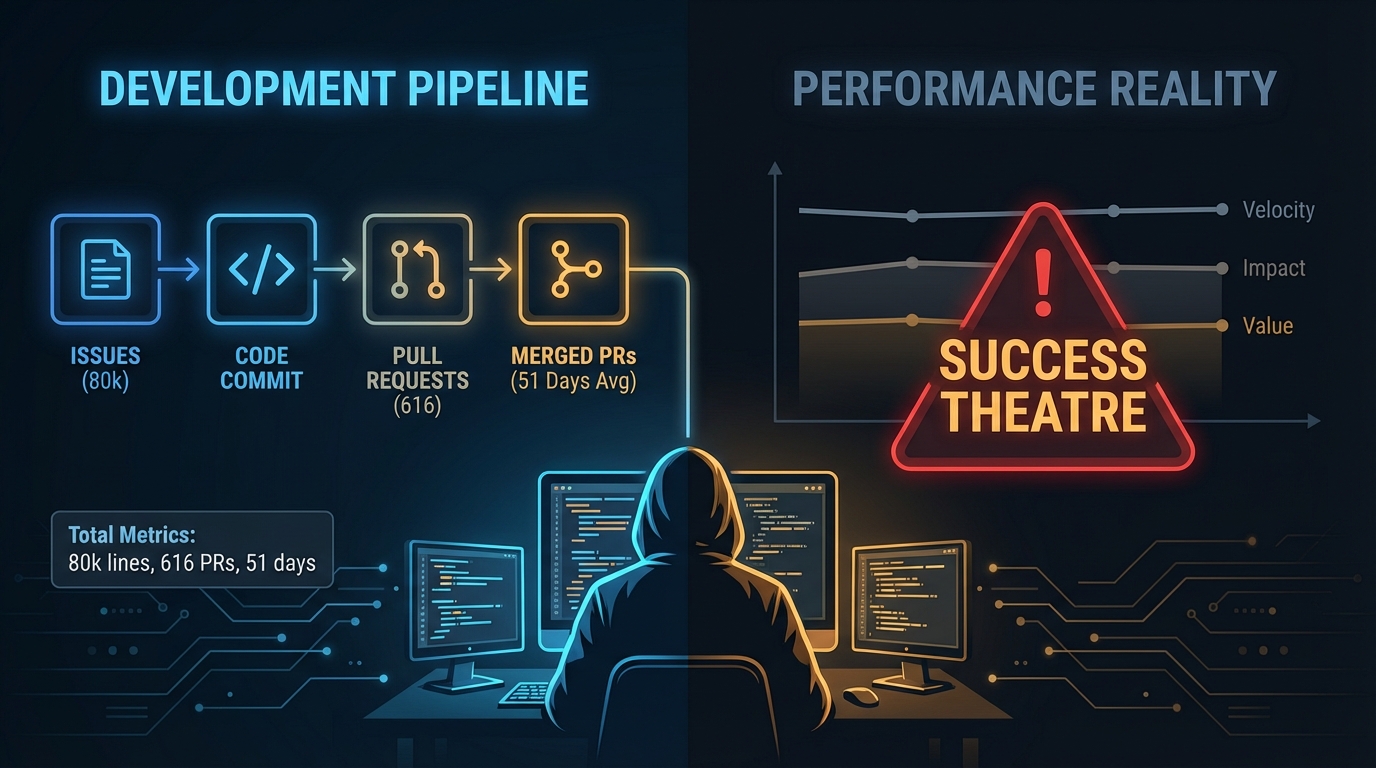
'51일 만에 8만 줄의 코드.' 숫자만 보면 클릭베이트처럼 들린다. 하지만 이 수치는 MTG Arena 데스크톱 컴패니언 Manasight를 혼자 개발한 Tim의 실제 기록이다. 33,000줄의 프로덕션 코드, 47,000줄의 테스트, 616개의 머지된 PR, 6,590개의 테스트 케이스. Claude Code를 활용한 AI-First 워크플로우의 결과물이다. 이 사례가 흥미로운 건 숫자 자체가 아니라, 그 숫자를 만들어낸 방법론과 그 방법론이 맞닥뜨린 반직관적 교훈이다.
