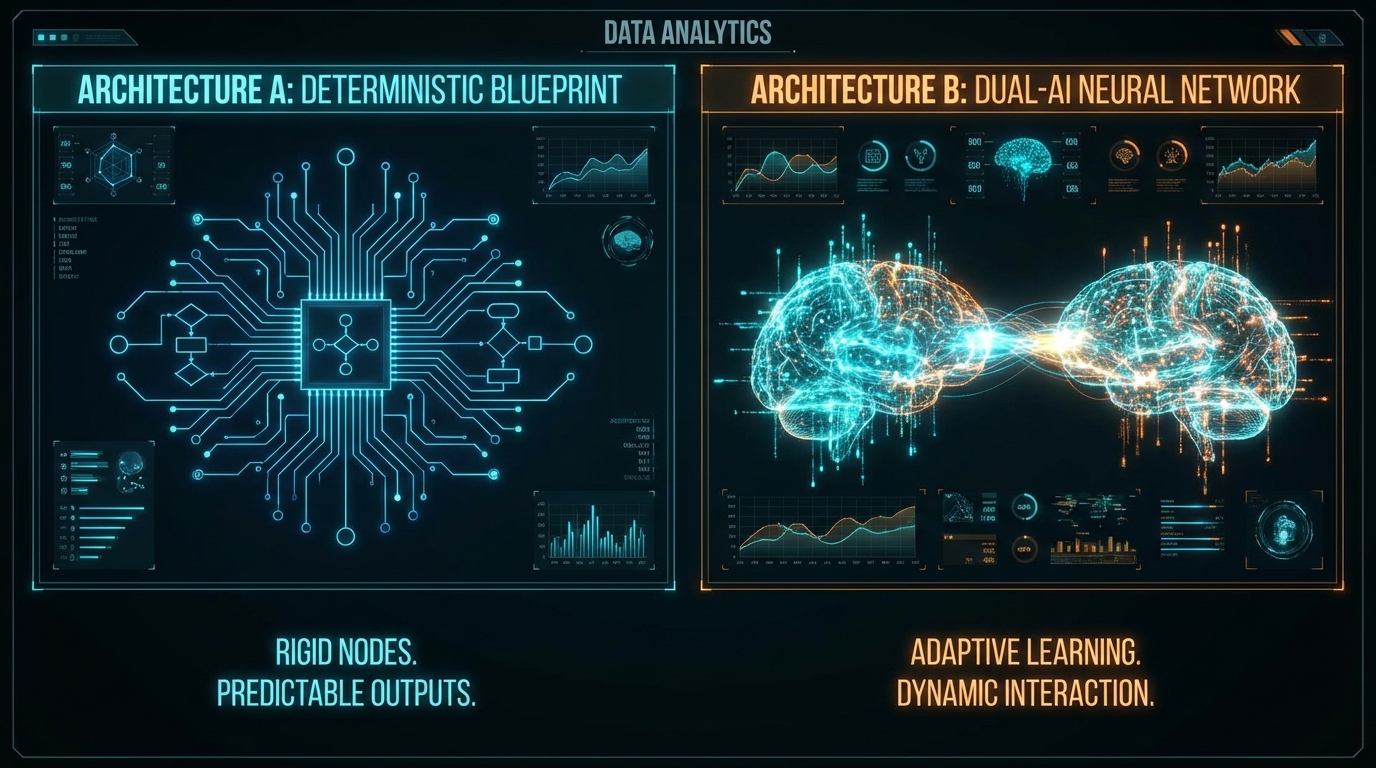
생성형 AI 에이전트를 프로덕션 환경에 배포할 때 가장 치명적인 병목은 '생성' 자체가 아니라, 출력의 품질을 검증하는 '평가(Evaluation)' 파이프라인에 있습니다. 최근 업계 표준처럼 자리 잡은 'LLM-as-Judge(다른 LLM을 판사로 활용하는 방식)' 아키텍처는 심각한 통계적 착시를 유발합니다. 두 LLM이 동일한 컨텍스트 결핍을 공유할 경우, 생성 모델의 할루시네이션을 평가 모델이 타당한 것으로 오판하여 승인하는 '상관적 할루시네이션(Correlated Hallucinations)' 현상이 발생하기 때문입니다. 이는 본질적으로 자동화된 고무도인(Rubber stamp)에 불과하며, 에이전트 시스템의 신뢰성 메트릭스를 근본적으로 오염시킵니다.
