"빠른 것 같다"는 느낌이 지표가 되는 순간, 팀은 길을 잃는다
AI 코딩 도구 도입을 검토하는 테크 리드라면 한 번쯤 이 질문을 받았을 것이다. "도입하면 얼마나 빨라지나요?" 그리고 솔직히, 나도 한때 체감 속도로 답했다. 그게 문제였다.
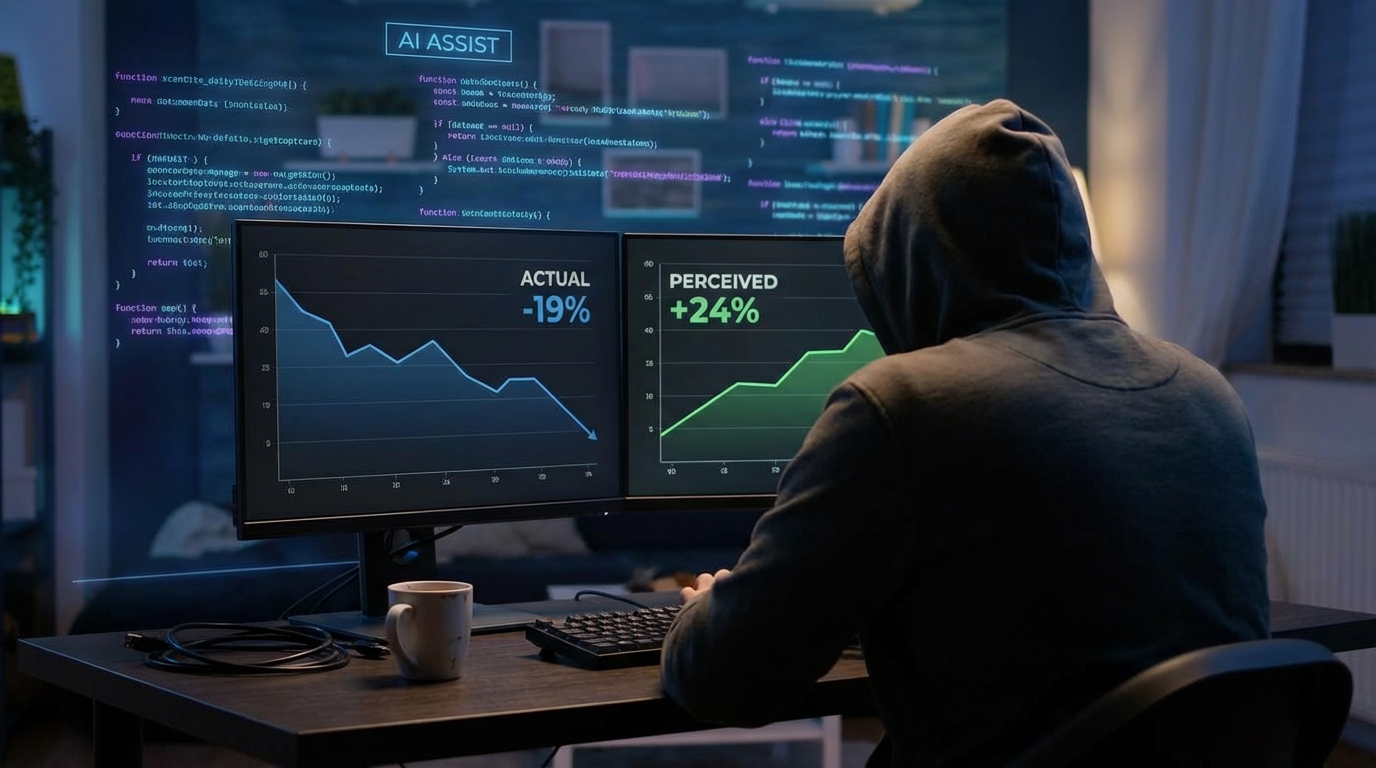
METR 연구가 최근 공개한 데이터는 꽤 불편하다. 개발자들은 AI 코딩 도구를 쓸 때 평균 24% 빨라졌다고 인식했지만, 실제 측정값은 19% 느려진 것으로 나타났다. 인식과 현실 사이의 격차가 43포인트다. 이 연구가 특히 눈길을 끄는 건 실험 조건이 현실과 가깝다는 점이다. 자신이 잘 아는 오픈소스 저장소에서, 스스로 고른 태스크를 수행한 숙련된 개발자들이 대상이었다. 통제된 실험실이 아니었다.
