같은 모델인데 왜 청구서가 10배 차이 나나
월 AI 비용이 $5K인 팀과 $50K인 팀이 종종 같은 모델을 쓴다. dev.to의 AI 아키텍처 분석에 따르면 이 차이는 모델 선택이 아니라 설계 결정에서 온다. 더 정확히 말하면, 시스템을 처음 설계할 때 내린 결정들이 비용의 80%를 이미 고정시킨다. 프롬프트 최적화는 나머지 20%를 건드릴 뿐이다.
이 문제는 Claude Code의 예약 작업 기능이 팀에 실제로 배포되고, 코드베이스 전체를 탐색하는 에이전트가 일상적으로 돌아가기 시작하는 지금 시점에 훨씬 더 현실적인 이슈가 됐다.
Claude Code가 '클라우드 워커'가 됐다
Anthropic이 Claude Code에 클라우드 기반 예약 작업 기능을 추가했다(geeknews 보도). 로컬 머신 없이도 리포지터리·스케줄·프롬프트를 지정하면 클라우드 인프라에서 Claude가 반복 작업을 자율 실행한다. 활용 시나리오는 구체적이다.
- 야간 CI 실패 분석: 개발자가 퇴근한 사이 실패 로그를 분석해 원인 후보를 정리해 놓는다
- 오픈 PR 일괄 검토: 쌓인 PR을 스케줄에 맞춰 자동 리뷰하고 피드백 초안을 생성한다
- 문서 자동 동기화: 머지된 PR 기준으로 관련 문서를 업데이트한다
- 이슈 기반 기능 구현: 승인된 이슈를 감지해 코드 스캐폴딩을 자동 생성한다
claude.ai에 연결된 MCP 서버에도 접근할 수 있어 외부 도구와의 통합 워크플로우도 구성 가능하다. 테크 리드 입장에서 이건 반갑지만 동시에 신중해야 할 신호다. 자율 실행 에이전트가 24시간 돌아간다는 건, 토큰 소비가 24시간 발생한다는 뜻이기도 하다.
토큰 폭식의 원인: 에이전트는 파일을 읽는 방식으로 코드베이스를 탐색한다
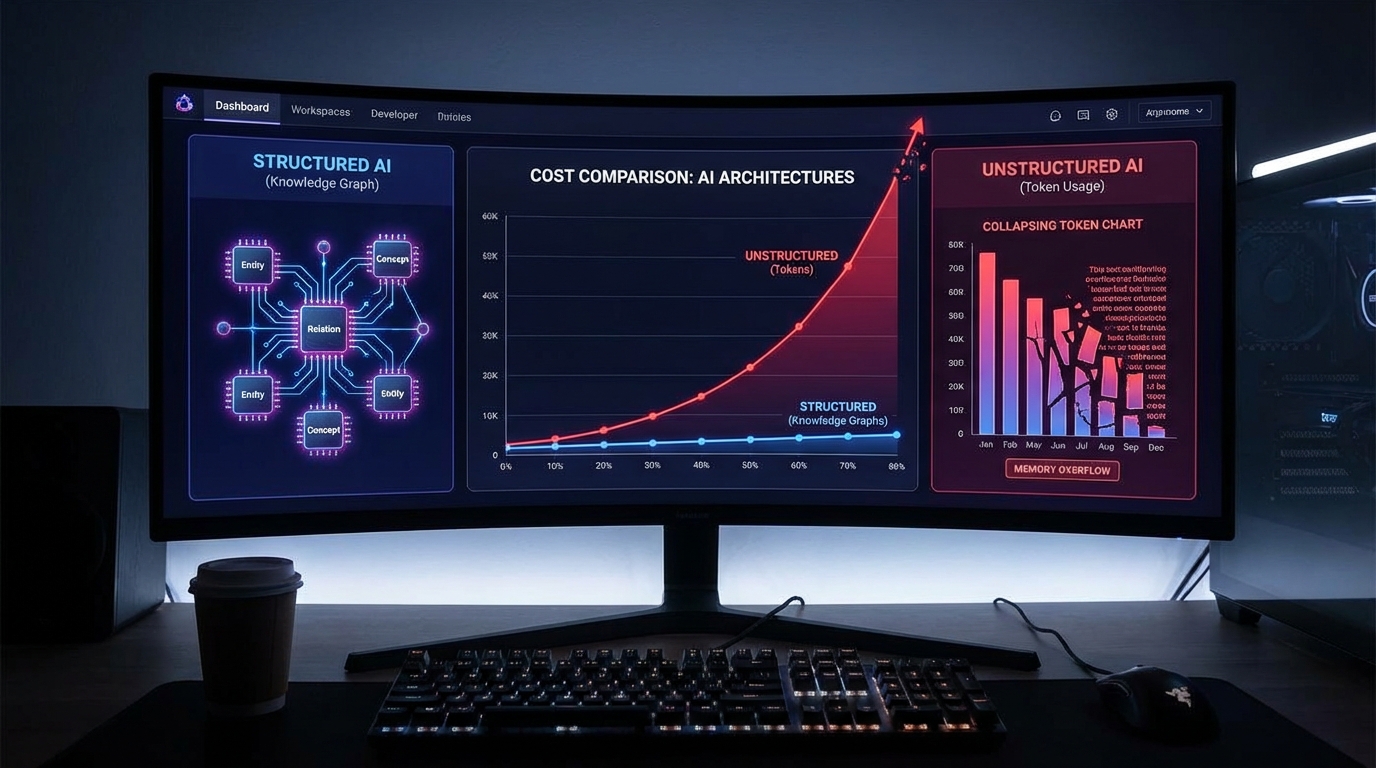
AI 코딩 에이전트의 구조적 비효율을 가장 선명하게 드러낸 사례가 최근 dev.to에서 공개됐다. ProcessOrder를 호출하는 함수가 뭔지 묻는 단순한 질문 하나에 Claude Code가 무려 45,000토큰을 소비한다는 실측 데이터다.