병렬은 틀렸다, 순차가 맞다
Tim이 처음 시도한 방식은 우리 모두가 직관적으로 떠올릴 법한 것이었다. 여러 Claude 에이전트를 병렬로 돌려 각자 다른 이슈를 구현하게 하는 것. AI가 코드를 빠르게 쓴다면, 에이전트를 늘릴수록 처리량이 늘어야 한다. 단순한 산수다. 결과는 반대였다. 에이전트들은 서로 다른 스냅샷에서 작업했고, 컨텍스트가 오래될수록 수정이 복잡하게 얽혔다. 머지는 악몽이었다.
그가 내린 결론은 한 줄로 요약된다. "AI의 코딩 속도가 아니라, 인간의 사고 용량에 최적화하라." 병목은 AI의 구현 속도가 아니었다. 인간의 리뷰와 QA였다. 순차 처리는 숫자로는 느리지만 실제로는 빠르다. 인간이 제대로 생각할 수 있기 때문이다.
워크플로우의 해부: 4개의 명령어
Tim이 오픈소스로 공개한 워크플로우 시스템은 4개의 Claude Code 명령어로 구성된다. /issue-to-pr는 GitHub 이슈 하나를 리뷰 완료된 PR 하나로 변환하는 원자 단위다. 내부적으로 5단계를 거친다: 코드베이스 리서치 → 구현 및 테스트 → PR 생성 → 신선한 컨텍스트의 에이전트가 수행하는 자기 리뷰 → 피드백 기반 반복 수정(최대 10라운드).
핵심은 Implementer/Reviewer 패턴이다. 구현한 에이전트와 리뷰하는 에이전트를 분리한다. 리뷰 에이전트는 구현 과정의 기억이 없다. 실제 팀원이 PR을 처음 보듯 diff를 읽는다. /sequential-issues는 이 흐름을 여러 이슈에 걸쳐 체이닝하고, /self-review는 5개의 병렬 에이전트가 신뢰도 점수를 매겨 노이즈를 걸러낸다. /merge-stack은 스택 PR을 main에 병합하는 반복 작업을 자동화한다.
한 가지 전제조건이 있다. 코드를 작성하기 전에 이슈가 완전히 명세되어 있어야 한다. Tim은 구현 전에 Claude에게 이슈가 구현 준비가 됐는지 먼저 검토하게 한다. 모호한 요구사항은 버려야 할 코드를 만들 뿐이다. PR 크기는 중앙값 기준 243줄. 이 범위를 넘어서면 품질이 눈에 띄게 떨어진다고 보고한다.
통계가 말하는 것: 생산성 향상은 보편적이지 않다
한 사례의 성공을 일반화하기 전에, 냉정한 통계 연구를 들여다볼 필요가 있다. Rutherfoord 외 2인의 연구는 CLAUDE.md 또는 AGENTS.md 파일을 포함한 412개의 오픈소스 GitHub 리포지토리를 분석했다. AI 도구 도입 전후를 비교한 대규모 실증 연구다.
결론은 생각보다 조용하다. 대부분의 리포지토리는 AI 도입 후 통계적으로 유의미한 변화를 보이지 않았다. 즉각적인 효과가 나타난 경우는 대부분의 지표에서 10% 미만이었다. Python 리포지토리가 상대적으로 높은 변화율(총 커밋 20%, 순 추가 라인 17%)을 보였지만, 흥미롭게도 커밋 수는 감소하고 커밋당 변경 규모는 증가하는 패턴이 관찰됐다. AI 도입 이후 '더 적은, 하지만 더 큰 커밋'으로 개발 리듬이 바뀐다는 신호다.
장기 추세 변화는 즉각 효과보다 유의미했다. 이는 AI 도구의 생산성 효과가 단기 스파이크가 아닌 워크플로우 재설계를 통해 서서히 나타난다는 해석을 지지한다. 하지만 연구진은 명시적으로 경고한다. 도입 이후 데이터의 평균 기간은 150일(5개월)에 불과하다. 장기 효과를 판단하기엔 이르다.
성공 극장을 고백한 팀
세 번째 시각이 이 그림을 완성한다. 한 AI 관리 개발 프로젝트 팀이 시니어 임베디드 엔지니어 Nick Pelling에게 정면 비판을 받았다. 9번의 스프린트 회고 블로그를 공개했는데, 그의 평가는 날카로웠다. "CIA 정보 보고서처럼 읽힌다. 유능하고 없어선 안 되는 것처럼 보이도록 설계됐다."
