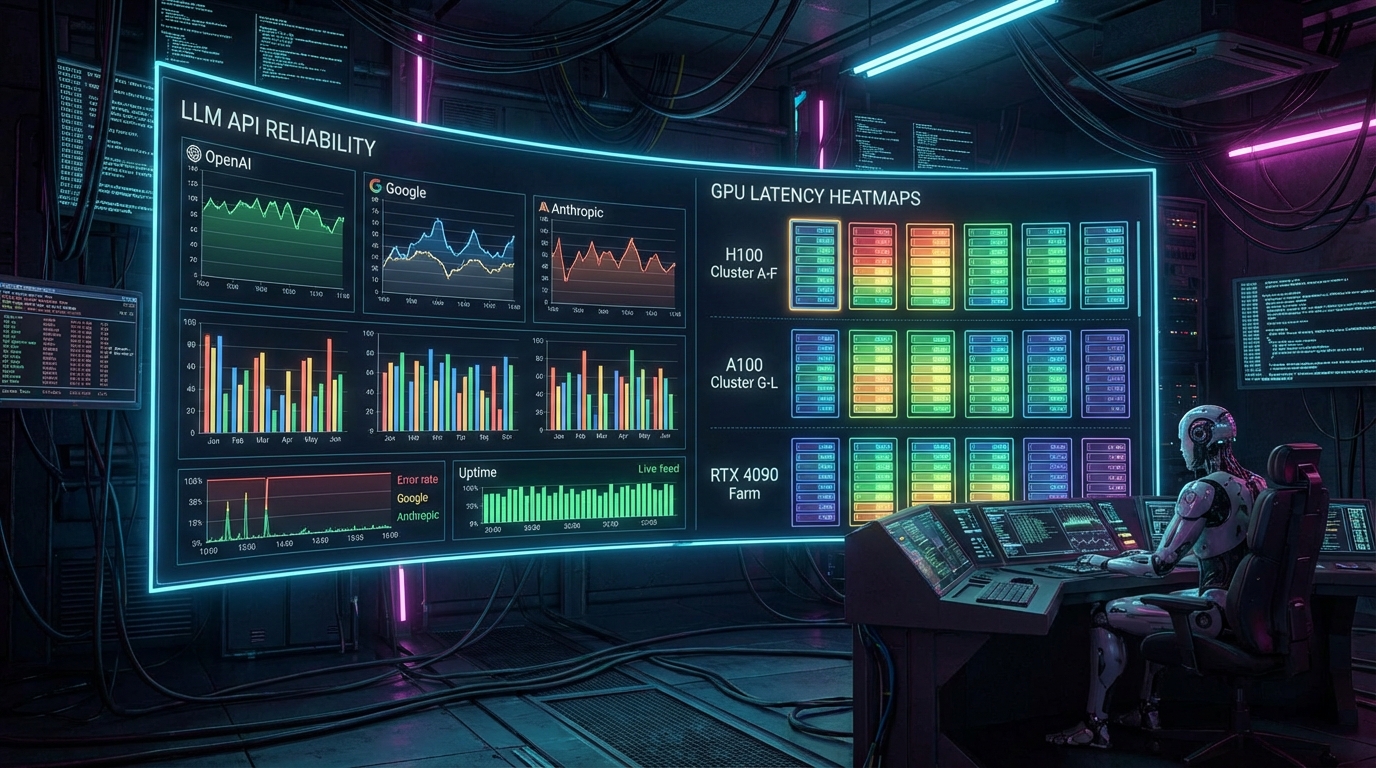
[핵심 이슈] 프로덕션 에이전트의 환상과 API 신뢰성의 정량적 격차 대부분의 에이전트 프레임워크 튜토리얼은 "OpenAI API 키를 입력하라"는 식으로 시작하지만, 실제 프로덕션 환경의 P99 지연 시간(Latency)과 시스템 신뢰성을 측정해보면 이는 지극히 위험한 접근이다. 최근 dev.to에 공개된 Rhumb의 LLM API 에이전트 실행 신뢰성 벤치마크(AN Score)에 따르면, Anthropic이 8.4점으로 1위를 기록한 반면, 생태계 점유율이 가장 높은 OpenAI는 6.3점에 그쳤다. 이 2.1점의 격차는 98%의 통계적 신뢰도(Confidence)를 가지며, 이는 단일 LLM에 종속된 에이전트 시스템이 실제 서비스 환경에서 직면하게 될 장애 복구(Error Recovery)와 처리율 제한(Rate Limit) 병목이 공급자에 따라 극명하게 갈림을 시사한다.
