AI를 프론트엔드 개발에 쓰는 방법을 묻는 질문이 많아졌다. 그런데 솔직히 말하면, 대부분의 답변은 '어떤 도구를 쓰는가'에 멈춰 있다. Claude, Gemini, Cursor, Roo Code—나열은 쉽다. 하지만 진짜 질문은 다르다. 이 도구들을 어떤 역할에 배치하고, 그 구조가 비용과 품질에 어떤 영향을 미치는가. 두 가지 최근 글이 이 질문에 다른 각도에서 답하고 있어, 함께 읽을 때 흥미로운 그림이 나온다.
역할 분리 없이 AI 워크플로우는 없다
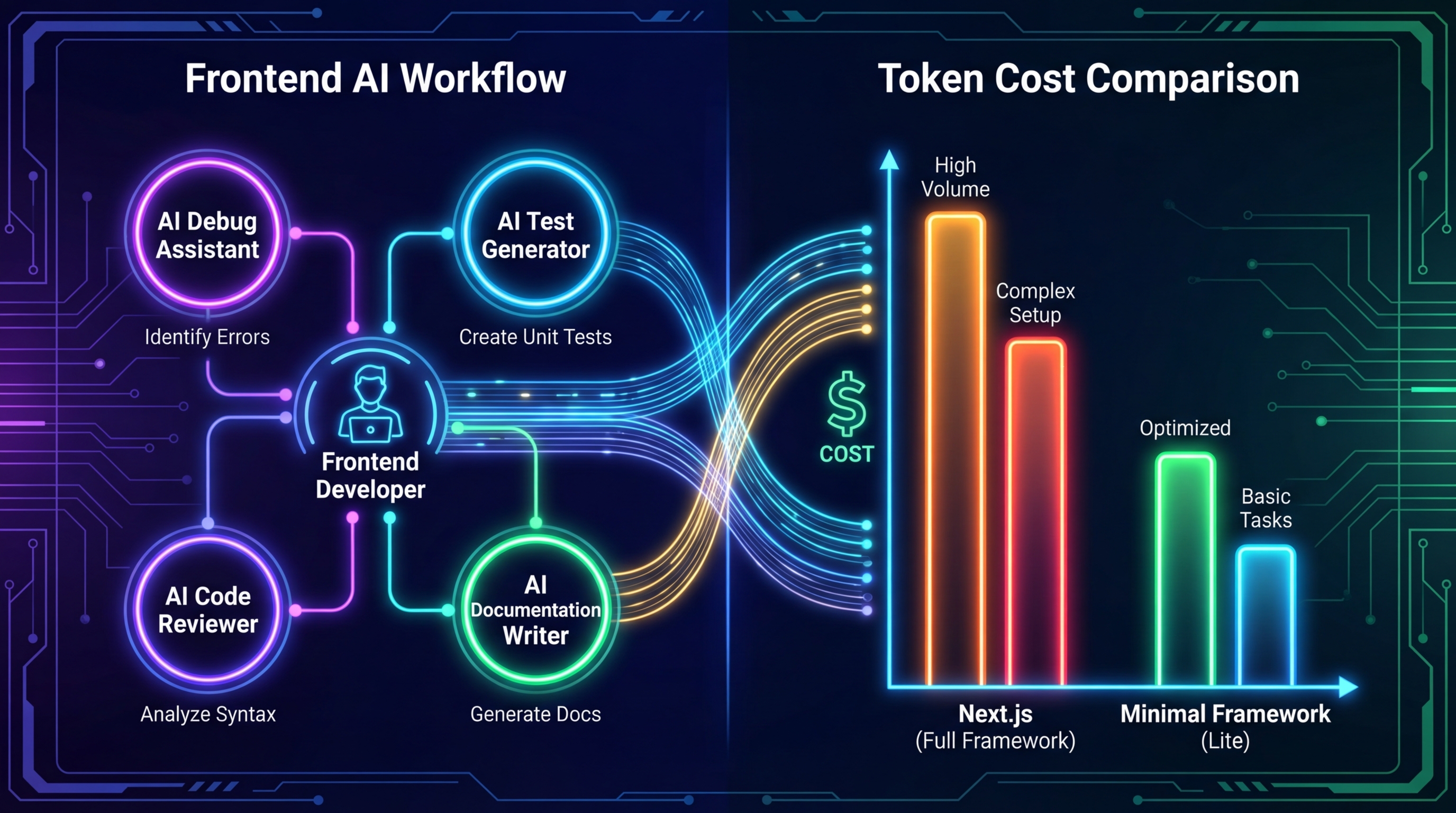
dev.to에 게재된 한 프론트엔드 엔지니어의 워크플로우 글은 인상적인 구조로 되어 있다. 단순히 '이럴 때 Claude를 쓴다'가 아니라, 업무 단계마다 AI의 역할과 인터랙션 방식을 다르게 설계했다는 점이 핵심이다. 디버깅 국면에서 AI는 일방적으로 답을 주는 오라클이 아니라, console.log를 전략적 위치에 추가하도록 유도하고 브라우저 DevTools 출력을 함께 해석하는 대화형 코딩 파트너로 작동한다. 런타임 에러는 컴파일 이후에 발생하기 때문에 정적 분석만으로는 잡히지 않는데, 이 반복적 대화 루프가 그 공백을 채운다.
