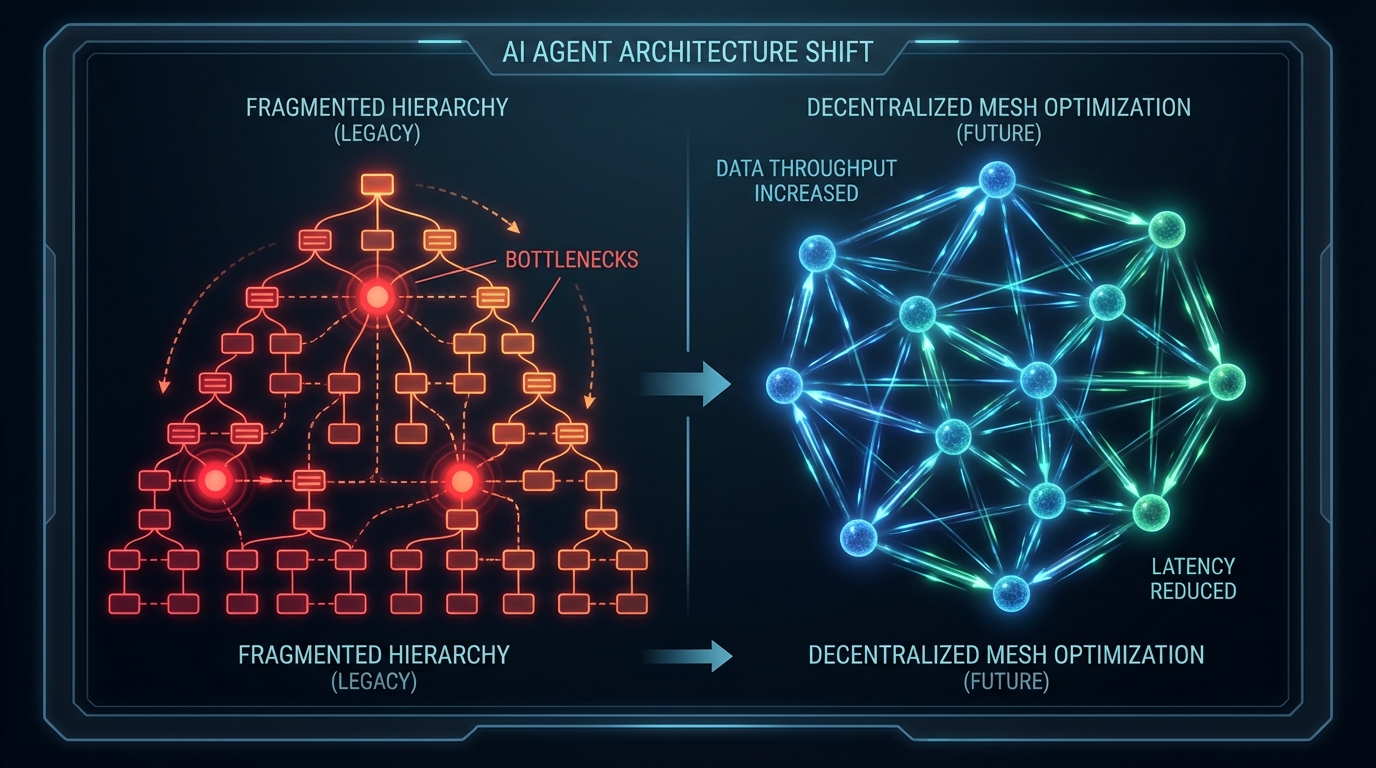
[핵심 이슈] 프로덕션 환경에서 생성형 AI(GenAI) 기반의 멀티 에이전트 시스템을 서빙할 때 맞닥뜨리는 가장 치명적인 병목은 모델의 추론 성능이 아닌 '아키텍처의 레거시'에서 발생한다. 최근 Dev.to에 공개된 두 건의 기술 분석 기사(Ameer Hamza의 Supervisor Pattern 분석, Gerus-team의 MSA 한계 지적)는 전통적인 마이크로서비스 아키텍처(MSA)와 중앙집중형 관리자(Supervisor) 패턴이 에이전트의 컨텍스트 윈도우 효율성을 어떻게 극적으로 훼손하는지 정량적으로 증명한다. AI 시스템의 추론 과정을 단순한 분산 API 호출의 연속으로 취급할 때, 파이프라인은 필연적으로 P99 지연 시간 폭발과 상태 불일치(State Inconsistency) 문제에 직면하게 된다.