이러한 구조적 결함을 타파하기 위해 CDDBS 프로젝트는 LLM 호출 비용(Token Cost)이 '0'인 결정론적(Deterministic) 평가 아키텍처를 제시합니다. 이들은 10개 전문 정보기관의 데이터를 분석하여 구조적 완결성, 출처 품질, 신뢰도 표명(Confidence Signaling) 등 7차원 루브릭을 구축했습니다. 예를 들어, [PATTERN]과 같은 정규식(Regex) 기반의 증거 태그와 명시적 불확실성 표현 지표를 코드로 채점합니다. 이 접근법은 추론을 위한 LLM 호출이 배제되므로 평가에 소요되는 지연 시간이 밀리초(ms) 단위의 O(1) 시간 복잡도로 수렴하며, 생성 모델 특유의 '거짓 확신(False certainty)'을 완벽하게 필터링하여 P99 레이턴시 예산(Budget)을 전혀 갉아먹지 않는다는 압도적인 운영 효율성을 보여줍니다.
반면, 정규식과 구조적 채점만으로는 멀티 턴(Multi-turn) 대화에서 발생하는 의미적 표류(Semantic Drift)나 톤앤매너의 붕괴를 잡아낼 수 없습니다. Strands Agents SDK를 활용한 'Agent Buddy System' 기사는 프롬프트 엔지니어링의 한계를 정량적으로 지적합니다. 자체 실험 결과, 긴 컨텍스트 윈도우에서 단일 에이전트의 스타일 준수율은 세션 후반부에 25%까지 추락했지만, '평가자(Steering)' 에이전트가 개입해 출력을 가로채고(Intercept) 수정 지시(Guide)를 내린 파이프라인에서는 준수율이 100%로 유지되었습니다. 즉, 의미론적 평가 영역에서는 결정론적 룰이 커버할 수 없는 공백을 LLM-as-Judge 기반의 '스티어링(Steering)' 메커니즘이 해결할 수 있음을 입증합니다.
그러나 데이터 중심의 아키텍트 관점에서 LLM 기반 스티어링은 '비용과 지연 시간의 승수 효과'라는 치명적인 트레이드오프를 동반합니다. 재시도(Retry) 루프가 발생할 때마다 입력 토큰과 출력 토큰이 배수로 소모되며, 응답 지연 시간은 프로덕션 허용치를 쉽게 초과합니다. 따라서 실무적인 최적화 해답은 두 아키텍처의 '직렬화된 디커플링(Serialized Decoupling)'에 있습니다. 1차 평가 레이어(Layer 1)에 CDDBS 방식의 결정론적 룰 엔진을 배치하여 구조적 누락이나 출처 없는 주장을 0ms 지연 시간으로 즉각 기각(Fast-fail)시키고, 이를 통과한 결과물에 한해서만 2차 평가 레이어(Layer 2)인 Agent Buddy System을 호출해야 합니다. 동시에 무한 루프를 방지하기 위한 최대 재시도 횟수(max_retries) 기반의 서킷 브레이커(Circuit Breaker) 도입은 필수적입니다.
결론적으로, 프로덕션 등급의 AI 에이전트를 설계할 때 단일 평가 방법론에 의존하는 것은 엔지니어링 직무 유기에 가깝습니다. AgentOps 환경에서는 워크플로우의 실행 추적(Tracing) 시 생성 비용과 평가 비용을 분리하여 모니터링해야 합니다. 구조적 검증은 정량적 코드로, 의미적 검증은 LLM 판사로 이원화하는 하이브리드 라우팅 전략만이 에이전트의 토큰 비용(COGS)을 최소화하면서도 사용자 만족도(Human Evaluation)와 사실성(Factuality) 메트릭스를 동시에 달성할 수 있는 유일한 데이터 기반 최적화 경로입니다.