AI 에이전트를 제품에 붙이면 초반 성장은 빠릅니다. 그런데 D7/D30에서 갑자기 막히는 팀이 많습니다. 원인은 기능 부족이 아니라 ‘신뢰/안정성’과 ‘관측/품질 관리’가 먼저 터지기 때문입니다. 유저는 한 번의 “그럴듯한데 틀린 답(Confident wrong answer)”을 겪으면 재방문 대신 이탈·환불·도입 보류로 반응합니다.
문제는 이 실패가 대시보드에 잘 안 보인다는 겁니다. HTTP 200, 에러율 0%, 평균 지연 시간 정상이어도 실제 산출물 품질은 떨어질 수 있습니다. dev.to의 ‘멀티 에이전트 블랙박스’ 글이 지적하듯, 로그는 “무슨 일이 있었는지”만 쌓고 “왜 그렇게 판단했는지”를 남기지 못해 디버깅이 아니라 추측을 하게 만듭니다.
여기에 ‘드리프트’가 추가로 리텐션을 갉아먹습니다. dev.to의 Eval Drift 아티클은 코드/프롬프트를 안 바꿔도 공급자(provider) 모델 업데이트로 출력 품질이 조용히 변할 수 있다고 경고합니다(예: GPT-4 성능의 기간별 변동을 다룬 연구 사례 인용). 즉, 제품팀이 아무것도 안 했는데도 어느 날부터 불만 티켓이 늘고, 세일즈는 “지난번 데모랑 다르다”는 피드백을 받습니다. 이 구간이 리텐션·확장 매출을 동시에 깨는 구간입니다.
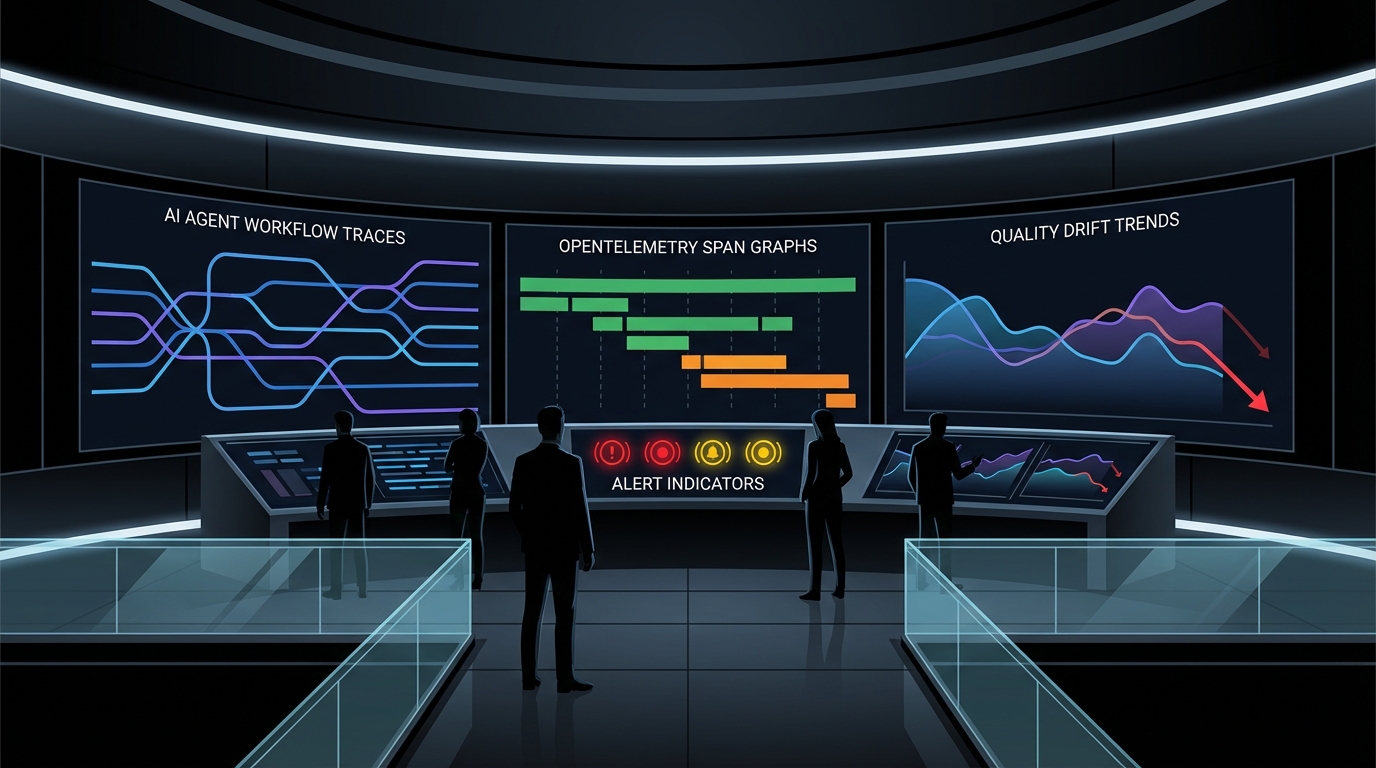
이때 필요한 건 ‘에이전트 리텐션 방어선’을 하나의 운영 프레임으로 묶는 겁니다. 첫 축은 표준화된 관측입니다. dev.to의 OpenTelemetry 글은 OpenTelemetry가 GenAI Semantic Conventions(실험 단계)를 공개해, LLM 호출/에이전트 호출/툴 실행을 공통 스팬 규약으로 남길 수 있게 됐다고 설명합니다. 핵심은 벤더마다 다른 트레이싱 포맷을 버리고, 동일한 속성/스팬 네이밍으로 “어느 백엔드에서든 해석 가능한” 계측을 만드는 것입니다. 이게 되는 순간, Jaeger 같은 기본 트레이싱부터 Phoenix/Langfuse/Datadog류의 LLM 옵저버빌리티로 옮겨 타도 대시보드가 ‘재구축’이 아니라 ‘전환’이 됩니다. 관측의 마이그레이션 비용이 내려가면, 품질 이슈 대응 속도가 곧바로 올라갑니다.