[맥락 해석] 실제 프로덕션 데이터를 분석하면 이 트레이드오프는 더욱 명확해진다. Gerus-team의 시스템 벤치마크에 따르면, 에이전트 오케스트레이터를 기존 MSA 위에 단순 오버레이(Overlay)한 아키텍처의 평균 응답 시간은 1,200ms에 달했으며, 노드 간 비동기 통신 과정에서 렐러번트(Relevant) 컨텍스트의 약 40%가 유실되었다. 이러한 컨텍스트 단절은 불완전한 추론으로 이어져 에이전트의 환각(Hallucination) 비율을 18%까지 치솟게 만들었다. Ameer Hamza가 지적한 Supervisor 패턴의 한계도 동일한 궤를 달린다. 에이전트 A가 에이전트 B의 데이터를 필요로 할 때마다 중앙 매니저를 거치는 계층형 라우팅(A→Supervisor→B→Supervisor→A)은 네트워크 지연 시간의 스태킹(Stacking)을 유발할 뿐만 아니라, Supervisor 모델 자체에 '컨텍스트 팽창(Context Bloat)'을 초래하여 토큰 비용 곡선을 가파르게 상승시킨다.
[시사점] 비용-성능 트레이드오프를 최적화하기 위한 실무적 해법은 '에이전트 퍼스트(Agent-First)' 기반의 P2P(Peer-to-Peer) 핸드오프 패턴으로의 아키텍처 전환이다. 파편화된 서비스 환경에서 에이전트가 접근 권한을 기다리는 수동적 객체였다면, 최적화된 시스템에서는 에이전트가 단일한 영구 메모리(Vector DB)를 쥐고 툴(Tools) 레이어를 직접 오케스트레이션한다. 이 아키텍처 전환 후 평균 응답 시간은 340ms로 71% 단축되었고, 멀티스텝 워크플로우에서의 컨텍스트 유지율은 94%로 상승했으며, 환각 비율은 3%로 급감했다. 또한 LangGraph와 같은 프레임워크를 활용해 조건부 엣지(Conditional Edge) 기반의 결정론적 상태 전이(State Transition)를 구현하면 라우팅 과정의 불필요한 LLM 추론 비용을 완전히 제거할 수 있다. 단, 분산형 시스템의 치명적 리스크인 무한 재시도 루프를 방지하기 위해 AgentState 내부에 글로벌 step_count (TTL)를 주입하는 서킷 브레이커 로직은 필수적으로 수반되어야 한다.
[전망] 멀티 에이전트 아키텍처의 진화 방향은 결국 '컨텍스트의 물리적 이동을 최소화하고 상태 보존의 응집도를 높이는 것'으로 귀결된다. 무조건적인 마이크로서비스 분할이나 거대한 단일 모델(Single Brain)의 컨텍스트 윈도우 확장에 의존하는 접근은 단위 경제학(Unit Economics) 관점에서 지속 불가능하다. 향후 생성형 AI 시스템의 핵심 평가 지표는 단순한 생성 모델의 BLEU나 ROUGE 점수가 아닌, 시스템 전체의 상태 전환 효율성과 P99 레이턴시 통제 능력이 될 것이다. 프로덕션 환경의 신뢰성을 담보하려는 엔지니어라면, 모델의 파라미터를 늘리기 전에 데이터와 컨텍스트가 흐르는 네트워크 홉(Hop)의 구조적 병목부터 의심하고 검증해야 한다.