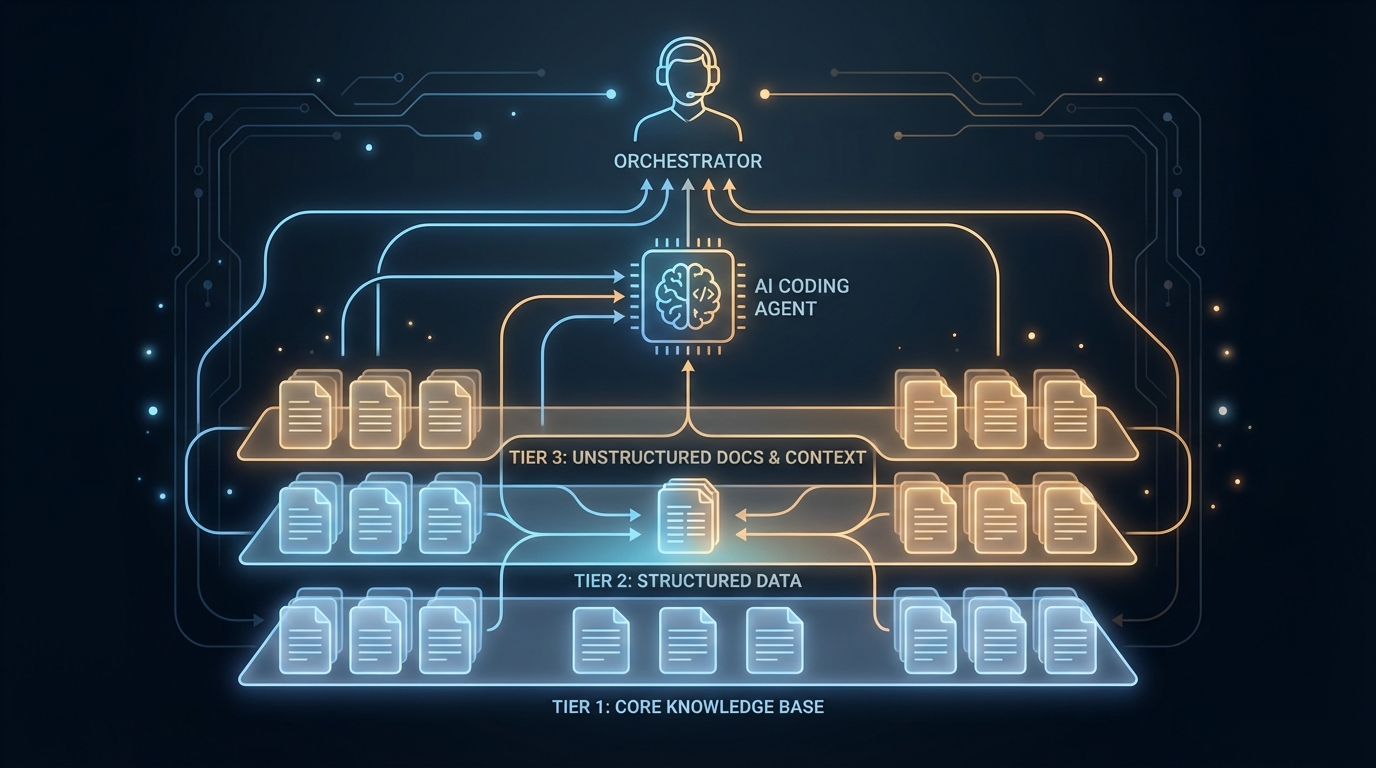
3계층 컨텍스트 아키텍처: 핫 메모리, 트리거, 콜드 서치
AI 코딩 에이전트의 근본적 약점은 세션이 끝나면 모든 걸 잊는다는 것이다. CLAUDE.md 하나에 프로젝트 규칙을 몰아넣는 방식은 253개 파일 분석 결과 10만 줄 규모에서 한계를 드러냈다. Codified Context가 제안하는 해법은 지식을 접근 빈도에 따라 3계층으로 분리하는 것이다.
Tier 1 (헌법): 약 660줄 분량의 마크다운 파일 하나. 코딩 표준, 빌드 커맨드, 트리거 테이블이 담긴다. 매 세션 시작 시 자동 로드되는 '핫 메모리'다. 에이전트가 코드 한 줄 쓰기 전에 반드시 알아야 할 것들만 여기 있다.
Tier 2 (전문 에이전트 스펙): 19개 도메인별 에이전트 스펙, 총 9,300줄. 트리거 테이블이 라우팅을 제어한다. 네트워크 동기화 파일을 수정하면 network-protocol-designer 에이전트가 자동 호출된다. 에이전트가 어떤 지식이 필요한지 스스로 판단하는 게 아니라, 설계자가 미리 정의해둔 맥락이 에이전트를 찾아온다.
Tier 3 (지식 베이스): 34개 스펙 문서, 16,250줄. MCP 서버를 통해 온디맨드로 검색된다. 필요할 때만 컨텍스트 윈도우에 올라오는 '콜드 메모리'다.
