AI 에이전트/툴 시장에서 지금 가장 흔한 성장 병목은 성능이 아니라 ‘설정 지옥’과 ‘비용 블랙박스’다. 설치·설정이 길어지면 활성화(Activation) 전에 이탈하고, 운영 중 비용이 터지면 리텐션보다 먼저 “끄자”가 나온다. 온보딩 마찰과 비용 통제는 따로가 아니라, 같은 퍼널의 앞(첫 성공)과 뒤(지속 사용)를 동시에 쥐고 있는 레버다.
dev.to의 「Nobody Reads Your Setup Docs」가 던지는 메시지는 직설적이다: 사용자는 문서를 안 읽는다. MCP를 지원하는 에이전트가 늘어날수록 설정 파일 경로·포맷·규칙이 제각각이라, README를 잘 써도 ‘작동은 하는데 실제로는 안 쓰이는’ 상태가 된다. 여기서 Nia가 택한 해법(설치 마법사로 로컬 스캔→자동 설정)은 성장 관점에서 TTV(Time to Value)를 분 단위로 줄여 전환율을 올리는 정공법이다.
같은 글에서 Superpowers 사례는 한 단계 더 간다. “툴을 설치”하는 것만으로는 부족하고, 에이전트가 ‘언제/어떻게’ 쓰는지를 학습시키는 스킬(마크다운)을 함께 배포해야 한다는 것. 이 지점이 중요하다. 온보딩의 목표는 설치 완료가 아니라 ‘첫 과업 성공률(First Task Success Rate)’이다. 스킬은 사용자의 시행착오를 줄여 초기 성공을 만들고, 곧바로 D1 리텐션을 밀어준다.
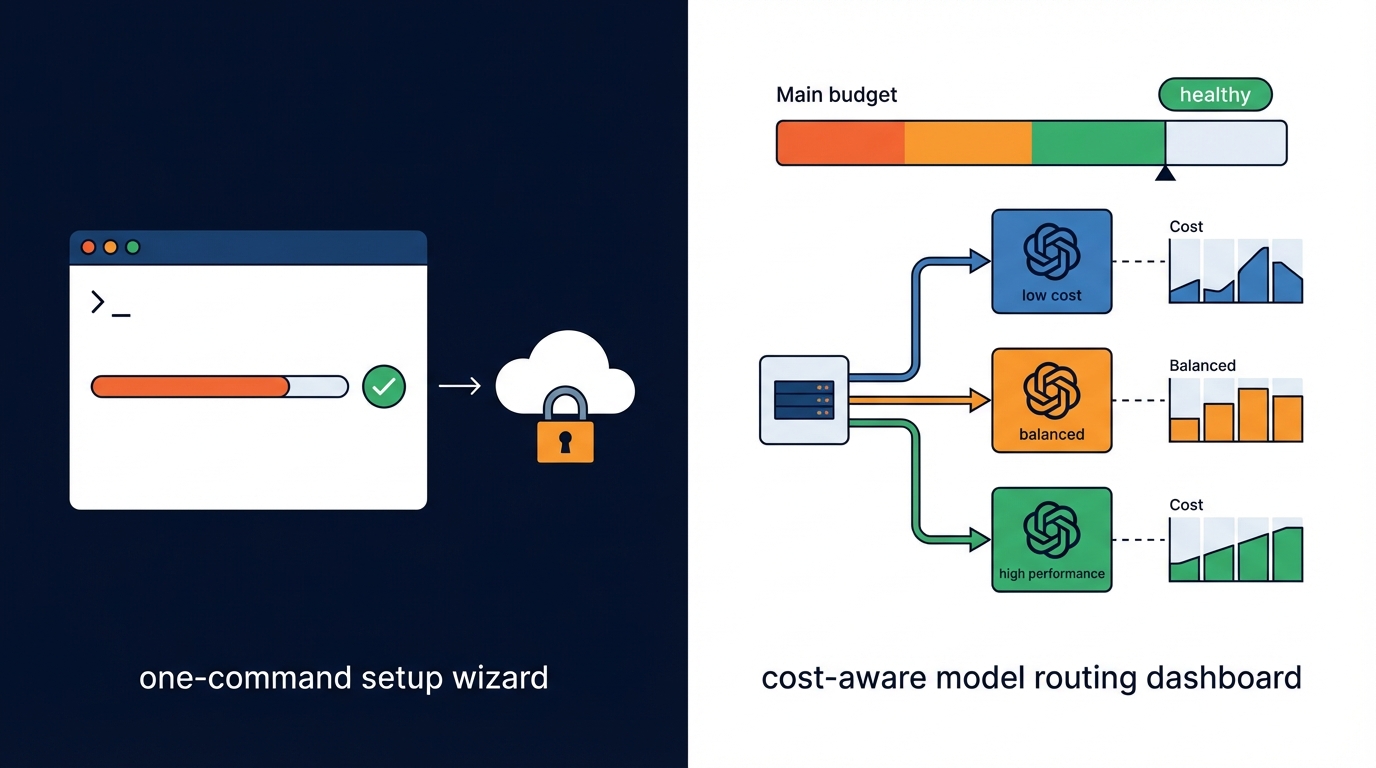
여기에 비용 축을 붙이면 그림이 완성된다. dev.to의 「Cost-Aware Model Routing…」는 “비용이 비싼 모델 때문이 아니라 모든 요청이 비싼 모델로 가는 라우팅 부재 때문”이라고 말한다. 즉, 비용 최적화의 실체는 ‘모델 선택을 런타임 분류 문제로 만들고(복잡도·신뢰도·지연 민감도·비용 상한·리스크), 인퍼런스 전에 결정을 끊는 것’이다. 이걸 안 하면 CAC로 데려온 유저가 늘수록 COGS가 비례가 아니라 가속으로 터진다.