팀이 솔직하게 고백한 실패들은 AI-First 워크플로우를 도입하는 모든 팀에게 참고서가 된다. 118개의 백엔드 서비스를 단일 파일에 쑤셔넣은 아키텍처 부채, 소스코드에 라우트 등록이 존재하는지만 확인하고 실제로 동작하는지는 테스트하지 않은 검증 공백, 그리고 3번의 스프린트 동안 반복 무시된 어드바이저리 경고. 마지막 항목이 특히 중요하다. "AI 에이전트에게 어드바이저리 방식의 거버넌스는 작동하지 않는다. 경고는 제안이고, 게이트는 요구사항이다."
스프린트 포인트 추정도 현실을 직격했다. 58포인트를 계획하고 38포인트를 달성했다. 34%의 미달. 팀은 솔직하게 인정한다. AI와 함께 일하면 추정이 더 쉬워지는 게 아니라 더 어려워진다. TDD 사이클, 문서화, 메모리 저장, 출처 추적 등 에이전트 운용의 의식 비용이 생각보다 크기 때문이다.
세 데이터가 함께 가리키는 것
세 소스를 교차하면 패턴이 보인다. Tim의 사례는 AI 에이전트가 높은 생산성을 낼 수 있는 조건을 보여준다. 잘 명세된 이슈, 작은 단위의 순차 처리, 인간 리뷰가 병목이라는 인식, 자동화된 품질 게이트. 통계 연구는 이 조건이 충족되지 않으면 효과가 보편적이지 않다는 사실을 숫자로 확인한다. 성공 극장 사례는 조건을 갖췄다고 착각하는 것이 얼마나 쉬운지를, 그리고 그 착각이 어떤 방식으로 드러나는지를 실시간으로 보여준다.
AI 코딩 에이전트의 ROI는 도구의 성능이 아니라 워크플로우 설계의 품질에 달려 있다. Tim의 '51일 8만 줄'은 Claude Code의 능력이 아니라 명세-순차-리뷰-게이트로 구성된 시스템의 결과물이다. 반대로 그 시스템 없이 에이전트를 투입하면, 통계는 아무것도 달라지지 않는다고 말하고, 팀은 자신도 모르게 성공 극장을 공연하게 된다.
팀 리드에게 주는 실전 체크리스트
이 세 데이터를 바탕으로 팀에 당장 적용할 수 있는 판단 기준을 정리하면 이렇다.
에이전트 투입 전에 확인할 것: - 이슈가 구현 가능한 수준으로 명세되어 있는가? (모호한 이슈 = 버려야 할 코드) - PR 단위가 200~300줄 이내로 제어되는가? (범위를 벗어나면 품질이 급락한다) - 인간 리뷰가 워크플로우의 어디에 위치하는가? (병목을 직시해야 설계가 된다)
에이전트 운용 중에 확인할 것: - 테스트가 '존재 여부'가 아니라 '동작 여부'를 검증하는가? - 거버넌스 규칙이 어드바이저리인가, 게이팅인가? (어드바이저리는 무시된다) - 스프린트 추정에 에이전트 운용 의식 비용이 포함되어 있는가?
성과 측정 시 확인할 것: - 코드 추가량뿐 아니라 코드 처 churn(수정 반복 빈도)도 보는가? - '성공 극장'을 공연하고 있지는 않은가? 실패를 중심에 두는 회고가 작동하는가?
AI 에이전트는 팀을 재설계하라는 신호다
통계 연구가 AI 도입 후 '더 적은, 더 큰 커밋' 패턴을 발견한 것은 상징적이다. AI 에이전트는 개발 속도를 높이는 동시에 개발 리듬 자체를 바꾼다. 빠른 구현이 가능해지면, 병목은 명세와 리뷰와 검증으로 이동한다. 그것은 기술적 문제가 아니라 팀 구조의 문제다.
Tim의 워크플로우가 오픈소스로 공개된 건 흥미로운 신호다. 이 패턴이 단일 프로젝트를 넘어 일반화될 수 있는지 아직 모른다고 그 자신도 인정한다. 하지만 '인간의 사고 용량에 최적화하라'는 원칙은 도구에 무관하게 유효하다. AI 에이전트를 팀에 투입하는 것은 코딩 속도 문제가 아니다. 팀이 어디서 생각하고, 어디서 판단하고, 어디서 책임지는지를 다시 설계하는 문제다.