도구가 넘쳐나는 시대, 진짜 질문은 '뭘 쓸까'가 아니다
2026년 현재 AI 코딩 어시스턴트 시장은 연 50억 달러를 넘어섰고, 전문 개발자의 75% 이상이 이미 어떤 형태로든 AI 도구를 쓰고 있다(dev.to 'Best AI Coding Assistants in 2026' 리포트 기준). 문제는 선택지가 50개를 넘어섰다는 것이다. 단순 자동완성 플러그인부터 PR을 혼자 열어버리는 자율 에이전트까지, 스펙트럼이 너무 넓다.
이 상황에서 테크 리드가 빠지기 쉬운 함정은 "어떤 도구가 제일 좋냐"를 계속 묻는 것이다. 도구 비교는 필요하지만, 그걸 팀 워크플로우의 어떤 단계에 배치하느냐가 훨씬 더 중요한 질문이다. 도구를 잘못된 단계에 투입하면, 좋은 도구도 팀을 느리게 만든다.
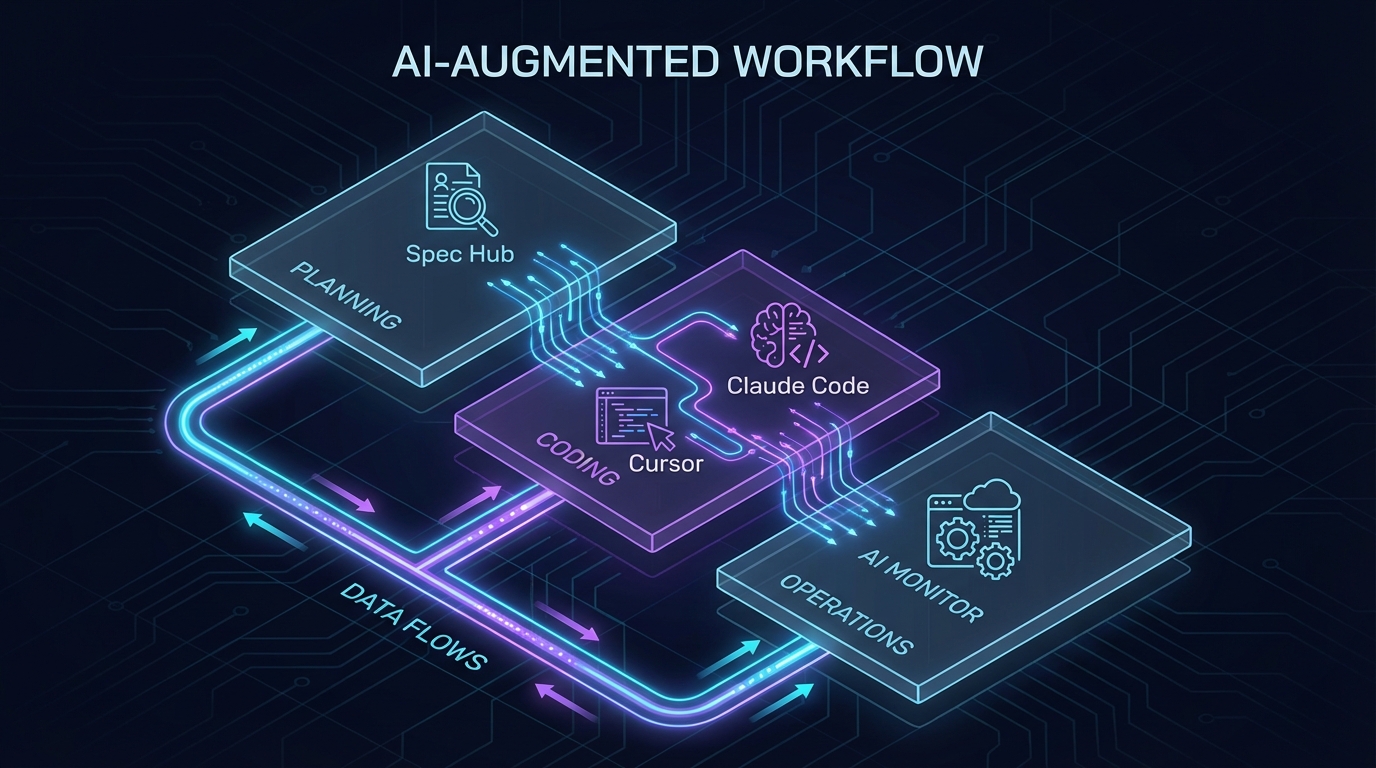
개발 단계별 도구 지형: 세 개의 레이어로 쪼개라
워크플로우를 기획·설계 → 코딩 → 검증·운영 세 레이어로 나누면, 각 단계에서 요구하는 AI의 역할이 완전히 다르다.