코드베이스 품질 관리 국면에서는 역할이 또 달라진다. 방대한 프로젝트에서 AI에게 즉시 수정을 맡기는 것이 아니라, 먼저 전체를 읽고 개선 기회를 분석한 플래닝 문서를 만들게 한다. 네이밍 컨벤션, 아키텍처 일관성, 코딩 스타일—이 일관성은 사실 사람보다 AI 에이전트가 다음 번에 올바른 코드를 생성하는 데 더 직접적으로 영향을 미친다. 잘 정돈된 코드베이스는 AI 협업의 전제 조건이기도 하다.
유닛 테스트 작성도 마찬가지다. 프론트엔드에서 테스트 셀렉터 찾기가 어려운 이유는 디자인 시스템이 복잡한 HTML 구조를 렌더링하기 때문인데, AI는 이 부분에서 특히 잘 작동한다. 함수나 컴포넌트를 스캔해 테스트와 목(mock)을 통째로 작성하는 일—사람에게는 시간이 오래 걸리고 흥미도 낮은 작업—이 AI에게는 오히려 최적의 역할이다. 지루한 작업을 위임하고, 판단이 필요한 영역은 직접 쥐는 것. 이것이 이 워크플로우의 철학이다.
그런데, 그 AI 호출 비용은 얼마인가
여기서 두 번째 글이 끼어든다. Wasp 팀이 수행한 벤치마크를 분석한 글인데, 결론이 꽤 도발적이다. 동일한 기능을 Claude Code로 구현할 때, Next.js는 Wasp보다 80% 더 비쌌다. 총 비용 $5.17 대 $2.87, 토큰 수 4.0M 대 2.5M. 그런데 AI가 실제로 작성한 코드량은 거의 같았다(5,395 vs 5,416 토큰).
이유는 단순하다. LLM은 매 호출마다 코드베이스 컨텍스트를 처음부터 다시 읽는다. 코드베이스가 클수록 매 턴의 비용이 높아진다. Next.js는 auth, 라우팅, 미들웨어가 파일 여러 곳에 분산되어 있고, Wasp는 동일한 기능을 선언형 설정 10줄로 압축한다. 같은 결과물, 4배의 토큰 차이. 캐시 생성 비용만 113% 더 많이 들었다.
더 중요한 건 이게 선형으로 악화되지 않는다는 점이다. 기능이 누적될수록 컨텍스트 윈도우 부담이 늘고, 연구에 따르면 AI 성능은 컨텍스트가 꽉 차기 훨씬 전부터 저하된다. 비용만 올라가는 게 아니라 결과물 품질도 같이 나빠진다. 이건 프레임워크 취향의 문제가 아니라 구조적인 경제학의 문제다.
두 관점을 겹쳐보면 보이는 것
이 두 글을 함께 읽으면 하나의 설계 원칙이 도출된다. AI 워크플로우는 역할 설계와 컨텍스트 효율을 동시에 고려해야 한다. 역할 설계만 잘해도, 코드베이스가 불필요한 보일러플레이트로 가득 차 있으면 호출마다 낭비가 생긴다. 반대로 코드베이스를 압축해도, AI에게 엉뚱한 역할을 맡기면 품질이 나빠진다.
실무에서 바로 적용해볼 수 있는 체크포인트 세 가지가 있다. 첫째, 지금 코드베이스의 토큰 수를 측정해보자. find . -name "*.ts" -o -name "*.tsx" | xargs wc -c 한 줄로 AI 비용의 대략적인 기준선을 알 수 있다. 둘째, 보일러플레이트 비율을 점검하자. 비즈니스 로직 대비 '연결 코드(glue code)'가 많을수록 AI 경제성이 나빠진다. 셋째, 디버깅·테스트·리뷰·문서화 각 단계에서 AI에게 맡길 역할을 명시적으로 구분하자. 일관성 없는 코드베이스는 AI가 다음 기능을 잘못 생성하게 만드는 직접적 원인이다.
AI 협업의 다음 질문
흥미로운 건, 사람이 읽기 좋은 코드—명시적이고, 자기 서술적이고, 장황한—가 AI에게는 비싼 코드라는 역설이다. 우리가 '마법'이라고 불렀던 추상화, 즉 선언형 설정과 컨벤션 기반 프레임워크가 이제는 토큰 경제학 측면에서 진짜 우위를 가지게 됐다. 2년 전만 해도 없던 프레임워크 선택 기준이 하나 추가된 것이다.
앞으로 프론트엔드 엔지니어가 설계해야 할 질문은 점점 명확해지고 있다. '어떤 AI 도구를 쓸 것인가'가 아니라, '이 코드베이스에서 AI가 매 호출마다 읽어야 할 컨텍스트를 어떻게 줄일 것인가', 그리고 '각 개발 단계에서 AI에게 정확히 어떤 역할을 맡길 것인가'. 도구가 아니라 구조의 문제다.