대부분의 엔지니어는 AI 게이트웨이를 Nginx와 같은 단순한 I/O 바운드 리버스 프록시로 간주하는 치명적인 오류를 범한다. 그러나 최근 dev.to에 공개된 벤치마크 리포트는 이러한 멘탈 모델이 완전히 틀렸음을 정량적으로 증명한다. JSON 페이로드 파싱, API 키 검증, 라우팅 룰 해석 및 로깅은 순수한 CPU 연산이며, 동시성 부하(Concurrent Load) 상황에서 직렬화(Serialization) 병목을 유발한다. AI 서빙의 지연 시간은 LLM 자체의 추론 시간뿐만 아니라, 이 게이트웨이 레이어의 런타임 오버헤드에서 결정된다.
해당 벤치마크는 60ms의 고정 지연 시간을 가진 업스트림 서버를 모킹하여 순수 게이트웨이 오버헤드를 독립적으로 측정했다. 결과는 아키텍처의 민낯을 여과 없이 드러낸다. Python 기반의 LiteLLM은 미들웨어 체인의 CPU 포화로 인해 동시성과 무관하게 약 175 RPS에서 처리량 천장(Ceiling)에 도달했다. Go로 작성된 Bifrost조차 커넥션 풀 고갈(Starvation) 및 스케줄러 경합으로 300 VU(Virtual Users)에서 1천만 건 이상의 요청이 실패하는 절벽(Cliff) 현상을 보였다. 반면 Ferro Labs와 같은 네이티브 바이너리는 1,000 VU(약 13,925 RPS)의 극단적 환경에서도 P50 오버헤드 8.1ms, P99 오버헤드 51.9ms를 기록하며 선형적인 확장을 증명했다. 이는 프로덕션 환경에서 언어 런타임과 스레드 경합 통제가 P99 지연 시간에 얼마나 결정적인 영향을 미치는지 시사한다.
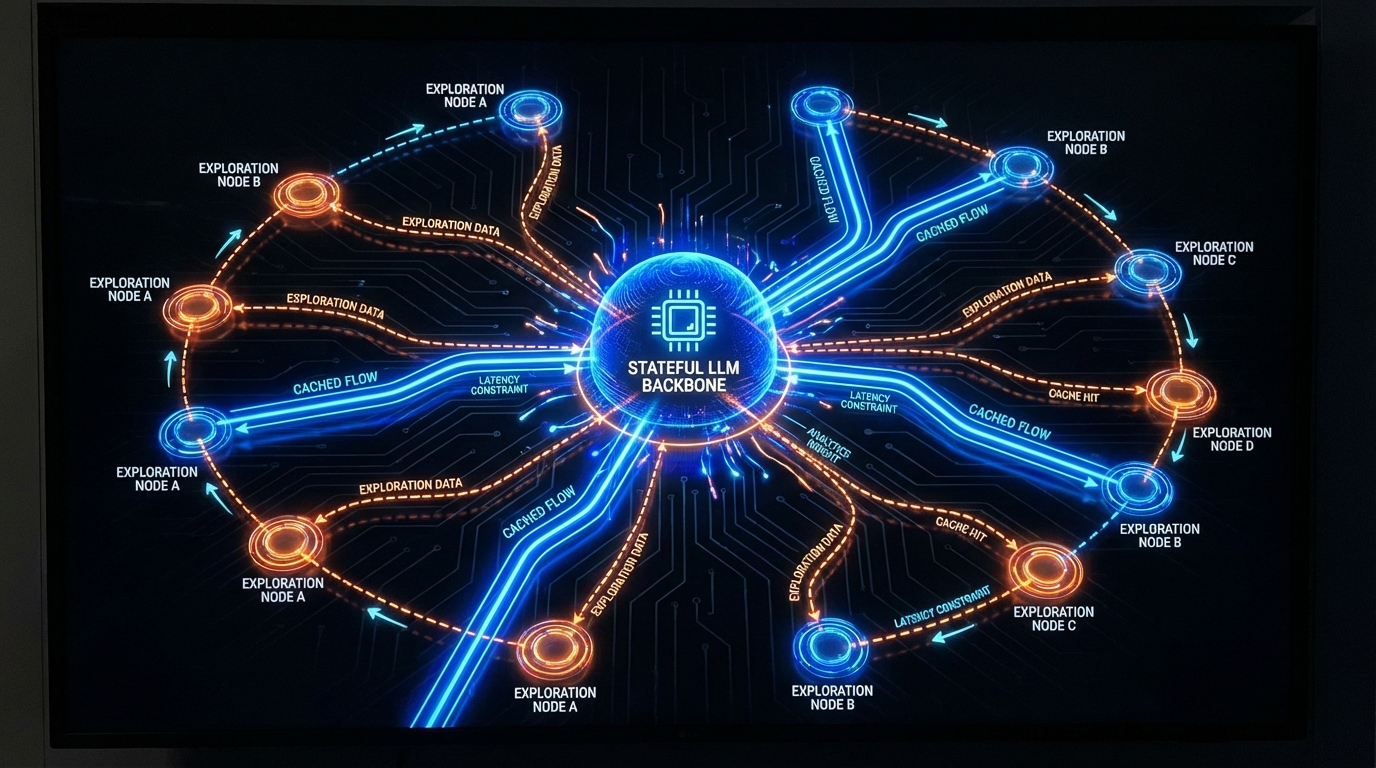
