AI 도구가 몰래 만든 140개의 파일
Claude Code를 일주일 쓰고 나서 ~/.claude/ 디렉터리를 열어본 적 있나요? dev.to에 올라온 한 개발자의 고백이 눈길을 끌었습니다. -home-user-projects-my-app/ 같은 인코딩된 경로명 폴더들 사이에 메모리, 스킬, MCP 서버 설정, 훅이 총 140개 넘게 흩어져 있었다는 겁니다. 본인이 만든 건 거의 없었고요. Claude가 "이거 기억해줘"라는 말 한마디에, 혹은 도구를 하나 설치할 때마다 현재 디렉터리 스코프에 조용히 파일을 쌓아놓은 결과였습니다.
더 아이러니한 건 스코프 오염(scope contamination) 문제입니다. 모든 프로젝트에 적용하고 싶었던 TypeScript 선호 설정은 특정 프로젝트 스코프에 갇혀 있고, 한 레포에만 써야 할 배포 스킬은 글로벌 스코프로 새어나가 다른 프로젝트까지 오염시킵니다. 심지어 같은 MCP 서버 항목이 서로 다른 디렉터리에서 추가되면서 세 군데 중복 저장된 경우도 있었습니다. Claude는 매번 아무 말 없이 그냥 복제했고요.
이게 단순한 지저분함이 아닌 이유
이건 미관의 문제가 아니라 컨텍스트 윈도우 효율 문제입니다. Claude Code는 세션을 시작할 때 현재 스코프와 상위 스코프를 모두 로드합니다. 6개월 전 아카이브한 프로젝트의 메모리, Python 데이터 파이프라인용 스킬, 중복된 MCP 서버 초기화—이것들이 모두 React 프론트엔드 작업 세션의 컨텍스트를 잠식합니다. 컨텍스트 윈도우는 유한하고 비쌉니다. 잘못된 위치에 놓인 설정 한 줄이 실제 작업에 써야 할 토큰을 갉아먹고, LLM이 걸러야 할 노이즈를 늘려 정확도를 떨어뜨립니다.
물론 Claude에게 "내 메모리 전체 보여줘"라고 물어볼 수 있습니다. 하지만 해보면 압니다—한 디렉터리 ls하고, 다시 요청하면 다른 디렉터리 ls하고, 파일을 하나씩 cat해가며 20번 질문해야 전체 그림이 나옵니다. 자기 설정을 파악하는 데 20번의 핑퐁이 필요한 도구라면, DX라고 부를 수 없습니다.
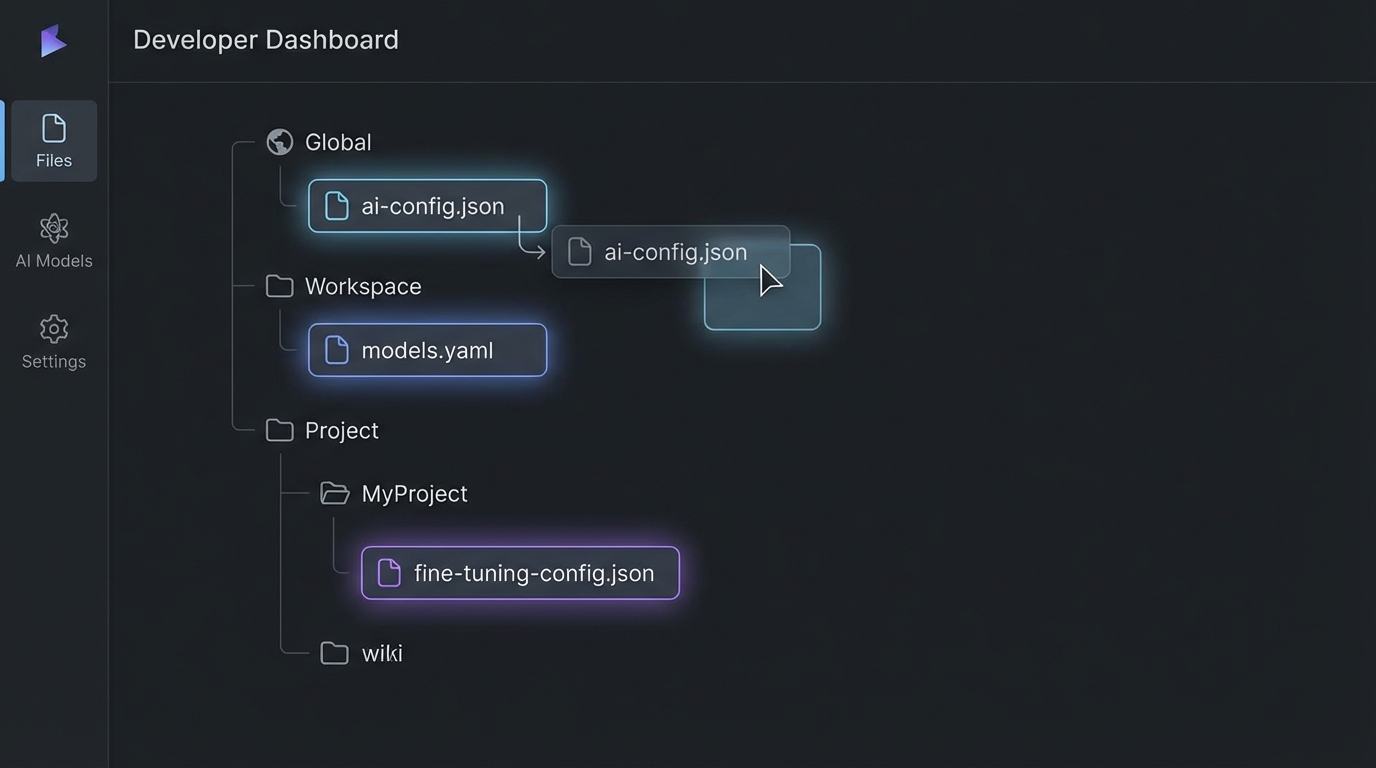
스코프 계층을 한눈에: claude-code-organizer
이 문제를 직접 겪고 대시보드를 만든 개발자가 공개한 도구가 @mcpware/claude-code-organizer입니다. npx @mcpware/claude-code-organizer 한 줄로 로컬호스트에 웹 대시보드가 열립니다. Claude Code의 세 스코프 레이어(Global → Workspace → Project)를 인터랙티브 트리로 렌더링해주고, 특정 프로젝트를 열면 해당 세션에서 실제로 로드되는 메모리·스킬·MCP 설정 전체를 상속 체인 포함해서 보여줍니다.