왜 숙련된 개발자일수록 AI의 이점이 줄어드나
직관과 반대다. 보통은 "AI 도구를 더 잘 다루는 고수가 더 많이 얻는다"고 생각한다. Addy Osmani(Google Chrome 엔지니어링 리드)의 주장도 그랬고, 나도 팀에 그렇게 설명했다. METR 연구는 이 직관에 제동을 건다.
핵심은 천장 효과(ceiling effect)다. 코드베이스를 이미 충분히 이해하고 있는 개발자는 AI의 기여가 오히려 마이너스다. 직접 타이핑하는 속도보다, 프롬프트 작성 → 대기 → 출력 검토 → 수락/거부 → 수정으로 이어지는 협업 루프의 오버헤드가 더 크기 때문이다. AI가 가져오는 건 "내가 모르는 것에 대한 광범위한 학습 데이터"인데, 이미 다 아는 상황에서 그 가치는 0에 수렴한다.
반대로 낯선 코드베이스를 탐색하거나, 처음 쓰는 라이브러리의 보일러플레이트를 생성하거나, "이 에러가 뭐야?"를 묻는 이해 및 탐색 태스크에서는 AI의 효용이 명확하다. GDC 2026 보고서에서 게임 개발자의 81%가 AI를 리서치·브레인스토밍에 쓰고 코드 구현에 쓰는 비율은 47%에 그친다는 수치도 같은 방향을 가리킨다. 현장 개발자들은 이미 몸으로 알고 있는 것이다.
AI 생성 코드의 품질 리스크: 1.7배 버그율을 어떻게 볼 것인가
속도만의 문제가 아니다. CodeRabbit의 470개 GitHub 저장소 분석에 따르면, AI가 작성한 코드는 인간 코드보다 이슈가 1.7배 많다. 로직 에러는 1.75배, 불필요한 I/O 연산은 8배, XSS 취약점은 2.74배다. Cortex 2026 Engineering Benchmark는 AI 도구 도입 팀에서 PR당 인시던트가 23.5% 증가하고 변경 실패율이 약 30% 상승했다고 보고한다.
여기서 중요한 건 이 숫자를 AI 도구 불용의 근거로 쓰지 않는 것이다. 올바른 독해는 이렇다. AI 코드는 주니어 개발자의 PR처럼 다뤄야 한다. 빠르게 훑는 것으로는 부족하다. 이 전제 없이 AI 코드를 프로덕션에 밀어 넣으면, 속도 이득은 이후의 디버깅·보안 패치·인시던트 대응 비용에 고스란히 반납된다.
Autopilot 모드 실습이 보여주는 다음 국면
GitHub Copilot이 최근 VS Code에 Autopilot 모드(현재 Preview)를 출시했다. 기존의 함수 단위 제안과 달리, 단일 프롬프트 하나로 태스크 목록 구성 → 코드 구조 구현 → 터미널 명령 실행 → 오류 자가 디버깅 → 결과 전달까지 end-to-end로 처리한다. 실습 리뷰에서는 Claude Opus 4.6을 백엔드로 연결해 WordPress 플러그인 개발에 적용했고, 코드 생성 정밀도 면에서 긍정적인 결과가 보고됐다.
흥미로운 건 리뷰어의 반응이다. "한 줄도 직접 타이핑하지 않아도 된다는 게 약간 등골 서늘하다." 이 감각은 단순한 감탄이 아니다. Autopilot 모드는 AI를 자율 실행 에이전트로 격상시킨다. 이 국면에서 19% 느려짐이나 1.7배 버그율은 더 이상 개별 제안 단위의 문제가 아니라, 시스템 전체 출력의 품질 문제로 증폭된다. 제어 지점이 없으면, 빠름의 규모도 리스크의 규모도 동시에 커진다.
