LLM 에이전트의 오케스트레이션 설계에서 '툴 호출(Tool Calling)' 아키텍처는 시스템의 레이턴시와 토큰 비용을 결정짓는 핵심 병목이다. 최근 기술 커뮤니티(dev.to 등)를 중심으로 Anthropic이 주도하는 모델 컨텍스트 프로토콜(MCP)과 전통적인 CLI 및 마크다운 기반의 Skills 아키텍처 간의 아키텍처 논쟁이 치열하게 전개되고 있다. 이는 단순한 개발 프레임워크 선호도의 차이가 아니다. 프로덕션 서빙 환경에서 시스템의 P99 지연 시간, $m \times n$ 통합 복잡도, 그리고 토큰 예산(Token Budget) 간의 정량적 트레이드오프를 어떻게 설계할 것인가에 대한 근본적인 데이터 파이프라인 최적화 문제다.
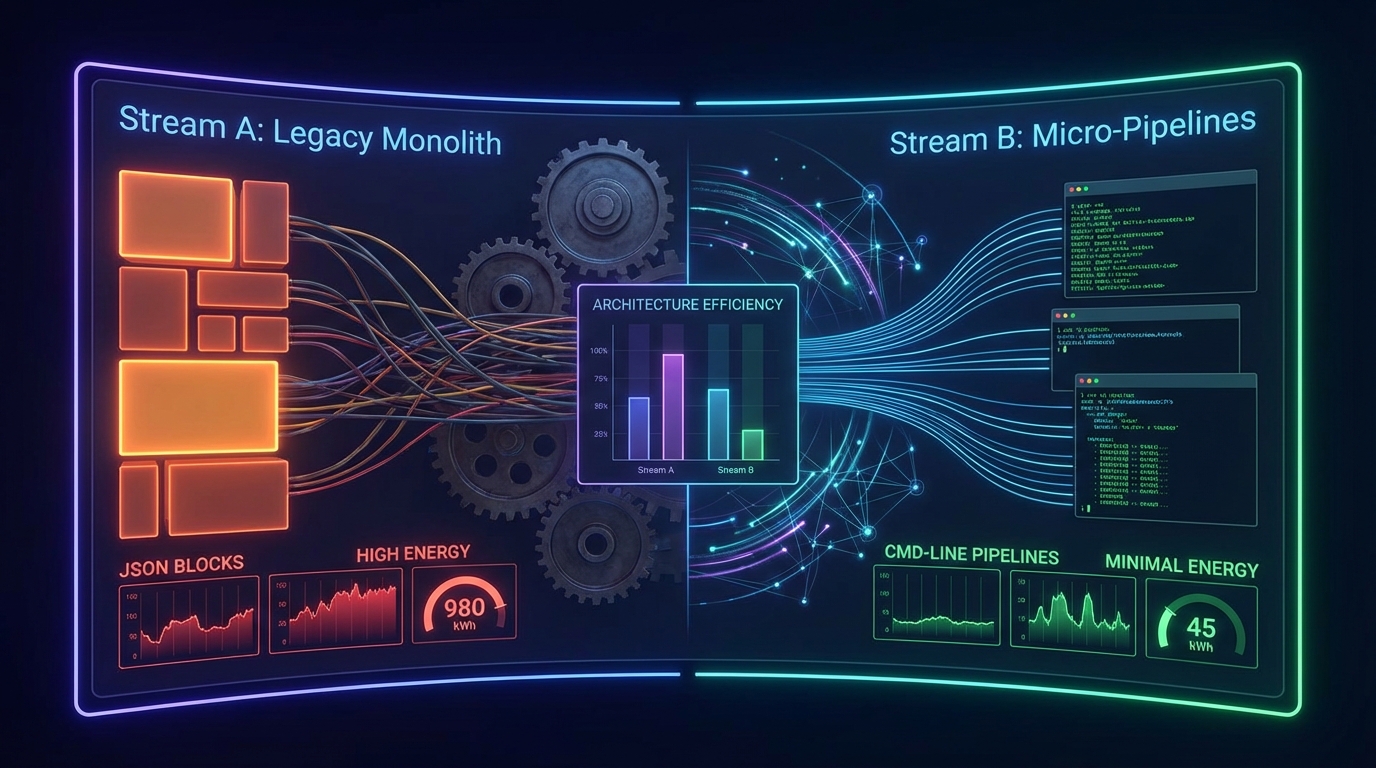
데이터 중심 관점에서 MCP가 직면한 가장 치명적인 기술적 결함은 '컨텍스트 오염(Context Pollution)'에 따른 토큰 오버헤드다. MCP는 단일 통합이라는 이상적인 청사진을 제시하지만, 에이전트 구동 초기 단계에서 연결된 모든 툴의 JSON-RPC 스키마를 컨텍스트 윈도우에 강제 주입(Injection)해야 하는 구조적 한계를 지닌다. 실제로 GitHub Copilot MCP 서버에 43개의 툴을 연결할 경우, 에이전트가 실질적인 추론을 시작하기도 전에 약 55,000개의 토큰이 소모된다. 이는 LLM이 문맥을 이해하고 정답을 도출하는 '유효 추론 구간(Smart Zone)'을 심각하게 잠식할 뿐만 아니라, 1M 당 입력 토큰(Input Token) 런타임 비용을 기하급수적으로 폭증시키는 원인이 된다.