이유는 단순하다. 에이전트는 기본적으로 파일을 하나씩 열어가며 탐색한다. grep → 파일 읽기 → import 추적 → 컨텍스트 초과로 포기. 이 루프가 세션 내내 반복되면 시간당 수십만 토큰이 날아간다.
이를 해결하기 위해 개발된 codebase-memory-mcp는 접근 방식이 근본적으로 다르다. tree-sitter AST 파싱으로 코드베이스 전체를 한 번 인덱싱해 함수·클래스·콜 체인·HTTP 라우트를 SQLite 기반 지식 그래프로 저장한다. 이후 에이전트는 파일을 직접 뒤지는 대신 그래프에 구조적 질의를 날린다.
결과는 극적이다. 동일한 콜 체인 추적 질문에 ~800토큰, 응답 1ms 미만. 31개 언어, 372개 질문 기준 평균 121배 토큰 감소(99.2% 절감)를 기록했다. 리눅스 커널(2,800만 줄, 75,000파일) 전체를 M3 Pro에서 1분 만에 인덱싱했다는 스트레스 테스트 결과도 포함된다.
실용적인 부분은 Claude Code, Codex CLI, Gemini CLI 등 8개 에이전트와 통합되며, 별도 Docker나 API 키 없이 15MB 단일 바이너리로 설치된다는 점이다. MCP 훅이 에이전트에게 "파일 직접 읽기 전에 그래프를 먼저 확인하라"고 권고하는 방식으로 작동한다.
8가지 구조적 최적화: 프롬프트 다듬기 전에 이것부터
dev.to의 AI 비용 아키텍처 분석은 팀이 자주 놓치는 구조적 낭비 지점 8가지를 정리한다. 체크리스트로 쓸 수 있을 만큼 실용적이다.
1. 모델 라우팅: 모든 요청을 동일한 최고가 모델로 보내는 것이 가장 흔한 실수다. 요청 복잡도를 판단하는 라우팅 레이어를 두면 당일 40~80% 비용 절감이 가능하다.
2. 시맨틱 캐시: 반복 질문의 비율이 높은 고객 지원·내부 툴에서는 Redis + 임베딩 유사도 기반 캐시만으로도 모델 호출을 60% 줄일 수 있다.
