'100만 토큰 시대'라는 마케팅 용어가 프로덕션 환경의 엔지니어들을 오도하고 있다. dev.to에 최근 공개된 두 건의 실증적 실험(데이터 파이프라인 관리 OS 구축 사례 및 보안 MCP 서버 개발기)은 무비판적인 컨텍스트 윈도우(Context Window) 확장이 컴퓨팅 리소스의 낭비일 뿐만 아니라, 생성형 모델의 추론 성능을 심각하게 훼손한다는 점을 정량적으로 증명한다. 무작위의 로그 데이터를 그대로 LLM에 밀어 넣는 행위는 프롬프트 내 신호 대 잡음비(SNR, Signal-to-Noise Ratio)를 급락시켜 환각(Hallucination) 현상을 증폭시키고 토큰 비용의 선형적 폭발을 야기한다.
솔로몬 네아스(Solomon Neas)가 구축한 7개의 보안 MCP 서버 사례는 에이전트 연동에서 프로토콜보다 '컨텍스트 엔지니어링(Context Engineering)'이 핵심 병목임을 명확히 보여준다. 40개 이상의 필드를 가진 Wazuh 알람 데이터를 날것(Raw JSON)으로 주입하면 모델의 어텐션(Attention)이 분산되어 Answer Relevance(답변 적합성) 메트릭이 급락한다. 이를 해결하기 위해 심각도(Severity) 8 이상의 데이터만 통과시키고 핵심 15개 필드로 사전 집계(Pre-aggregation)를 수행하는 하드 필터링을 거쳤을 때, 추론 품질은 비약적으로 상승했다. 이는 모델에 제공되는 정보의 양이 아니라, 엄밀하게 정제된 정보의 밀도(Density)가 문제 해결 능력과 직접적인 인과관계를 가짐을 시사한다.
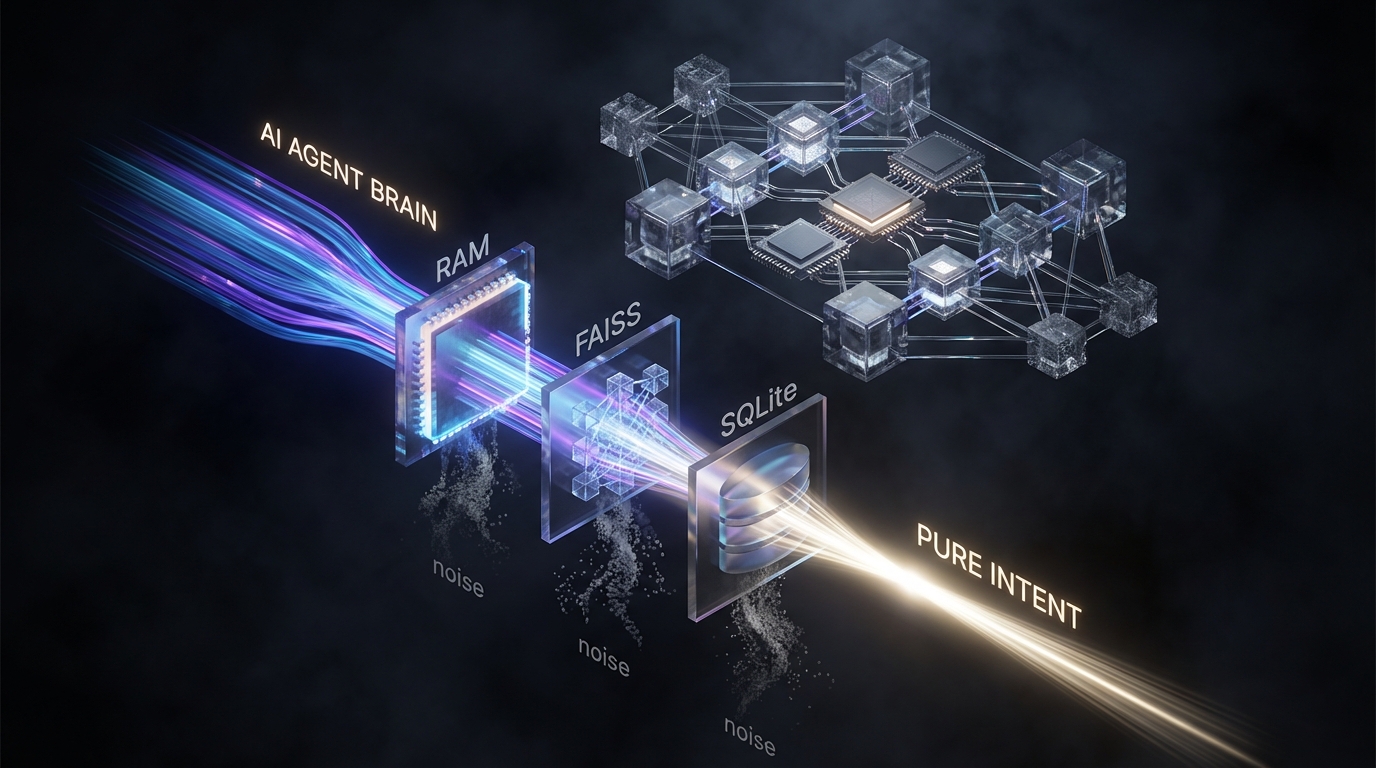
또 다른 사례인 'DataPipeline-Sentinel' 프로젝트는 에이전트의 '기억 상실(Amnesia)' 한계를 4단계 계층형 메모리(컨텍스트, 의미론적, 일화적, 선언적)로 해결하는 아키텍처를 제시한다. 여기서 주목할 정량적 최적화 포인트는 벡터 DB(FAISS)와 관계형 DB(SQLite)의 하이브리드 결합이다. 수학적 임베딩 유사도에 의존하는 FAISS의 퍼지(Fuzzy) 검색만으로는 RAG의 Faithfulness(사실성)를 100% 보장하기 어렵다. 따라서 매일 발생하는 장애 처리 로그(일화적 메모리)를 야간 배치(Cron job) 프로세스를 통해 LLM으로 요약·압축하고, 이를 명시적인 SQL WHERE 절로만 조회되는 '선언적 메모리(Declarative Memory)'로 전환했다. 이 분리형 설계는 실시간 추론 시 P99 지연 시간(Latency)을 최소화하면서도, 데이터가 누적될수록 하드코딩된 규칙의 비중을 높여 시스템의 신뢰성을 확보한다.
프로덕션 레벨의 자율형 에이전트(Autonomous Agent)는 무한한 메모리가 아니라, 엄격한 데이터 제어 파이프라인을 통해 완성된다. 원시 로그의 실시간 주입은 O(n)의 토큰 비용을 발생시키지만, 앞선 사례와 같은 메모리 압축(Consolidation) 및 컨텍스트 필터링 파이프라인은 이를 O(1) 수준의 고정 비용으로 통제한다. 향후 에이전트 시스템의 성능 우위는 LLM 자체의 스펙보다, 모델 외부(임베딩 이전 단계)에서 얼마나 결정론적으로 노이즈를 제거하고 계층화된 메타데이터를 라우팅할 수 있는지에 달렸다. 시스템 설계자는 A/B 테스트를 통해 각 메모리 계층별 컨텍스트 압축률과 Task 성공률 간의 상관관계를 지속적으로 추적하여 비용-성능의 최적점(Trade-off)을 도출해야 한다.