LLM/에이전트 제품의 병목은 대개 성능이 아니라 COGS(토큰 비용)입니다. 토큰비가 높으면 무료플랜을 박하게 만들고, 박한 무료플랜은 활성화(Activation)와 유료 전환(Conversion)을 같이 깎습니다. 즉 “모델 비용” 문제는 곧바로 “그로스” 문제입니다.
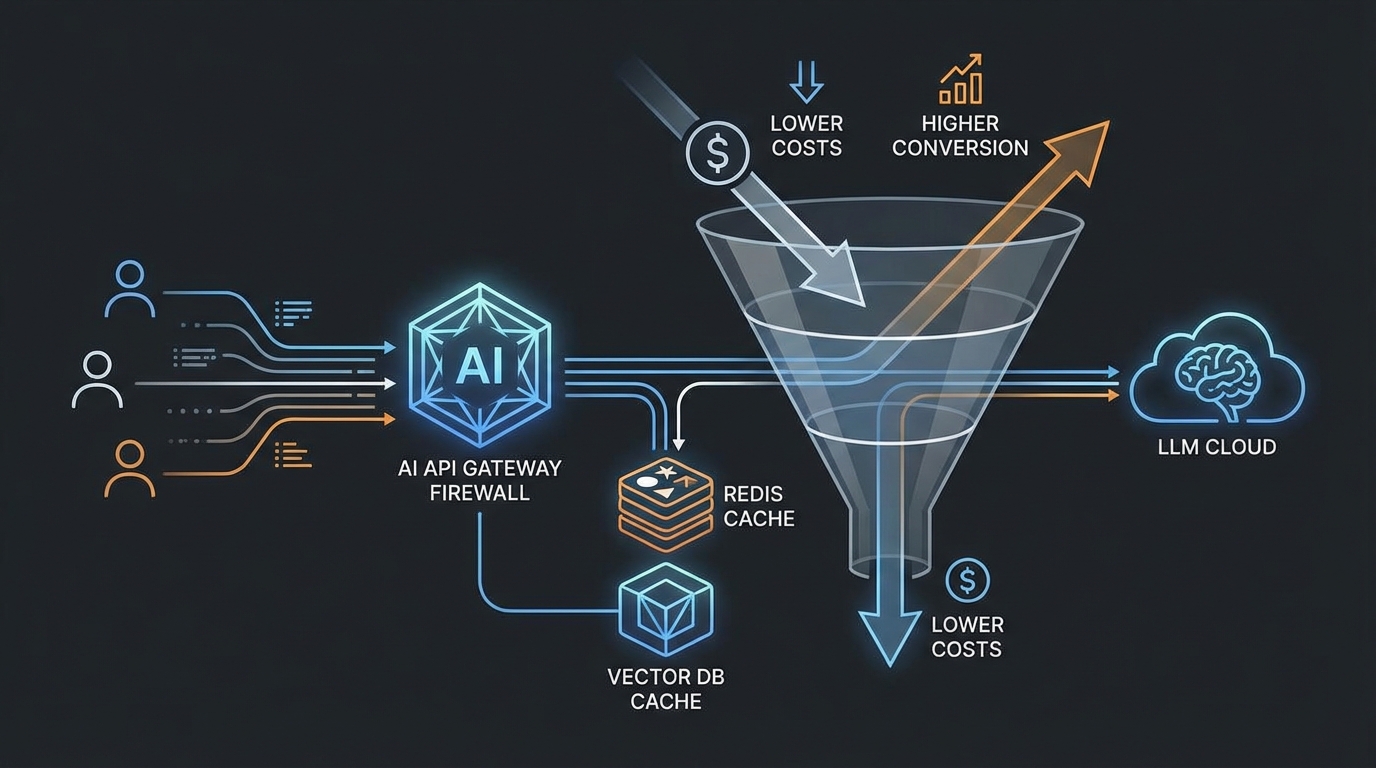
dev.to에 소개된 AI Cost Firewall은 이 연결고리를 끊는 꽤 실전적인 해법입니다. OpenAI 호환 API 앞단에 게이트웨이를 하나 세워, “진짜로 LLM 호출이 필요한 요청만” 업스트림으로 보내고 나머지는 캐시로 반환합니다. 기사에서는 이 방식으로 최대 75% 비용 절감을 주장하죠(출처: dev_to / vcalproject).