핵심 기능은 드래그 앤 드롭 스코프 이동입니다. 프로젝트 스코프에 갇힌 TypeScript 선호 설정? 글로벌로 드래그. 글로벌에 새어나간 배포 스킬? 해당 레포 프로젝트 스코프로 드래그. 6개월 된 낡은 메모리? 확인하고 삭제. 중복 MCP 서버 항목? 한눈에 발견하고 정리. 제로 의존성, 빌드 스텝 없이 바닐라 HTML/CSS/JS로 구현했고, MCP 서버로도 등록해두면 Claude가 scan_inventory, move_item, delete_item 툴로 직접 자기 설정을 프로그래매틱하게 관리할 수 있습니다.
AI가 '제대로 아는' 상태를 만드는 건 결국 문서화
설정 관리와 함께 주목할 또 다른 축은 문서의 정확성입니다. 2024년 Macke & Doyle 연구에 따르면, 잘못된 문서화는 LLM 태스크 성공률을 22.6퍼센트포인트 떨어뜨립니다. 흥미로운 건 문서가 없는 경우엔 통계적으로 유의미한 차이가 없다는 점입니다. AI 코딩 어시스턴트에게 틀린 정보는 정보 없음보다 더 나쁩니다.
docvet v1.14는 바로 이 지점을 파고듭니다. 파라미터 이름을 리팩터링하면서 docstring의 Args: 섹션 업데이트를 빠뜨리는 건 누구나 한 번쯤 겪는 실수입니다. 새 버전은 함수 시그니처와 docstring을 파라미터 단위로 대조해 missing-param-in-docstring, extra-param-in-docstring을 잡아냅니다. 더 나아가 역방향 검사도 추가됐습니다—코드가 절대 raise하지 않는 예외를 docstring이 선언하고 있다면, 그건 AI 도구가 없지도 않은 에러 핸들링 코드를 생성하게 만드는 함정입니다.
def get_user(): """Get user.""" 같은 trivial docstring도 이제 감지합니다. 존재 검사는 통과하지만 정보량은 제로인 문서—AI 코드 생성 시대에 이런 형식적 문서화가 오히려 더 위험한 이유가 여기 있습니다.
DevPulse가 보여주는 또 다른 가능성: CLAUDE.md 설계
Claude Code를 진짜로 길들이는 또 하나의 접근은 에이전트 아이덴티티를 명시적으로 설계하는 것입니다. DevPulse는 ~/.claude/CLAUDE.md에 XP 공식, 난이도 기준, 배지 정의 30개를 전부 기술해두고, 커밋 때마다 Notion MCP를 통해 자동으로 개발 세션을 로깅하는 글로벌 에이전트입니다. 별도 서버도 백엔드도 없이, CLAUDE.md 한 파일이 에이전트의 '뇌'를 구성합니다.
이 아키텍처가 흥미로운 건 Hard Constraints 섹션 때문입니다. "Notion 프로퍼티를 절대 hallucinate하지 말 것", "빈 세션은 로깅하지 말 것", "배지 체크는 idempotent하게 실행할 것" 같은 명시적 제약이 CLAUDE.md에 박혀 있습니다. 컨텍스트에 정확한 규칙을 심어두면 에이전트 동작이 예측 가능해진다는 걸 실증하는 사례입니다.
시사점: AI 도구의 DX는 '통제 가능성'에서 시작된다
세 가지 사례가 결국 하나의 방향을 가리킵니다. Claude Code가 140개 파일을 쌓아두는 문제든, docstring이 LLM 정확도를 떨어뜨리는 문제든, CLAUDE.md 설계 문제든—공통 질문은 같습니다. "지금 AI가 무엇을 알고 있고, 그게 맞는가?"
AI 코딩 도구를 단순한 자동완성 플러그인이 아니라 워크플로우의 구조적 파트너로 쓰려면, 에이전트가 참조하는 컨텍스트를 의식적으로 설계하고 관리해야 합니다. 스코프를 정리하고, 문서의 정확성을 검증하고, 에이전트 아이덴티티를 명문화하는 것—이 세 가지는 선택이 아니라 AI 워크플로우의 기본 위생(hygiene)입니다.
앞으로의 방향
claude-code-organizer는 v0.3 단계로, 인라인 편집과 설정 번들 내보내기/복원 기능이 로드맵에 있습니다. docvet은 다음 단계로 파라미터에 대한 내용이 실제 코드 동작과 일치하는지를 검증하는 시맨틱 검증을 예고하고 있습니다. 설정 가시성과 문서 정확성—둘 다 아직 초기 단계지만, AI가 더 깊이 개발 워크플로우에 들어올수록 이 두 영역의 도구 성숙도가 실제 생산성의 병목이 될 것입니다. 지금 가장 먼저 할 일은 ~/.claude/를 한번 열어보는 것에서 시작합니다.