「Why your OpenClaw bill is 10x…」는 운영 현장의 ‘조용한 비용 폭탄’ 3종(리트라이 폭풍, 컨텍스트 누적, 루프 툴콜)을 보여준다. 특히 무서운 건 대시보드로는 원인을 못 찾고 “토큰이 많이 나갔네”로 끝나는 지점이다. 이때 필요한 건 사후 회계가 아니라, 런 단위의 원인 추적(어느 세션이 태웠는지)과 차단(서킷 브레이커/버짓)이다. 비용 가시화는 곧 리텐션 기능이다. 예산 통제 불능은 신뢰를 깨고 해지를 만든다.
시사점은 명확하다. 에이전트/AI 기능을 성장 지표로 연결하려면, (1) 원커맨드 온보딩(환경 스캔→자동 설정→스킬 설치)로 활성화 전 이탈을 줄이고, (2) 라우팅+버짓+로그 스캔으로 “확장할수록 손해” 구조를 제거해야 한다. 이 두 개를 한 번에 묶으면 CAC는 내려간다(지원/세팅 문의 감소, 셀프서브 전환 증가). 전환율은 오른다(첫 성공 빨라짐). 리텐션은 오른다(비용 쇼크 감소). COGS는 내려간다(요청당 적정 모델/토큰 사용).
실행 체크리스트로 바꾸면 더 간단하다. 첫째, 설치 플로우를 README가 아니라 CLI 위저드로 옮기고, “에이전트 탐지→설정 자동 주입→재시작 후 즉시 사용”까지 60초 안에 끝내라(Nia/hanzi-browse 패턴). 둘째, 스킬을 제품의 일부로 배포해 첫 작업을 템플릿화하라(Superpowers 패턴). 셋째, 프로덕션에는 반드시 라우팅 레이어를 두고(게이트웨이/사이드카/애플리케이션 계층 중 단계에 맞게), 작은 모델→큰 모델 캐스케이드와 신뢰도 기반 에스컬레이션을 기본값으로 잡아라. 넷째, OpenClaw 사례처럼 리트라이·컨텍스트·루프를 런타임에서 탐지/차단하는 로컬/프록시 계측을 붙여 “청구서가 오기 전에” 멈춰라.
전망: MCP/에이전트 생태계가 커질수록 ‘기능 경쟁’은 더 빨리 평준화되고, 승부는 온보딩과 비용 운영에서 갈린다. 초기에는 “한 번만 설정하면 되잖아”가 통하지만, 제품이 성장하면 그 한 번이 수천 번이 되고, 그때부터는 마찰이 CAC를, 비용 불확실성이 LTV를 무너뜨린다. 다음 라운드의 경쟁우위는 더 좋은 모델이 아니라 더 빠른 첫 성공과 더 예측 가능한 단가다. 그리고 그 둘은, 위저드(온보딩)와 라우팅/버짓(비용)으로 오늘 당장 실험할 수 있다.