반면, CLI와 Skills의 결합은 '점진적 발견(Progressive Discovery)'이라는 철저히 데이터 지향적인 리소스 최적화 전략을 보여준다. ScaleKit이 Claude Sonnet 모델을 대상으로 수행한 756회의 벤치마크 테스트 결과는 이 효율성의 격차를 극명하게 수치화한다. 1만 회 호출 기준 CLI 아키텍처의 비용은 약 3.20달러, 신뢰성(Reliability)은 100%를 기록한 반면, MCP는 약 55.20달러의 비용과 28%의 타임아웃(Timeout) 실패율을 보였다. 무려 17배의 비용 격차다. 이러한 결과는 LLM의 사전 학습(Pre-training) 데이터 분포에 기인한다. 모델은 수십 년간 축적된 Unix 문서와 bash 스크립트의 파이프(|) 연산 논리에는 고도로 최적화되어 있으나, 복잡하게 중첩된 MCP의 커스텀 JSON 스키마를 파싱하고 포맷팅하는 데에는 불필요한 컴퓨팅 리소스를 낭비하기 때문이다.
그렇다면 이처럼 명백한 정량적 비효율성에도 불구하고 MCP 아키텍처가 시장의 주목을 받는 이유는 무엇일까? 해답은 엔지니어링 비용의 경제성에 있다. 전통적인 커스텀 함수 호출(Function Calling) 방식은 $m$개의 LLM 애플리케이션과 $n$개의 툴을 연결할 때 $m \times n$의 통합 부채(Integration Debt)를 생성한다. 반면 MCP는 클라이언트-서버 구조를 통해 이를 $m + n$으로 선형화한다. 관련 연구에 따르면, MCP의 툴 자동 발견(Auto-discovery) 기능은 초기 개발 시간을 30%, 유지보수 비용을 25% 절감하는 것으로 나타났다. 즉, 현재의 아키텍처 선택은 '실행 시점의 토큰 인퍼런스 비용 극대화'와 '시스템 스케일링을 위한 엔지니어링 리소스 최소화' 간의 극단적인 트레이드오프를 요구하고 있다.
결국 프로덕션 레벨의 에이전트 시스템은 이 두 가지 극단을 조율하는 하이브리드 최적화 아키텍처로 수렴할 것이다. 실제로 최근 Anthropic은 MCP에 CLI의 '점진적 발견' 논리를 차용하여, 초기에는 툴의 이름과 짧은 설명(20~50 토큰)만 로드하고 호출 시점에만 전체 스키마를 주입하는 패치를 단행했다. 그 결과 50개 이상의 툴 환경에서 토큰 오버헤드가 85% 감소(77,000 $\rightarrow$ 8,700 토큰)했으며, Claude Opus의 툴 호출 정확도(Accuracy)는 49%에서 74%로 유의미하게 상승했다. 데이터 중심의 AI 아키텍트라면 맹목적으로 최신 프로토콜을 추종하기보다, 툴의 성격과 호출 빈도에 따라 정적 스키마 주입과 동적 컨텍스트 로딩을 비대칭적으로 라우팅하는 정밀한 비용-성능 통제 파이프라인을 구축해야 한다.