3. RAG 정밀도: 청크 20개를 검색해 리랭커로 2~3개만 컨텍스트에 넘기는 구조가 기본이 돼야 한다. 컨텍스트 품질이 크기를 항상 이긴다.
4. 프롬프트 압축: "Please carefully analyze..." 류의 수식어는 토큰만 먹는다. JSON 스키마·재사용 템플릿·인스트럭션 ID로 대체하면 품질 손실 없이 20~50% 압축 가능하다.
5. 파이프라인 분해: 복잡한 작업을 단일 거대 프롬프트로 처리하는 대신 단계별로 쪼갠다. 인텐트 추출(저가 모델) → 데이터 검색(모델 비용 없음) → 실제 추론(고가 모델)의 구조에서 볼륨 대부분은 저렴한 앞단에서 처리된다.
6. 에이전트 메모리 설계: 매 턴마다 전체 히스토리를 재전송하는 에이전트는 30턴쯤 되면 쓸데없는 컨텍스트 비용이 폭발한다. 슬라이딩 윈도우 + 벡터 DB 검색 + 에피소드 요약의 3계층 메모리가 표준 설계다. 세션당 $0.10 vs $10의 차이가 여기서 난다.
7. 모델 디스틸레이션: 동일 태스크를 하루 1,000번 이상 실행한다면 프론티어 모델 출력으로 소규모 모델을 파인튜닝하는 것이 장기적으로 훨씬 저렴하다. 분류·추출·구조화 출력 태스크에서 ROI가 가장 빠르다.
8. 스트리밍 조기 종료: 응답 전체를 생성하고 나서야 반환하는 구조에서 사용자가 첫 단락에서 이미 필요한 정보를 얻는다면 나머지 토큰은 낭비다. 스트리밍 + 조기 종료 로직만으로 출력 토큰 20~30%를 줄일 수 있다.
테크 리드가 지금 당장 해야 할 것
세 소스가 공통으로 가리키는 지점이 있다. 에이전트 비용 문제의 대부분은 '어떤 모델을 쓰느냐'가 아니라 '어떤 구조로 쓰느냐'에서 결정된다. Claude Code의 예약 자동화가 팀 워크플로우에 녹아들수록, 에이전트가 코드베이스를 자율적으로 탐색하는 빈도가 높아질수록, 잘못 설계된 시스템의 청구서는 기하급수적으로 커진다.
내일 당장 할 수 있는 것 세 가지를 꼽는다면:
- 에이전트 토큰 로그부터 켜라. 세션당 실제 토큰 소비량을 측정하지 않으면 어디가 문제인지 알 수 없다.
- 코드 지식 그래프 도입을 검토하라. codebase-memory-mcp처럼 한 번 인덱싱 후 구조적 질의를 쓰는 패턴은 대형 코드베이스에서 즉각적인 토큰 절감을 가져온다.
- 모델 라우팅 레이어를 설계에 포함시켜라. 모든 요청을 최고가 모델로 보내는 설계는 기술 부채가 아니라 운영 비용 부채다.
전망: 자율 에이전트 시대의 비용은 '구조 설계 능력'으로 납부한다
Claude Code의 클라우드 예약 실행 기능은 AI 코딩 에이전트가 '도구'에서 '비동기 팀원'으로 전환하는 신호다. 에이전트가 야간에 혼자 CI를 분석하고, PR을 검토하고, 문서를 업데이트하는 시대가 이미 시작됐다.
이 전환에서 팀의 경쟁력을 결정하는 것은 어떤 에이전트를 쓰느냐가 아니라, 그 에이전트를 어떤 구조 위에서 굴리느냐다. 구조를 잘못 설계한 팀은 에이전트가 더 많이 일할수록 청구서가 더 빠르게 불어난다. 반대로 구조를 제대로 설계한 팀은 에이전트의 자율성이 높아질수록 단위 비용이 오히려 내려간다.
테크 리드의 역할이 '코드 리뷰어'에서 '시스템 설계자'로 이동하는 이유가 바로 여기 있다.