대다수의 AI 에이전트 프레임워크가 간과하는 치명적인 병목은 '세션 단절(Session Amnesia)'이다. Dev.to에 공유된 최근 아키텍처 사례들에 따르면, 뛰어난 추론 능력을 갖춘 Claude나 GPT 모델조차 세션이 재시작되면 컨텍스트 윈도우가 초기화된다. 이는 프로덕션 환경에서 단순한 불편함을 넘어, 동일한 아키텍처나 에러 히스토리를 반복 주입해야 하는 심각한 토큰 낭비(Token Waste)와 P99 지연 시간(Latency) 증가를 초래한다. 정량적 관점에서 보면, 매 세션마다 발생하는 램프업(Ramp-up) 비용은 시스템 전체의 추론 효율성을 떨어뜨리고 에이전트의 ROI를 급격히 하락시키는 주범이다.
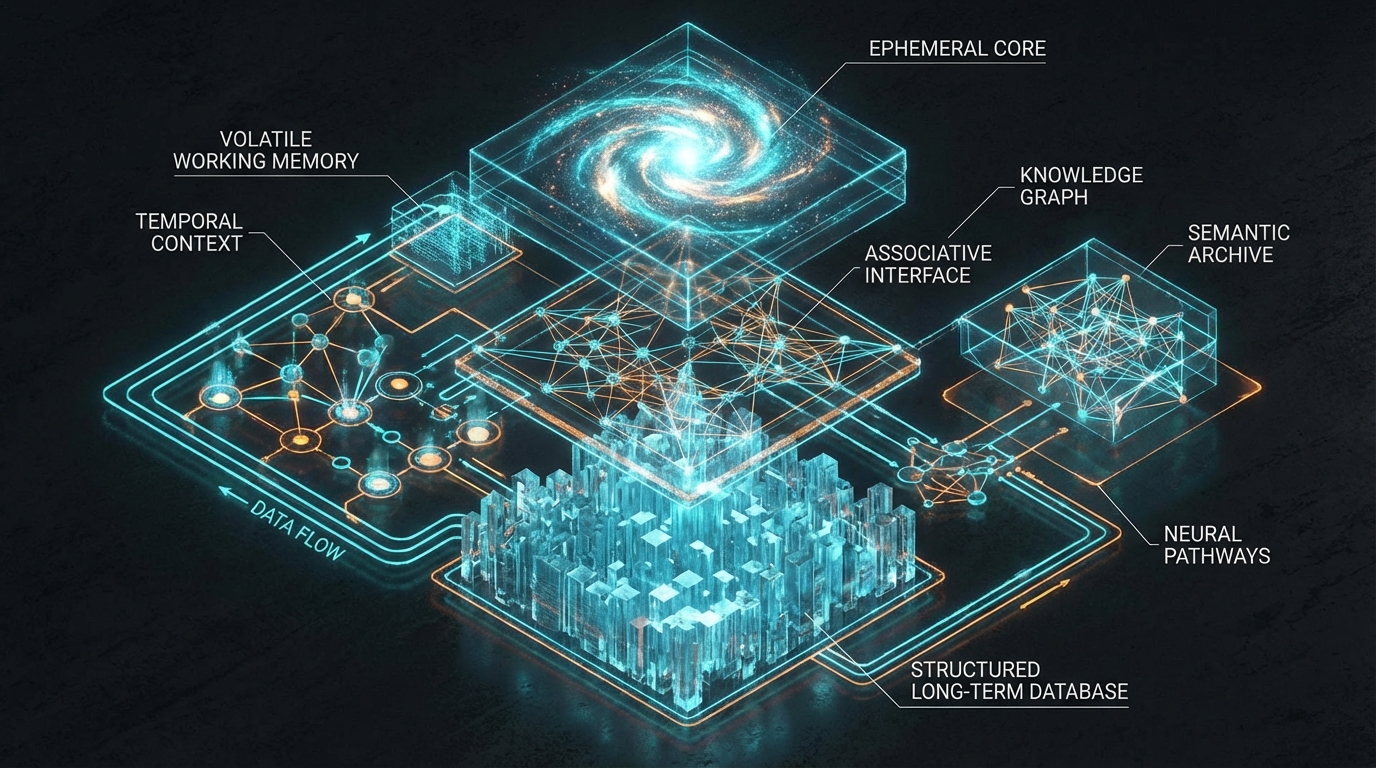
이를 해결하기 위해 현업에서는 상태 영속성(Persistent State)과 검색 파이프라인을 결합한 3계층 메모리 아키텍처가 표준 패턴으로 자리 잡고 있다. 첫째, 현재 세션의 '단기 컨텍스트(Ephemeral context)', 둘째, 스토리지에서 추출된 '작업 메모리(Working memory)', 셋째, 지속적으로 성장하는 '장기 기억(Long-term memory)'이다. 특히 오픈소스 MCP(Model Context Protocol) 서버인 'agent-knowledge' 사례는 시사하는 바가 크다. 이 시스템은 마크다운 기반의 지식 베이스를 Git으로 동기화하고, 과거 세션의 JSONL 트랜스크립트를 TF-IDF 알고리즘으로 색인화하여 검색 기반 메모리를 구현했다. 단순한 채팅 로그 저장이 아닌, 에이전트가 능동적으로 읽고 쓸 수 있는 구조화된 RAG 파이프라인을 구축한 것이다.
이 아키텍처의 핵심 효용은 '자동 증류(Auto-distillation)' 메커니즘을 통한 컨텍스트 최적화에 있다. 종료된 세션에서 유의미한 결정사항이나 에러 패턴을 자동으로 추출해 장기 기억으로 이관함으로써, 다음 세션의 프롬프트 길이를 획기적으로 줄인다. 데이터 분석가 관점에서 이는 입력 토큰을 최적화하고 모델의 어텐션(Attention) 오염을 막아 생성 품질(Generation Quality)을 높이는 명확한 인과관계를 갖는다. 또한, 시크릿 스크러빙(Secrets scrubbing) 기능을 통해 API 키 등의 민감 정보가 Git으로 푸시되는 것을 차단하는 점은, 엔터프라이즈 환경에서의 프로덕션 도입을 위해 반드시 요구되는 보안 통제 장치다.
"승리하는 에이전트는 더 똑똑한 모델을 쓰는 것이 아니라, 더 똑똑한 메모리를 쓴다"는 원문의 통찰은 데이터 중심 AI 시스템 설계의 본질을 관통한다. 앞으로의 AI 에이전트 성능 평가는 단일 모델의 MMLU 점수보다, 다중 세션에 걸친 메모리 Retrieval Accuracy와 비용-성능 트레이드오프 지표가 핵심이 될 것이다. 단순히 더 큰 컨텍스트 윈도우를 가진 모델로 스위칭하는 1차원적 접근을 넘어, MCP 기반의 영구적 메모리 I/O 파이프라인을 구축해 컨텍스트 오버헤드를 구조적으로 통제하는 것이 지속 가능한 에이전트 시스템을 완성하는 유일한 해법이다.