단일 대형 언어 모델(LLM)에 모든 의사결정을 위임하는 에이전트 시스템은 프로덕션 환경에서 빠르게 한계에 봉착한다. 복잡한 다학제적 태스크를 단일 프롬프트로 처리할 때 발생하는 '인지적 과부하(Cognitive Overload)'는 필연적으로 추론의 깊이를 얕게 만들고, 구조적 환각(Hallucination)을 유발하며, 무엇보다 컨텍스트 윈도우의 비효율적 낭비로 인해 토큰 비용을 기하급수적으로 증가시킨다. 최근 dev.to에 공유된 'Nous Ergon'의 자동 트레이딩 시스템 사례와 'Manager-Worker' 협업 모델에 관한 분석은, 이러한 단일 LLM의 한계를 하이브리드 라우팅과 엄격한 인지적 분업(Cognitive Division of Labor)을 통해 어떻게 정량적으로 통제할 수 있는지 명확한 실증 데이터를 제시한다.
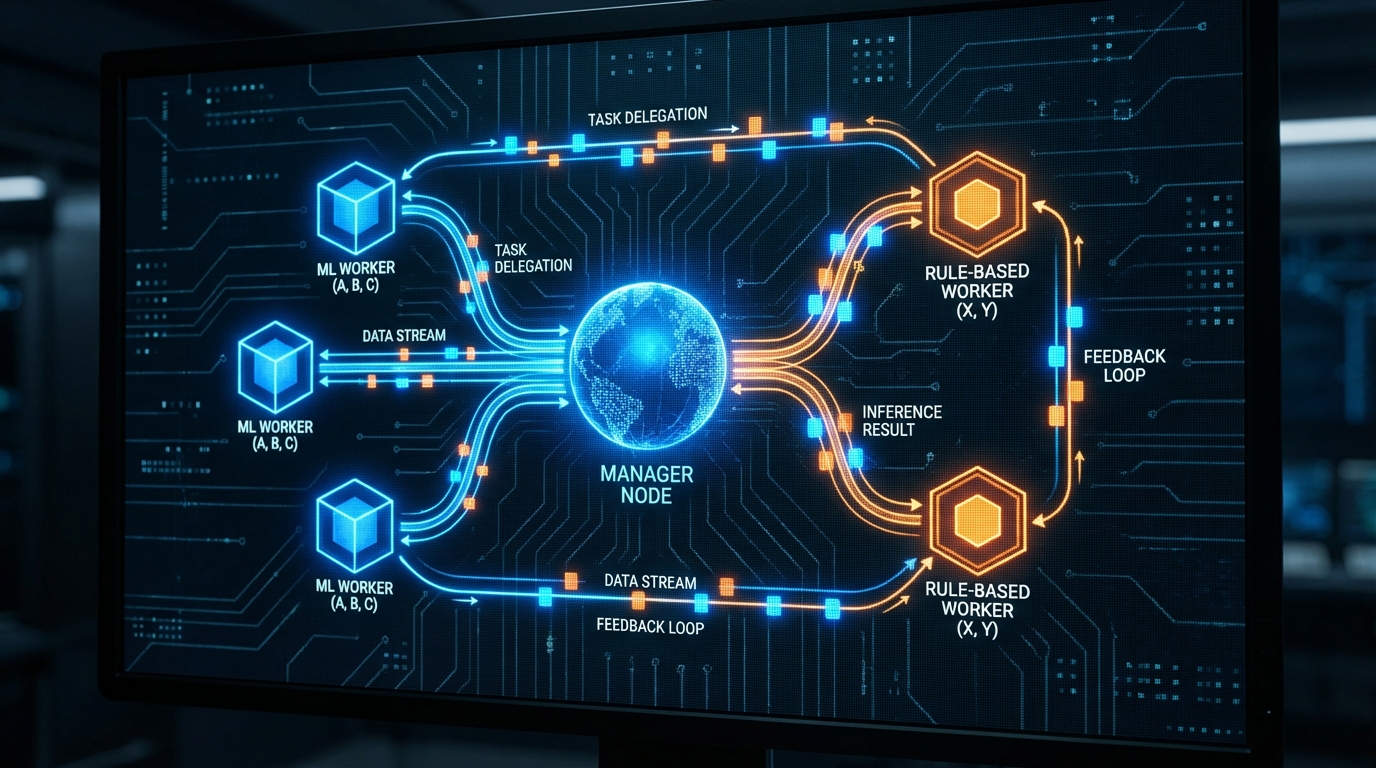
가장 주목해야 할 아키텍처적 결단은 비용과 연산의 '디커플링(Decoupling)'이다. Nous Ergon 시스템은 LLM을 정밀한 수치 예측이나 실행에 투입하는 순진한(naive) 접근을 배제하고, 전체 파이프라인을 Research(LLM), Prediction(머신러닝), Execution(결정론적 룰)의 3계층으로 철저히 분리했다. LangGraph로 오케스트레이션되는 다중 Claude 에이전트는 비정형 데이터(뉴스, 애널리스트 리포트)를 분석하여 매력도 점수(0~100)를 산출하는 데만 사용된다. 이후의 단기 모멘텀 예측은 LightGBM 앙상블 모델이 담당하며, 최종 실행은 하드코딩된 리스크 관리 룰이 통제한다. 이러한 구조적 분리는 ML 모델의 파라미터 튜닝이나 백테스팅을 수만 번 반복하더라도 추가적인 LLM API 호출 비용이 발생하지 않게 만드는 핵심적인 토큰 효율성 전략이다.