레이어 1: 기획·설계 — 사양(Spec)의 혼돈을 정리하는 단계
엔지니어링 팀의 실제 고통 중 하나는 스펙이 Google Docs, Confluence, Slack 스레드에 분산되어 있고, 변경 이력과 결정 근거가 추적되지 않는다는 것이다. Notion MCP 챌린지에서 공개된 Spec Hub(dev.to)는 이 문제를 정면으로 공략한다. Claude나 Cursor 같은 AI 어시스턴트가 MCP 프로토콜을 통해 Notion 워크스페이스를 직접 조작하도록 20개의 도구를 노출한다. 스펙 생성·버전 관리·변경 요청·의사결정 로그·버그 연결까지, 자연어 한 줄로 처리된다.
실용적으로 보면, "Alice 소유의 KPI 스펙을 만들어줘"라고 하면 스펙 항목이 생성되고 v1이 자동으로 붙는다. 버그를 등록하면 담당자에게 Notion 네이티브 @멘션이 날아간다. 외부 통합 없이, Notion 자체가 협업 인터페이스이자 AI의 실행 표면이 된다. 기획 단계에서 AI를 '검색·요약 도구'로만 쓰고 있다면, 이 레이어의 자동화 여지가 얼마나 큰지 다시 봐야 한다.
레이어 2: 코딩 — 도구 선택이 ROI를 결정한다
dev.to의 21개 도구 실측 테스트는 도구 간 품질 격차가 생각보다 크다는 걸 숫자로 보여준다. 알고리즘 구현, 버그 수정, 리팩토링, 테스트 작성, 코드 리뷰 다섯 가지 범주를 TypeScript·Python·Go에서 동일 조건으로 테스트한 결과, 최상위와 최하위 도구 사이 생산성 격차는 단순히 '빠르고 느리고'의 문제가 아니었다. 잘못 구성된 AI 어시스턴트는 직접 짜는 것보다 느리게 만든다. 리뷰·수정에 쓰는 시간이 작성 시간을 초과하기 때문이다.
종합 점수 기준으로 보면 Cursor(9.2)가 전체 1위, Claude Code(9.0)가 멀티파일 리팩토링·터미널 워크플로우에서 강점을 보였고, GitHub Copilot(8.8)은 IDE 지원 폭과 모델 선택 유연성에서 안정적이었다. 주목할 점은 '어떤 모델을 쓰느냐'보다 '코드베이스 컨텍스트를 얼마나 이해하느냐'가 실제 점수 차이를 만들었다는 것이다. Cody(Sourcegraph, 8.1)가 대형 코드베이스 컨텍스트에서 두드러진 이유도 같다.
팀 도입 판단 기준을 단순화하면 이렇다. IDE를 바꿀 수 있는 팀이라면 Cursor, 기존 IDE를 유지해야 한다면 GitHub Copilot, 터미널·멀티파일 에이전트 작업이 많다면 Claude Code를 주력으로 가져가는 조합이 현재로선 가장 검증된 배치다.
레이어 3: 검증·운영 — 자동화의 범위를 어디까지 열 것인가
Claude Code의 클라우드 예약 실행 기능(code.claude.com)은 이 레이어에서 의미 있는 변화를 가져온다. 매일 아침 PR 리뷰, 야간 CI 실패 분석, 주간 의존성 감사 같은 반복 작업을 컴퓨터가 꺼진 상태에서도 Anthropic 인프라 위에서 자동으로 돌릴 수 있다. MCP 커넥터로 Slack·Linear·Google Drive까지 연결되니, 결과물이 바로 팀 채널에 떨어진다.