[맥락 해석] 생태계 프리미엄의 함정과 공급자별 마찰 비용(Friction Cost) 데이터를 더 깊이 파고들면 각 공급자 API의 구조적 한계가 드러난다. OpenAI(실행 점수 7.1)의 가장 큰 병목은 과거 지출액에 연동된 스로틀링(Spend-gated rate tiers)이다. 신규 연동 시 보이지 않는 처리율 제한에 부딪히며, 복잡한 조직/프로젝트 키 계층 구조가 마찰 비용을 증가시킨다. 반면, Anthropic(실행 점수 8.8)은 툴 호출(Tool-use) 스키마의 일관성과 구조화된 에러 응답 측면에서 에이전트 친화적이지만, 부하 발생 시 적응형 백오프(Adaptive Backoff) 구현이 필수적이라는 제약이 있다. Google AI(7.9점)는 모달리티 확장에 유리하나, AI Studio, Vertex AI, Gemini API라는 세 가지 표면(Surface)의 파편화로 인해 인증(Auth) 아키텍처를 재작업해야 하는 치명적인 엔지니어링 오버헤드를 발생시킨다.
[시사점] 실시간 환각 가드레일의 레이턴시(Latency) 최적화와 컴퓨팅 트레이드오프 API 수준의 실행 신뢰성을 확보하더라도, 생성된 결과의 사실성(Factuality) 검증은 별개의 문제다. 이를 통제하기 위해 등장한 오픈소스 가드레일 'Director-Class AI'의 벤치마크 데이터는 실시간 환각(Hallucination) 탐지의 비용-성능 트레이드오프를 명확히 보여준다. 스트리밍되는 토큰을 실시간으로 감시해 NLI(자연어 추론) 기반으로 환각을 차단할 때, L40S GPU 환경(FP16, Batch=32)에서는 0.5ms/pair의 초저지연을 달성하지만, CPU(ONNX) 환경에서는 383ms/pair로 급증한다. 이는 사용자 체감 지연 시간에 치명적인 영향을 미치며, 90.7%의 E2E 탐지율(Hybrid 모드 기준)을 프로덕션에서 달성하기 위해서는 가드레일 전용 GPU 리소스 할당이라는 명시적인 비용 지출이 필수적임을 증명한다.
[전망] 데이터 중심의 에이전트 시스템 아키텍처 재설계 결과적으로, 신뢰성 있는 AI 에이전트 구축은 더 똑똑한 모델을 고르는 단편적인 문제가 아니다. 트래픽 스파이크 시 Anthropic의 백오프 로직을 처리하고, OpenAI의 스로틀링을 우회하기 위한 동적 라우팅(Dynamic Routing) 전략이 시스템 기저에 설계되어야 한다. 동시에 생성 품질을 보장하기 위해 RAG 지식 기반과 결합된 NLI 가드레일을 도입하되, 이에 수반되는 추론 지연 시간을 통제할 GPU 인프라 예산을 정량적으로 산정해야 한다. 성능, 레이턴시, API 안정성이라는 세 가지 변수를 독립적으로 측정하고 제어할 수 있는 데이터 파이프라인 없이는, 프로덕션 레벨의 에이전트 오케스트레이션은 불가능하다.