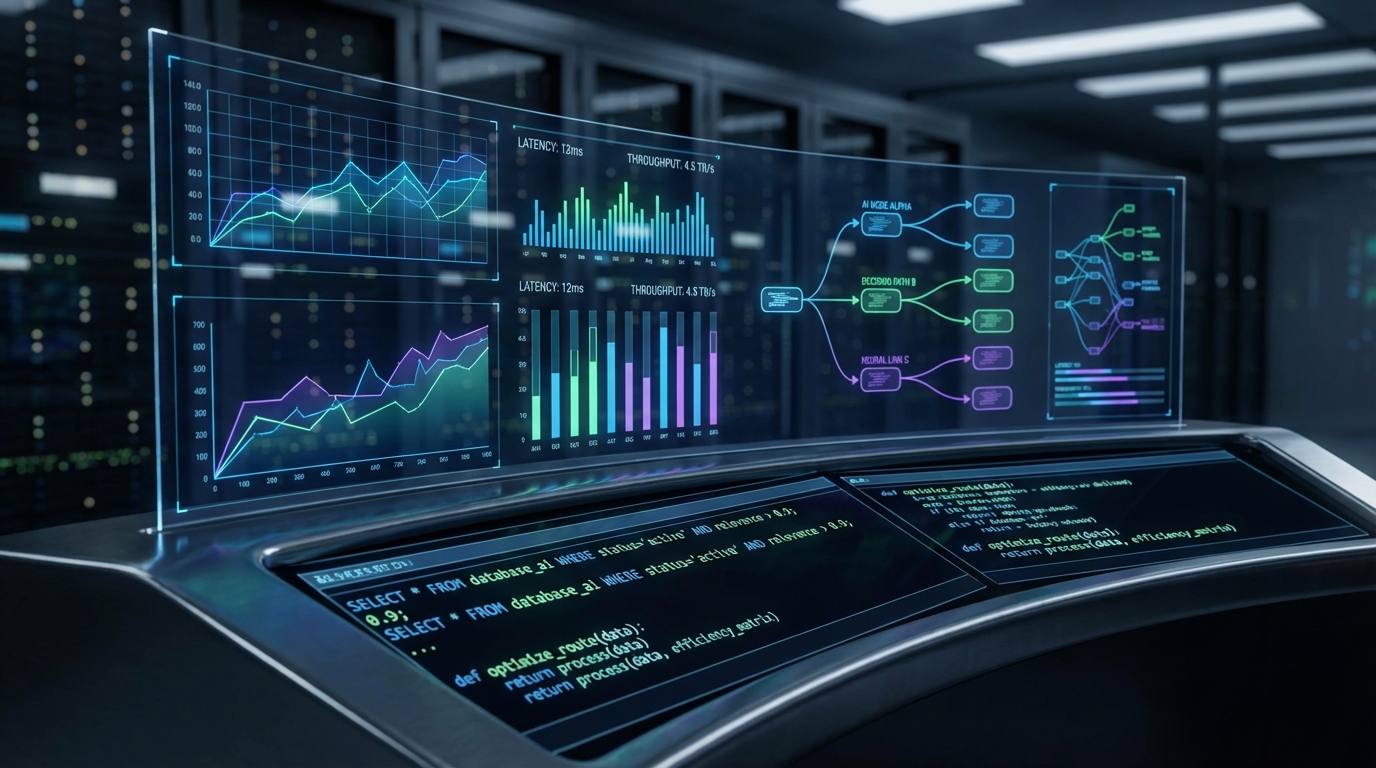
생성형 AI 에이전트를 프로덕션 환경에 배포하는 기업들의 가장 치명적인 맹점은 '관측성(Observability)의 착각'이다. Dev.to에 공유된 LangChain의 2025년 엔지니어링 설문조사에 따르면, 89%의 조직이 인프라 레벨의 관측성을 확보하고 있으나 실제 프로덕션 트래픽에 대해 온라인 평가(Online Evals)를 수행하는 비율은 37%에 불과하다. 이는 API 호출의 완료 여부나 네트워크 지연 시간만 모니터링할 뿐, 모델이 생성한 결과물의 사실성(Factuality)이나 논리적 결함은 방치하고 있다는 뜻이다. 비결정론적(Non-deterministic) 모델의 확률적 생성 과정에서 발생하는 실패는 명시적인 시스템 에러를 발생시키지 않고 조용히 사용자에게 전달된다. 즉, 대다수의 에이전트 시스템은 사실상 0%의 '평가 커버리지(Eval Coverage)'로 운영되며 막대한 TCO(총소유비용) 리스크를 누적하고 있다.
