문제의 본질은 '모델 선택'이 아니라 '컨텍스트 설계'다
팀에 AI 코딩 도구를 도입하고 나서 가장 먼저 마주치는 문제는 대개 비용이다. 그런데 비용보다 더 조용하고 더 치명적인 문제가 있다. 하나의 에이전트가 기획부터 구현, 리뷰, 테스트, 문서화까지 긴 대화 안에서 처리하다 보면, 컨텍스트가 오염된다. 앞에서 결정한 제약 조건을 잊고, 단계가 바뀔 때마다 정밀도가 떨어진다. 결과물이 '대충 맞는 것 같은데 믿기 어려운' 상태가 된다.
dev.to에 공유된 agentflow 프로젝트의 저자는 이 문제를 정확히 짚었다. 비용 최적화보다 더 중요한 건 "프로세스의 일관성"이었다. 각 단계에 독립적인 컨텍스트 윈도우를 부여했더니 테스트 커버리지가 개선되고, 수동 개입이 줄었으며, 일부 이슈가 파이프라인 앞단에서 조기에 발견되기 시작했다.
에이전트와 워크플로우, 선택이 아니라 배치의 문제
여기서 팀 리드가 자주 빠지는 함정이 있다. '에이전트가 더 스마트하니까 에이전트를 쓴다'는 논리다. dev.to의 또 다른 글 Agents vs Workflows: A Decision Framework for 2026은 이 착각에 정면으로 반박한다.
에이전트와 워크플로우의 핵심 차이는 단 하나다. 다음 스텝을 누가 결정하는가. 워크플로우는 개발자가 설계 시점에 경로를 정의한다. 에이전트는 LLM이 런타임에 판단한다. 문제는 에이전트가 더 똑똑한 게 아니라, 에이전트가 필요한 상황이 생각보다 훨씬 좁다는 데 있다.
해당 프레임워크에 따르면 프로덕션 유즈케이스의 약 80%는 의사결정 트리의 1~2번 질문에서 멈춘다. 즉, 워크플로우이거나 'LLM 스텝 하나가 삽입된 워크플로우'로 충분하다. 완전 자율 에이전트가 정말 필요한 케이스는 전체의 2~3%에 불과하다. 나머지 대부분은 하이브리드, 즉 결정론적 워크플로우가 오케스트레이션을 담당하고, 판단이 필요한 구간에서만 에이전트에게 제한된 도구 세트를 넘기는 구조다.
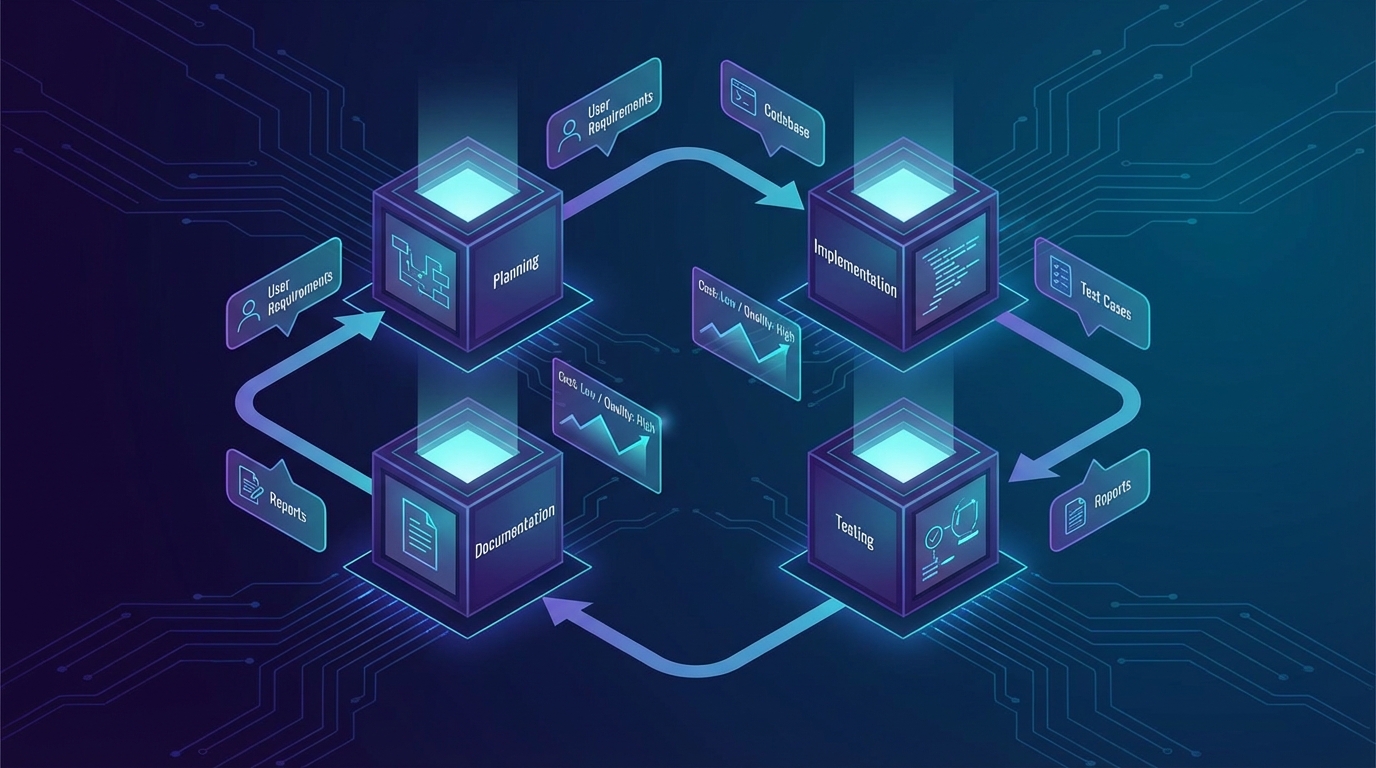
단계 분리의 실전 구조: 역할과 모델을 따로 배정하라
이 두 관점을 합치면 실행 가능한 아키텍처가 나온다. 기획-승인-구현-리뷰-테스트-문서화를 독립 에이전트로 분리하되, 각 단계에 '그 판단에 필요한 수준의 모델'만 투입하는 것이다.