인프라 단의 네트워크 지연을 통제했다면, 애플리케이션 단에서는 토큰 비용(COGS)을 최적화해야 한다. dev.to에 제안된 'HotSwap' 아키텍처는 이를 '프롬프트 캐시 경제성(Cache Economics)'이라는 데이터 중심적 관점으로 풀어낸다. Anthropic의 프롬프트 캐싱은 입력 토큰 비용을 90% 절감하지만, 캐시된 Sonnet 모델의 1턴 비용은 여전히 약 $0.0045다. 반면 저렴한 소형 모델(예: GPT-4o-mini)의 1턴은 약 $0.001에 불과하다. 기존의 단순 라우팅(LiteLLM, OpenRouter)은 세션 상태와 캐시의 존재를 무시하여 매번 독립적 호출을 발생시키지만, HotSwap은 이를 결합하여 비용-성능 트레이드오프의 새로운 기준점을 제시한다.
HotSwap의 핵심은 상태가 유지되는(Stateful) 고성능 백본 모델(Claude)과 저렴한 탐색용 사이드카 모델(OpenAI)의 역할을 분리하는 것이다. 시스템은 이전 턴의 툴(Tool) 사용 내역을 분석해 태스크를 분류한다. 단순한 코드 읽기나 검색 같은 '탐색(Exploration)'은 사이드카로 라우팅하고, 실제 코드 수정 등 '행동(Action)'은 캐시가 웜업된 백본 모델로 처리한다. 특히 주목할 점은, 사이드카 모델이 행동 툴을 호출하려 할 때 이를 즉시 폐기하고 백본으로 재라우팅하는 '가드레일' 메커니즘이다. 이는 잦은 모델 스위칭이 유발할 수 있는 컨텍스트 표류(Context Drift)와 논리적 환각을 사전에 차단하는 매우 엄밀한 엔지니어링 접근이다.
이 두 가지 분석 데이터는 생성형 AI 파이프라인 설계에 명확한 결론을 내린다. 단순한 API 래퍼(Wrapper) 수준의 서빙 아키텍처는 대규모 프로덕션 트래픽 앞에서 예외 없이 무너진다. 신뢰성 있는 AI 시스템은 CPU 바운드 병목을 제거한 컴파일 언어 기반의 게이트웨이로 P99 지연 시간을 마이크로초 단위로 통제해야 하며, 동시에 프롬프트 캐싱과 태스크 기반 동적 라우팅을 결합해 토큰 효율성을 극대화해야 한다. '무지성' 하드웨어 스케일링이나 정적 라우팅에 의존하는 시대는 끝났다. 이제는 인프라의 메모리 풋프린트와 모델의 경제적 한계비용을 수치로 계산하고 검증하는 아키텍트만이 살아남을 것이다.