Claude Code를 처음 열면 낯선 개념들의 홍수에 압도된다. CLAUDE.md, rules, skills, hooks, subagents, MCP 서버… 도대체 이걸 다 알아야 제대로 쓸 수 있는 걸까? 비개발자 변호사가 법무 자동화 툴을 만들기 위해 Claude Code를 설치하고 '까만 터미널' 앞에서 막막함을 느꼈다는 경험담(브런치 08화)은 많은 이들의 첫인상을 압축한다. 그런데 이 파편처럼 흩어진 개념들, 알고 보면 꽤 일관된 레이어 구조로 설명된다.
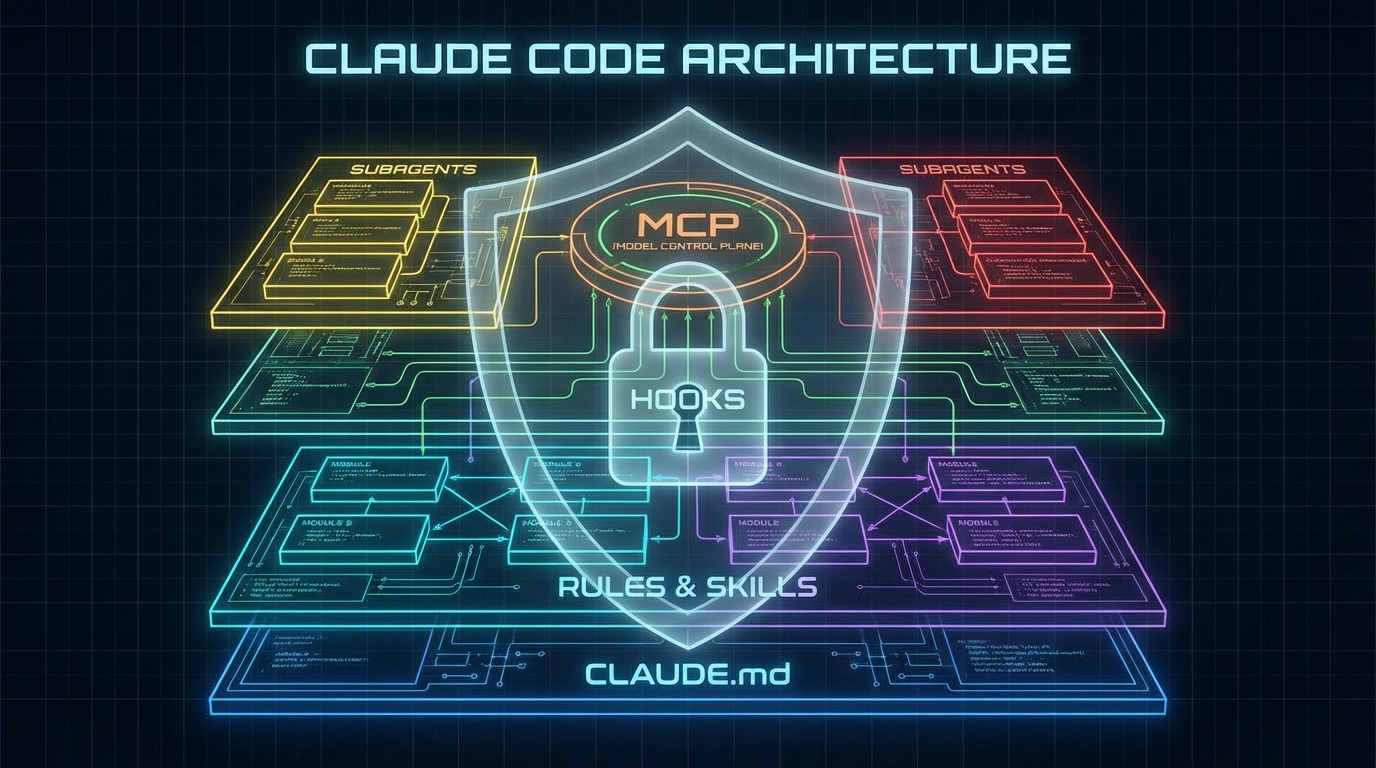
Claude Code는 하나의 기능이 아니라 작은 운영체제다
dev.to의 'Claude Code Crash Course'는 이 복잡함을 꿰뚫는 한 문장으로 시작한다. "Claude Code는 AI 보조 개발을 위한 소형 운영 체제다." 각 구성 요소는 제각각 존재하는 게 아니라 역할이 분리된 레이어다. CLAUDE.md와 rules는 행동 양식을 정의하고, skills는 재사용 가능한 플레이북을 패키징하며, hooks는 결정론적 자동화를 담당하고, subagents는 컨텍스트를 격리한다. MCP 서버는 외부 세계와의 연결 브릿지다. 이 구조가 눈에 들어오는 순간 복잡함이 아니라 설계의 일관성이 보이기 시작한다.
레이어 1 & 2: 지시는 가볍게, 범위는 정밀하게
CLAUDE.md는 모든 세션에 걸쳐 Claude가 읽는 영구 지침이다. 하지만 Anthropic이 강조하는 핵심은 단순하다—200줄 이하로 유지하라. 지침 파일을 온갖 컨벤션과 메모로 채워넣으면 에이전트가 일관성 없이 동작하는 원인이 된다. 모델이 나쁜 게 아니라 지침 레이어가 과부하 상태인 것이다. 프로젝트 규모가 커지면 .claude/rules/ 디렉토리로 분리하고, 경로별로 규칙을 스코핑해 필요한 곳에만 로드하게 설계하는 게 맞다. CLAUDE.md는 프로젝트의 넓은 원칙을, rules는 그것의 세밀한 모듈화를 담당한다는 역할 분리를 놓치면 안 된다.