- 기획 단계: 요구사항 분석과 기술 스펙 초안 작성. 높은 추론 능력이 필요하지만 컨텍스트 길이는 짧아도 된다.
- 구현 단계: 코드 생성. 컨텍스트 효율이 중요하고, 앞 단계의 결정이 깔끔하게 전달돼야 한다.
- 리뷰/테스트 단계: 독립된 컨텍스트에서 결과물을 검증. 구현 과정의 '판단 편향'을 그대로 이어받지 않는 게 핵심이다.
- 문서화 단계: 가장 낮은 추론 비용으로 처리 가능. 비싼 모델을 쓸 이유가 없다.
각 단계가 독립된 컨텍스트를 가지면 두 가지 효과가 동시에 발생한다. 오염되지 않은 상태에서 각 역할에 집중하니 품질이 올라간다. 그리고 과도한 모델을 쓰지 않으니 비용이 내려간다.
평가 누락이 불러오는 조용한 청구서
단계를 분리하더라도 빠뜨리면 안 되는 게 있다. 각 단계 출력의 평가(eval)다. The AI Eval Tax 글이 정리한 수치는 불편하다. LangChain의 1,340명 대상 조사에서 에이전트 관측 가능성(observability)을 갖춘 팀은 89%인데, 출력의 정확성을 인라인으로 평가(inline eval)하는 팀은 37%에 불과하다. 이 52포인트 갭이 바로 "eval tax"가 쌓이는 구간이다.
단계 분리를 잘 설계해도, 각 단계 출력에 품질·비용·안전성 게이트를 달지 않으면 다음 단계로 오류가 조용히 전파된다. 10단계 에이전트 체인에서 단계별 성공률이 97%라면, 전체 성공률은 0.97의 10제곱, 즉 74%다. 26%의 실행은 어딘가에서 실패한다. 이걸 모니터링하지 않으면 그 실패는 몇 주 뒤 고객 지원팀 백로그에서 발견된다.
팀 리드가 내일 당장 적용할 수 있는 것
이론은 길고 도입 장벽은 현실이다. 팀 규모와 상관없이 즉시 시작할 수 있는 출발점은 세 가지다.
첫째, 현재 단일 에이전트/단일 프롬프트로 처리하는 작업을 단계별로 써본다. '기획 프롬프트'와 '구현 프롬프트'를 물리적으로 분리하는 것만으로도 컨텍스트 오염이 줄어든다는 걸 금방 확인할 수 있다.
둘째, 각 단계에 '이 판단에 실제로 GPT-4급이 필요한가'를 물어본다. 문서화, 단순 라우팅, 포맷 변환은 훨씬 저렴한 모델로 대체 가능하다. 이것만으로 월간 LLM 비용의 30~50%를 줄인 팀들이 있다.
셋째, 각 단계 출력에 간단한 검증 게이트를 하나씩 붙인다. 완벽한 eval 인프라가 없어도 된다. "이 출력이 다음 단계 입력으로 유효한가"를 규칙 기반으로 체크하는 것만으로도 오류 전파를 막을 수 있다.
전망: 구조 설계가 곧 AI 역량이 되는 시대
AI-First 워크플로우의 다음 경쟁은 도구 선택이 아니다. 어떤 도구를 써도 기획-구현-검증의 단계를 얼마나 깔끔하게 설계하느냐가 팀의 속도와 품질을 결정한다. Gartner는 agentic AI 프로젝트의 40% 이상이 2027년까지 폐기될 것으로 전망한다. 비용 증가와 불충분한 리스크 통제가 이유다. 살아남는 팀은 eval 인프라를 일찍 구축하고, 에이전트를 '목적에 맞게 쪼갠' 팀이 될 것이다.
'AI는 동료다'라는 말이 현장에서 진짜 의미를 가지려면, 그 동료에게 명확한 역할과 책임 범위를 줘야 한다. 모든 걸 혼자 처리하는 동료는 번아웃되거나 실수한다. 에이전트도 다르지 않다.