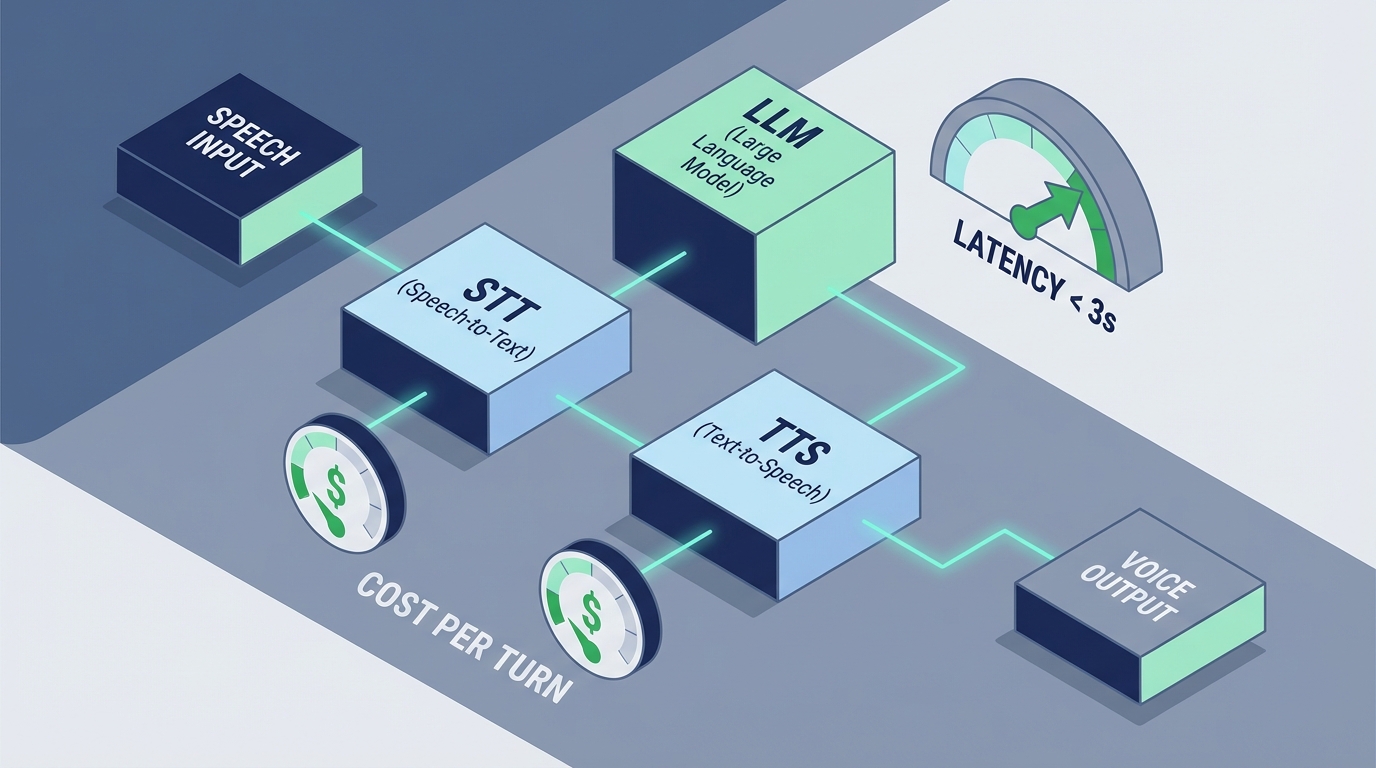
음성/실시간 대화 제품에서 COGS는 더 이상 백오피스 숫자가 아니다. 응답 지연 1~2초, 한 턴당 과금의 변동성, 그리고 재시도(“다시 말해요”)가 곧바로 전환율과 리텐션을 깎아 먹는다. 문제는 많은 팀이 ‘모델 단가’만 보고 의사결정한다는 것. 실제 퍼널에서 중요한 건 턴당 총비용(오디오→STT→LLM→TTS)과 그 변동폭(P90), 그리고 그 비용을 전제로 설계된 CTA/세션 길이다.