실제 사용자들의 운용 사례를 보면 pnpm audit 보안 리포트, Sentry 로그 분석, 전날 커밋 품질 점검 등 3~5개 작업을 매일·매주 단위로 돌리는 패턴이 나온다. 다만 냉정하게 짚을 것이 있다. 클라우드 예약은 현재 Max 플랜에서도 3개로 제한되고, 네트워크 환경에 따라 디버깅이 까다로울 수 있다. "cron 한 줄이면 끝난다"는 반응도 Hacker News에서 나왔는데, 완전히 틀린 말은 아니다. 단순 반복 작업이라면 기존 자동화로 충분하다. AI 예약 실행이 진가를 발휘하는 건, 실행 결과를 '판단'해서 다음 액션으로 이어야 하는 작업, 즉 분석→요약→Slack 게시→이슈 생성까지 연쇄가 필요한 경우다.
팀 배치 설계의 실제 비용: 학습 곡선과 품질 리스크
세 레이어를 모두 AI로 채우는 그림은 그럴싸하지만, 팀에 실제로 투입할 때 두 가지 비용을 과소평가하기 쉽다.
첫째, 학습 곡선이다. Cursor나 Claude Code는 설치하는 것과 제대로 쓰는 것 사이의 거리가 멀다. 코드베이스 컨텍스트를 올바르게 먹이는 법, 프롬프트를 명확하게 쓰는 법, 에이전트의 출력을 검증하는 습관을 팀 전체가 내재화하기까지 보통 2~4주는 잡아야 한다. 도구를 도입하고 생산성이 잠시 떨어지는 시기를 팀이 버텨야 한다.
둘째, 품질 검증 체계다. AI가 생성한 코드는 그럴듯하게 보이지만 테스트가 의미 없는 보일러플레이트이거나, 리뷰가 스타일 지적에 집중되고 실제 논리 오류를 놓치는 경우가 있다. 실측 테스트에서도 이 점이 반복적으로 지적됐다. Spec Hub의 트레이서빌리티 그래프가 의미 있는 이유가 여기 있다. AI가 스펙을 읽고 코드를 짜고 테스트를 생성하는 흐름에서, '이 코드가 어떤 스펙 결정에서 나왔는지' 추적 가능한 구조가 없으면 품질 사고가 터졌을 때 원인을 찾기가 극도로 어렵다.
전망: '도구 스택'이 아니라 '워크플로우 아키텍처'를 설계하라
AI 코딩 어시스턴트 시장이 성숙해지면서, 앞으로 차별화 포인트는 개별 도구의 성능이 아니라 팀이 도구들을 어떻게 연결하느냐로 이동할 것이다. Spec Hub처럼 기획 단계의 사양 관리를 AI로 구조화하고, 코딩 단계에서 코드베이스 컨텍스트를 AI에 제대로 공급하고, 운영 단계에서 반복 검증을 자동화하는 흐름이 하나로 이어지면, 개별 도구의 성능 차이를 훨씬 상회하는 시너지가 나온다.
테크 리드에게 지금 당장 필요한 것은 도구 비교표를 한 번 더 읽는 것이 아니다. 내 팀의 어떤 단계에서 가장 큰 병목이 있는지 진단하고, 그 병목에 맞는 도구를 먼저 배치하는 것이다. 기획 단계에서 스펙이 흩어져 있다면 Spec Hub 류의 구조화 도구부터, 코딩 단계에서 컨텍스트 이해가 약하다면 Cursor 또는 Claude Code 도입을, 운영 단계에서 반복 작업이 수작업으로 남아 있다면 예약 자동화를 순서대로 공략하는 것이 현실적인 경로다. 전 단계를 한 번에 바꾸려다 팀이 도구에 잡아먹히는 것보다, 한 레이어씩 검증하며 확장하는 쪽이 훨씬 안전하다.