LLM 코드 리뷰 벤치마크: AI로 AI를 견제하는 구조
그렇다면 AI가 만드는 품질 리스크를 AI로 통제할 수 있을까. 54개 실제 PR, 247개 확인된 이슈를 대상으로 한 LLM 코드 리뷰 벤치마크 결과는 이 가능성을 실측한다.
| 모델 | F1 점수 | 실행 가능성(1-5) |
|---|---|---|
| Claude Sonnet 4.5 (extended thinking) | 80.2% | 4.3 |
| GPT-4o | 77.7% | 4.1 |
| Claude Sonnet 4.5 (standard) | 78.2% | 4.2 |
| Gemini 2.5 Pro | 74.7% | 3.9 |
| DeepSeek V3 | 70.1% | 3.6 |
Claude Sonnet 4.5의 extended thinking 모드가 F1 80.2%로 선두다. 주목할 건 단순 탐지율이 아니라 실행 가능성(actionability) 점수다. "버그가 있을 수 있습니다"가 아닌, 무엇이 왜 문제이고 어떻게 고쳐야 하는지를 설명하는 능력. 이 차이가 LLM 코드 리뷰를 실제 워크플로우에 붙일 수 있느냐 없느냐를 가른다. 80% 탐지율이 완벽하진 않지만, PR 당 리뷰 오버헤드를 줄이면서 AI 생성 코드의 1.7배 버그율을 1차 필터링하는 용도로는 충분히 실용적인 수치다.
테크 리드를 위한 ROI 판단 프레임
세 개의 데이터를 조합하면 팀 도입 결정을 위한 프레임이 나온다.
1. 태스크 유형으로 AI 사용 범위를 먼저 구획하라. 자신이 잘 아는 코드의 리팩토링에 AI를 쓰면 METR 연구의 19% 감속이 현실이 된다. 낯선 라이브러리 탐색, 보일러플레이트 생성, 코드 이해("이 함수 설명해줘")에는 투입 대비 효용이 높다. 태스크 유형 없이 "AI 쓰기"를 권장하는 팀은 인식 격차만 키운다.
2. AI 생성 코드에 리뷰 레이어를 반드시 붙여라. Autopilot처럼 자율도가 높아질수록 이 원칙이 더 중요해진다. LLM 기반 코드 리뷰를 CI 파이프라인에 연결하면, AI가 만든 코드를 다시 AI가 1차 검수하는 구조를 만들 수 있다. 완벽하지 않지만, 아무것도 없는 것보다는 1.7배 버그율을 구조적으로 낮출 수 있다.
3. 체감이 아니라 측정으로 ROI를 검증하라. Stack Overflow 2025 설문에서 AI 도구 신뢰도는 40%에서 29%로 하락했고, 46%의 개발자가 정확도를 불신한다. 그러면서도 도구 사용률은 올라간다. 이 모순은 팀 내에도 그대로 재현된다. 태스크 완료 시간, PR당 리뷰 코멘트 수, 인시던트 빈도를 AI 도입 전후로 추적하지 않으면, 24% 빨라진 것 같다는 팀원의 체감이 유일한 지표가 된다.
도구는 더 강력해진다. 측정 체계를 먼저 만들어라
Autopilot 같은 에이전트 모드는 앞으로 더 빠르게 고도화될 것이다. 모델 품질도 올라간다. 하지만 METR 연구가 짚는 핵심은 기술 수준이 아니다. 개발자가 AI의 도움을 평가하는 능력 자체에 구조적 맹점이 있다는 것이다. 도구가 좋아질수록 이 맹점을 인식하는 게 더 중요해진다.
팀에 AI 도구를 투입하기 전에, 혹은 이미 투입했다면 지금이라도, 측정 체계를 먼저 설계하라. 어떤 태스크에서 쓰는지, 완료 시간은 어떻게 변했는지, 품질 지표는 어디로 움직이는지. 그 데이터가 쌓여야 "AI 도입 ROI가 있다"고 팀 안팎에 설명할 수 있고, 그 설명이 다음 의사결정의 신뢰를 만든다.