핵심은 캐시가 2겹이라는 점입니다. (1) Exact caching: 완전히 같은 요청은 Redis에서 즉시 응답. (2) Semantic caching: 문장이 달라도 의미가 비슷하면 Qdrant 벡터 검색으로 기존 답을 재사용. 고객센터/사내 지식봇처럼 질문이 반복되는 도메인에선, ‘새 질문’ 비율 자체가 낮아져 토큰 지출이 구조적으로 줄어듭니다.
그로스 관점에서 중요한 건 “비용 절감” 자체보다 실험 가능한 레버가 늘어나는 것입니다. 토큰비가 내려가면 곧바로 (a) 무료 사용량 상향, (b) 가격 구간 재설계, (c) 체험 중 기능 잠금 해제(usage-based trial) 같은 실험이 가능해집니다. CAC는 본질적으로 LTV로 회수해야 하는데, COGS가 낮아지면 마진이 늘고 회수 가능한 CAC 상한선이 올라갑니다. 같은 채널에서도 더 공격적으로 집행하거나, 더 넓은 타깃으로 확장할 여지가 생깁니다.
여기서 “기술이 성장으로 연결되는” 포인트는 통합 난이도입니다. AI Cost Firewall은 앱 코드 수정 없이 base_url만 바꾸는 형태(OpenAI 호환)라서, PM/그로스 팀이 엔지니어링 리소스 잠식 없이 빠르게 붙이고 측정할 수 있습니다. 또한 Prometheus/Grafana가 기본 내장이라 캐시 히트율, 포워딩 비율, 절감 추정치를 바로 대시보드로 봅니다. 비용 절감이 ‘감’이 아니라 ‘메트릭’이 됩니다.
즉시 돌릴 수 있는 실험 설계는 이렇게 잡을 수 있습니다. 1) 게이트웨이 적용 전후 토큰/세션, 응답지연, CSAT 비교 2) 캐시 히트율이 높은 세그먼트(예: FAQ 유입, 특정 템플릿 사용)에서 무료 한도 상향 A/B 3) 한도 상향분이 D1/D7 리텐션과 유료 전환율에 주는 순효과 측정 4) 히트율이 낮은 세그먼트는 프롬프트/온보딩을 조정해 “질문 분산”을 줄이고(템플릿/버튼/가이드), 캐싱 친화적으로 유도합니다.
한편, 모델 자체도 비용 구조를 바꾸고 있습니다. OpenAI의 GPT-5.4 ‘툴 서치’처럼 필요한 툴 정의만 동적으로 불러오면, 에이전트 프롬프트에 툴 스펙을 통째로 붙이는 낭비가 줄어들 수 있습니다(출처: AI 매터스/구글뉴스). 게이트웨이 캐싱(반복 호출 절감) + 툴 서치(프롬프트 비만 절감)는 서로 다른 레이어에서 COGS를 낮추는 조합입니다.
전망은 명확합니다. LLM 제품의 경쟁은 ‘더 똑똑한 모델’만이 아니라 더 싼 호출 구조로 이동합니다. 캐싱 게이트웨이는 단순 인프라처럼 보이지만, 실제론 가격·무료플랜·퍼널을 재설계할 수 있는 그로스 인프라입니다. 다음 단계는 캐시 TTL/유사도 임계값을 “정확도”가 아니라 전환·환불·재문의(지원 티켓)까지 포함한 유닛이코노믹스로 최적화하는 것. 비용을 깎아 만든 여유분을, 다시 전환율을 올리는 실험 연료로 태우는 팀이 이깁니다.