레이어 3 & 4: Skills는 재사용, Hooks는 보장
Skills는 단순한 '추가 지시'가 아니다. 플레이키 테스트 디버깅, 릴리즈 노트 작성, API 설계 리뷰처럼 반복되는 워크플로우를 슬래시 커맨드(/my_skill)로 호출 가능한 독립 패키지로 만드는 것이다. 핵심은 항상 컨텍스트에 올라와 있지 않아도 된다는 점—필요할 때만 로드되므로 토큰 낭비가 없다. 반면 Hooks는 성격이 다르다. 파일 저장 후 포맷팅 실행, 보호 파일 쓰기 차단, 컨텍스트 압축 후 재주입처럼 "항상 Y가 발생하면 X를 실행해야 한다"는 조건이라면 프롬프트로 기대하는 게 아니라 Hooks로 보장해야 한다. AI 워크플로우가 조용히 신뢰 가능해지는 순간은 모델이 더 똑똑해질 때가 아니라, 워크플로우의 일부가 모델에 의존하지 않아도 될 때다.
레이어 5: 컨텍스트 오염을 막는 Subagents 전략
긴 코딩 세션에서 컨텍스트는 빠르게 오염된다. 탐색적 디버깅, 파일 읽기, 잘못된 시도들이 같은 대화창에 쌓이면 성능이 떨어진다. Subagents는 이 문제의 구조적 해법이다—보안 검토, 서브시스템 리서치, 집중 조사 같은 작업을 별도 컨텍스트 창에서 독립적으로 처리하게 위임한다. 질문이 달라진다. "모델에게 뭘 시킬까?"가 아니라 "어떤 컨텍스트가 이 작업을 처리해야 하는가?" 이것이 에이전틱 워크플로우 설계의 다른 레벨이다.
그런데, 이 편리함의 이면도 봐야 한다
여기서 잠깐 속도를 늦출 필요가 있다. 조지아텍 SSLab이 발표한 'Vibe Security Radar' 프로젝트에 따르면 AI 코딩 도구가 생성한 코드에서 발견된 CVE(보안 취약점)가 1월 6건 → 2월 15건 → 3월 35건으로 폭발적으로 증가했다. Claude Code, GitHub Copilot, Devin을 포함한 50여 개 도구를 모니터링한 결과 총 74개의 CVE가 확인됐다. 연구를 이끈 한칭 자오는 핵심을 찌른다—"많은 팀이 AI가 생성한 코드를 곧바로 프로덕션 환경에 배포하고 있고, 코드 리뷰만으로는 모든 취약점을 잡을 수 없다."
AI 생성 코드를 신뢰하되 검증하라
Claude Code를 레이어별로 정밀하게 설계하는 것과, 그 결과물에 대한 보안 검증은 별개의 문제다. Hooks로 보호 파일 쓰기를 차단하고 Subagents로 보안 리뷰 패스를 돌리는 것은 좋은 시작이지만, AI가 잘못된 응답을 생성하는 비율이 보안 사고의 54.4%를 차지한다는 통계 앞에서 워크플로우 설계만으로는 충분하지 않다. 전문가들이 권고하는 원칙은 명확하다—AI 입력 데이터를 신뢰할 수 없는 것으로 전제하고, 최소 권한 원칙을 적용하라. AI가 생성한 코드도 수작업 코드와 동일한 기준의 보안 검증 프로세스를 거쳐야 한다.
설계 관점에서 바라본 실전 체크리스트
정리하면, Claude Code를 제대로 쓴다는 건 기능을 배우는 것이 아니라 레이어 책임을 올바르게 배분하는 것이다. CLAUDE.md는 200줄 이하로 원칙만 담고, 세부 컨벤션은 rules로 분리한다. 반복 워크플로우는 skills로 패키징해 온디맨드로 호출하고, 결정론적으로 보장해야 할 동작은 hooks에 위임한다. 컨텍스트 오염이 우려되는 무거운 서브태스크는 subagents로 격리한다. 그리고 이 모든 설계 위에, AI가 생성한 코드는 무조건 검증 레이어를 통과시킨다는 원칙을 운영 문화로 내재화해야 한다.
전망: 워크플로우 설계자가 되는 것
비개발자 변호사가 Claude Code로 법무 자동화 툴을 만들고 법제처 API로 Skill을 구성하는 시대다. 접근 장벽은 낮아졌지만, 그렇다고 설계 판단의 필요성이 줄어든 건 아니다—오히려 늘었다. 누가 더 빠르게 코드를 생성하느냐의 경쟁은 이미 AI에게 넘어갔다. 지금 남은 역할은 어떤 레이어에 무엇을 맡길지, 어디에 가드레일을 칠지를 결정하는 워크플로우 아키텍트다. Claude Code의 복잡한 구성 요소들이 결국 이 한 가지 질문을 위한 도구라는 걸 이해하는 순간, 이 '작은 운영체제'가 제대로 작동하기 시작한다.