두 번째 축은 멀티에이전트 옵저버빌리티의 초점 이동입니다. 토큰/비용/지연만 보면 “성공”으로 보이는 경로에서 진짜 사고가 납니다. 따라서 ‘컨텍스트 트레이싱(무엇을 봤나)–결정 경계(무슨 기준으로 골랐나)–전파 추적(누구의 출력이 누구의 입력이 됐나)’을 최소 메타데이터로 남겨야 합니다. 전 구간 100% 풀로그가 아니라, 실패·이상 징후는 100% 트레이스, 정상 경로는 10~20% 샘플링처럼 비용을 통제한 방식이 현실적입니다.
세 번째 축이 드리프트 대응입니다. “배포 시점 1회 평가”로는 공급자 업데이트를 못 잡습니다. Eval Drift 글이 말하듯, 실행마다(가능하면 전수) 빠른 휴리스틱 평가 점수를 남겨 시계열로 저장하고, 7일 이동평균이 기준선 아래로 떨어지면 알람을 거는 방식이 필요합니다. 중요한 포인트는 ‘원인 추정’이 아니라 ‘조기 탐지’입니다. 유저 신고로 발견하면 이미 D30 리텐션은 깨졌고, 엔터프라이즈 세일즈는 다시 보안/품질 검증 사이클로 돌아갑니다.
이 세 축을 합치면, 성장 지표가 한 번에 움직입니다. (1) 품질 이슈 재현 시간이 줄어 CS 처리시간과 환불률이 내려가고, (2) “왜 그렇게 동작했는지”를 스팬/메타데이터로 설명할 수 있어 세일즈 PoC의 신뢰도가 올라가며, (3) 드리프트를 빨리 잡아 D7/D30 코호트 하락을 선제적으로 막습니다. 즉, 옵저버빌리티는 비용센터가 아니라 리텐션 방어를 통한 LTV 레버입니다.
전망은 명확합니다. OpenTelemetry의 LLM 트레이싱 표준(GenAI Semantic Conventions)이 실험 단계라도, 방향성은 ‘표준 속성으로 생태계가 연결되는 쪽’으로 잠겼습니다(dev.to OpenTelemetry 구현기에서 이미 여러 백엔드가 동일 속성을 인지한다고 언급). 앞으로는 “에이전트가 똑똑한가?”보다 “운영 중 품질을 증명하고, 변화를 감지하고, 원인을 추적할 수 있는가?”가 도입의 기준이 됩니다. 지금 관측을 표준으로 맞추고, 멀티에이전트 전파 추적과 지속 평가를 묶어두면, 다음 모델 업데이트가 와도 리텐션은 방어되고—그게 결국 성장의 상한선을 올립니다.