dev.to의 Xaden 글은 이 관점을 로컬 스택으로 밀어붙인다. Whisper.cpp(온디바이스 STT) + Ollama(로컬 추론) + Kokoro TTS(ONNX, 상시 서버)로 API 키/토큰 과금 없이 음성 대화를 3초 이내로 맞춘다. 핵심은 “클라우드가 비싸서 로컬”이 아니라, 지연·프라이버시·비용이 선형으로 커지는 구조 자체가 퍼널을 망친다는 진단이다. 특히 TTS에서 ‘콜드 스타트 9초’가 발생하자, PyTorch를 ONNX로 바꾸고 프로세스를 상주시켜 ~300ms로 30배 줄인 부분은, 음성 제품의 병목이 모델이 아니라 프로덕션 오버헤드일 때가 많다는 걸 보여준다.
반대로 클라우드의 최신 음성 모델은 품질/기능을 더 밀어준다. 구글 블로그의 Gemini 3.1 Flash Live는 실시간 대화 리듬, 톤 이해, 다국어 확장, 그리고 SynthID 워터마크 같은 신뢰 레이어를 전면에 둔다(출처: blog.google). 즉 선택지는 “로컬 vs 클라우드”가 아니라, 어떤 퍼널 구간을 어떤 비용 구조로 서빙할 것인가다. 온보딩/무료 구간은 로컬로 ‘마찰과 비용’을 줄이고, 고가치 액션(구매 상담, 복잡한 작업 실행)은 클라우드로 ‘성공률’을 끌어올리는 식의 하이브리드가 현실적이다.
여기에 ‘싼 모델의 함정’이 겹친다. dev.to의 다른 글이 인용한 2026년 연구는, 표면 단가가 낮은 reasoning 모델이 thinking tokens를 과다 소모해 실제 비용이 더 비싸지는 ‘Price Reversal’(최대 28배)을 지적한다(출처: dev.to/Stanford·Berkeley·CMU·MSR 연구). 음성 퍼널에선 이게 더 치명적이다. 이유는 간단하다: 음성은 한 번의 실패가 재질문→재추론→재합성으로 이어져 턴 수와 비용을 기하급수로 늘리고, 사용자는 “답답함”으로 이탈한다. 결국 모델 단가 비교가 아니라 정답당 비용(cost-per-correct) + 턴당 지연 + 변동성이 퍼널 KPI를 결정한다.
시사점은 명확하다. 첫째, 음성 제품의 퍼널을 ‘기능 플로우’가 아니라 COGS 플로우로 다시 그려야 한다. 예: (1) 첫 3턴은 로컬(고정비/0변동비)로 “첫 성공”을 빠르게 제공해 D1을 지키고, (2) 결제 직전/고의도 구간만 클라우드(가변비)로 라우팅해 전환율을 담보하며, (3) 이후 반복 사용 구간은 요약/캐시/짧은 응답 정책으로 ARPU를 방어한다.
둘째, 음성 UX에서 비용 최적화는 곧 실험 설계다. 다음 3가지는 바로 돌릴 수 있다. (A) 턴 예산 실험: 세션당 최대 턴/초를 제한하는 대신, 응답을 더 짧고 확실하게 만들었을 때 전환이 오르는지(A/B). (B) 라우팅 실험: “고객 불만/구매 신호/명확한 엔티티 포함” 같은 조건에서만 고성능 모델로 스위칭했을 때, cost-per-correct와 구매 전환이 동시에 개선되는지. (C) TTS 콜드스타트 제거: Xaden 사례처럼 상시 프로세스/ONNX 전환만으로도 체감 지연을 줄여, 동일 트래픽에서 재질문율과 이탈률이 얼마나 감소하는지.
전망: 음성 AI는 곧 ‘대화 품질 경쟁’에서 ‘대화 단위 경제성 경쟁’으로 넘어간다. 실시간 음성은 텍스트보다 지연과 변동성에 훨씬 민감하고, 그래서 COGS 관리가 곧 퍼널 설계가 된다. 앞으로 승자는 두 부류다. (1) 로컬/온디바이스 스택으로 무료 구간을 싸게 열어 CAC를 낮추는 팀, (2) 클라우드의 신뢰/다국어/고난도 작업을 필요한 순간에만 호출해 LTV를 키우는 팀. 결국 질문은 하나다: “이 음성 한 턴이 전환을 만든다면, 그 턴의 P90 비용과 3초 예산을 우리가 통제하고 있는가?”