이 구조가 해결하는 건 컨텍스트 윈도우의 근본적 딜레마다. 전부 올리면 넘치고, 아무것도 안 올리면 에이전트가 길을 잃는다. 세이브 시스템 스펙(283줄)은 74회 세션에 걸쳐 정제됐고, 결과는 세이브 관련 버그 제로였다. 과거 실수와 올바른 패턴이 스펙에 누적됐기 때문에 에이전트는 같은 실수를 반복하지 않았다.
멀티 에이전트 역할 분리: 모자가 다르면 보이는 것도 다르다
Geeknews에서 공유된 멀티 에이전트 워크플로우 사례는 컨텍스트 설계에 또 다른 레이어를 더한다. 이 개발자는 아키텍트→개발자→리뷰어 3단계 워크플로우를 OpenCode 에이전트로 구성했다. 핵심 인사이트는 단순하다. 같은 모델에게 자기 코드를 리뷰시키면 거의 무의미하다. 모델은 컨텍스트를 초기화해도 같은 의견과 약점을 유지하는 경향이 있기 때문이다.
실전 구성은 이렇다. Claude Opus 4.6는 아키텍트로, 계획 수립과 트레이드오프 결정을 담당한다. 더 저렴한 Sonnet 4.6는 개발자로, 재량의 여지가 최소화된 계획을 구현한다. Codex 5.4는 리뷰어로, 꼼꼼하고 까다롭게 diff를 검토한다. 비싼 모델은 판단에, 저렴한 모델은 실행에 투입하는 토큰 효율까지 잡는다.
이 워크플로우에서 인간의 역할도 재정의된다. 아키텍트 에이전트에게 '승인(approved)'이라는 단어를 명시적으로 말하기 전까지는 구현을 시작하지 않도록 설정해뒀다. 계획 단계에서 최대 30분을 쏟고, 목표·제약·트레이드오프를 확정한다. 코드를 직접 읽지 않아도 아키텍처와 내부 동작을 이해하는 것, 이것이 AI 시대 개발자의 진짜 기여다.
AI 코드 리뷰 자동화: 전문가 vs 올인원
파이프라인의 마지막 레이어, 코드 리뷰 자동화에서는 선택의 문제가 남는다. dev.to의 CodeRabbit vs GitHub Copilot 비교 분석(2026)에 따르면, 2026년 현재 두 도구는 근본적으로 다른 철학을 취하고 있다.
CodeRabbit은 PR 리뷰 전문가다. 전체 레포 컨텍스트 분석, 40개 이상의 빌트인 린터, 팀 피드백에서 학습하는 적응형 선호도 시스템을 갖췄다. 1,300만 개 이상의 PR을 리뷰한 실적도 있다. GitHub, GitLab, Azure DevOps, Bitbucket을 모두 지원한다는 점은 GitHub 외 플랫폼을 쓰는 팀에게는 사실상 선택지가 없다는 의미다.
GitHub Copilot은 코드 완성·채팅·에이전트·리뷰를 하나의 구독으로 묶은 올인원이다. 2026년 3월 에이전틱 아키텍처 개편으로 리뷰 품질이 크게 향상됐고, $10/월부터 시작하는 가격은 압도적이다. 단, 코드 리뷰는 여전히 여러 기능 중 하나다.
팀 리드 입장에서 선택 기준은 명확하다. 리뷰 품질이 최우선이고 멀티 플랫폼을 써야 한다면 CodeRabbit, GitHub 생태계 안에서 올인원 효율을 원한다면 Copilot. 다만 어느 쪽이든, AI 리뷰어가 '올바른 지침'을 얼마나 잘 받느냐에 결과가 달려있다. .coderabbit.yaml이든 copilot-instructions.md든, 결국 컨텍스트 설계의 문제로 다시 돌아온다.
시사점: 컨텍스트는 인프라다
세 사례를 관통하는 공통 원리가 있다. AI에게 같은 걸 두 번 설명했다면, 그건 이미 스펙 문서가 됐어야 한다. Codified Context의 결론이기도 하고, 멀티 에이전트 워크플로우의 스킬 파일이기도 하고, CodeRabbit의 커스텀 리뷰 인스트럭션이기도 하다.
컨텍스트 설계는 이제 팀의 기술 부채와 생산성을 결정하는 핵심 인프라다. 세션 관리 비용은 주당 1~2시간이었다. 그 비용으로 비개발자가 10만 줄 프로젝트를 세이브 버그 없이 완성했다. 스펙 문서를 쓰는 시간이 아깝다는 생각은 이제 버려야 한다.
현실적 경고도 붙여야 한다. Codified Context 연구는 단일 개발자, 단일 프로젝트의 관찰 보고서다. 컨텍스트 파일이 특정 조건에서 오히려 태스크 성공률을 낮춘다는 반대 연구도 존재한다. Claude Code, Cursor, GitHub Copilot이 각자 다른 컨텍스트 스코프와 파일 포맷을 지원하므로, 툴 종속성도 함께 설계해야 한다.
AI-First 팀 리빌딩의 다음 과제는 결국 여기다. 모델을 고르는 것보다 어떤 지식을 어떤 형태로 에이전트에게 전달할 것인가를 설계하는 능력. 컨텍스트 아키텍트가 팀에서 가장 중요한 역할이 되는 시대가 이미 시작됐다.