이러한 블랙박스 문제를 해결하기 위한 첫 번째 통제 수단은 컨텍스트 윈도우의 구조적 효율성을 극대화하여 생성 품질의 베이스라인을 높이는 것이다. Dev.to에 소개된 'rails-ai-context' 프레임워크의 프로덕션 적용 사례는 무지성 파일 덤프가 야기하는 토큰 낭비와 환각(Hallucination)의 상관관계를 정량적으로 증명한다. 런타임에 동적으로 구조가 결정되는 애플리케이션의 특성을 에이전트가 이해하도록 하기 위해, 단순히 전체 코드를 컨텍스트에 밀어 넣는 대신 MCP(Model Context Protocol) 기반의 구조화된 질의(Query) 계층을 도입했다. 그 결과, 프로덕션 앱 기준 토큰 사용량을 37% 절감하면서도 에이전트의 첫 시도 성공률(First-attempt success rate)을 기존 50%에서 90%로 수직 상승시켰다. 이는 텍스트 전처리 및 주입 방식이 컴퓨팅 비용과 직결될 뿐만 아니라, 생성 품질에 결정적인 인과적 영향을 미친다는 것을 시사한다.
입력단의 토큰 최적화를 시스템적으로 제어했다면, 출력단에서는 100%의 평가 커버리지를 확보해야만 에이전트의 신뢰성을 담보할 수 있다. 기존의 샘플링 기반 수동 평가나 25% 수준의 스팟 체크는 나머지 75%의 롱테일 실패(P99 영역의 심각한 환각이나 PII 유출, 과도한 API 호출 등)를 은폐하는 통계적 착시를 일으킨다. Iris와 같은 MCP 기반의 인라인(inline) 평가 도구가 기술적 우위를 갖는 이유는 평가 파이프라인을 애플리케이션 코드의 부가적인 계층이 아닌, 에이전트가 통신하는 기본 프로토콜 레벨에 구조적으로 통합했기 때문이다. 이를 통해 프로덕션 서빙 환경의 지연 시간(Latency) 페널티를 최소화하면서 모든 실행(Execution) 단위에 대해 품질, 안전성, 비용을 독립적으로 검증하는 체계적 접근이 가능해진다.
과거 소프트웨어 공학에서 80% 이상의 테스트 커버리지를 강제하는 TDD(테스트 주도 개발)가 필수 표준으로 자리 잡았듯, AI 에이전트 생태계 역시 프롬프트를 작성하기 전 평가 룰을 먼저 수치화하는 EDD(Eval-Driven Development)로 빠르게 재편될 것이다. P99 지연 시간과 추론 비용에 민감한 프로덕션 환경에서는 '근간이 되는 LLM이 얼마나 거대한가'보다 '오작동을 얼마나 저비용으로, 정확하게 추적하고 차단할 수 있는가'가 시스템의 성패를 가른다. 따라서 데이터 엔지니어와 ML 아키텍트는 맹목적인 파라미터 확장에 의존하기보다, 구조화된 컨텍스트 주입을 통한 토큰 다이어트와 자동화된 100% 평가 커버리지 파이프라인 구축이라는 두 축을 최우선으로 설계해야 한다.