이러한 하이브리드 접근법은 에이전트 생태계에서 가장 프로덕션 친화적인 '매니저-워커(Manager-Worker)' 라우팅 패턴의 확장으로 볼 수 있다. 매니저 에이전트는 직접 작업을 수행하지 않고 의도를 분석해 하위 워커(Data, Research, Strategy 등)에게 태스크를 병렬로 위임한다. 이 패턴의 가장 큰 정량적 이점은 실패의 격리(Isolation of failures)와 P99 지연 시간의 최적화다. 특정 워커의 실행이 실패하더라도 전체 시스템이 다운되지 않으며, 병렬 실행을 통해 전체 체인(Chain)의 응답 속도를 방어할 수 있다. 단, 다중 에이전트 시스템은 결코 '무료'가 아니다. 에이전트 간의 조정 오버헤드(Coordination overhead)가 발생하기 때문에, 매니저의 라우팅 프롬프트는 반드시 엄격한 JSON 스키마 기반의 출력과 성공 기준을 정의하도록 통제되어야 한다.
시스템의 각 구성 요소를 독립적으로 평가(Independent Evaluation)하는 검증 파이프라인의 존재 여부도 중요하다. Nous Ergon의 경우, ML 모델의 가중치를 프로덕션에 배포하기 전에 Information Coefficient (IC) > 0.03이라는 명확한 금융 통계적 임계치를 요구한다. LLM 기반의 Research 에이전트가 산출한 정성적 시그널과 ML의 정량적 예측력을 분리하여 측정함으로써, RAG나 에이전트 시스템에서 흔히 발생하는 '무엇이 성능을 개선했는지 알 수 없는' 블랙박스 현상을 방지한다. 워커 간의 충돌 시 결과값을 단순 평균 내지 않고 매니저가 증거를 기반으로 갈등을 해결(Conflict Resolution)하는 과정 역시, 결과의 사실성(Factuality)과 추적 가능성을 높이는 데 기여한다.
결론적으로, 프로덕션 레벨의 생성형 AI 시스템은 무질서한 창발성(Emergent chaos)을 기대하는 방향이 아니라, 확률적 모델(LLM)과 확정적 모델(ML/Rules) 간의 경계를 통제하는 '통제된 위임(Controlled delegation)' 방향으로 진화하고 있다. A/B 테스트와 AgentOps 추적을 통해 각 노드의 레이턴시와 비용 트레이드오프를 식별하고, 비싼 LLM의 개입을 최소화하면서도 시스템의 총체적 추론 능력을 극대화하는 라우팅 설계야말로 AI 엔지니어링의 핵심 경쟁력이 될 것이다.