문제는 모델이 아니라 워크플로우다
"AI가 나쁜 코드를 만든다"는 말을 들을 때마다 나는 한 가지를 먼저 확인한다. 에이전트에게 구조를 줬는가? 대부분의 경우, 답은 '아니오'다. 단일 에이전트 하나에게 큰 작업을 통째로 맡기면 30분 후에는 원래 계획을 잃고, 1시간 후에는 아무도 요청하지 않은 요구사항을 만들어낸다. 이건 모델의 문제가 아니다. 컨텍스트가 누적되면서 발생하는 구조적 드리프트다.
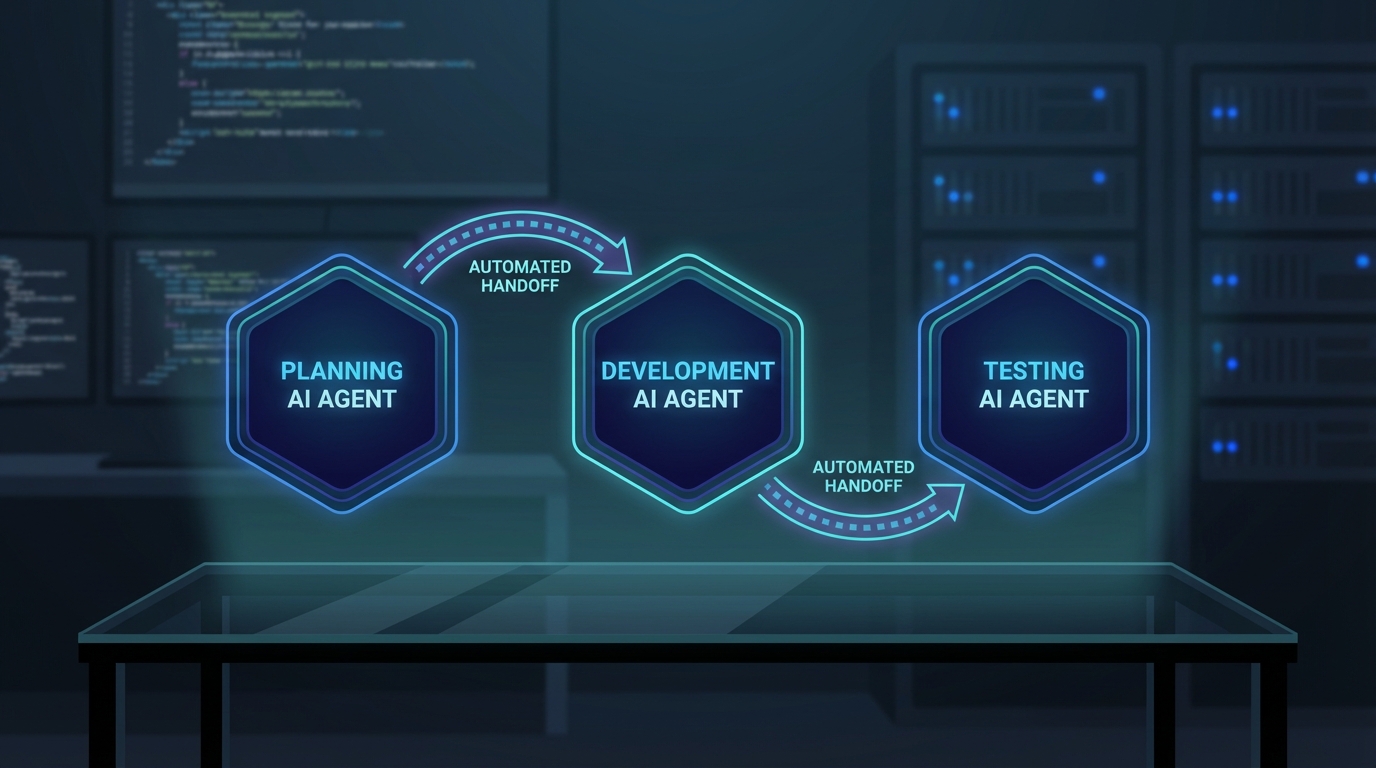
dev.to에 공개된 세 가지 실증 사례는 이 문제에 대한 같은 결론을 가리킨다. 기획 단계의 구조화, 개발 단계의 멀티 에이전트 오케스트레이션, 테스트 단계의 AI 리뷰 자동화—이 세 층위를 닫으면 AI-First 워크플로우는 실제로 작동한다.
1단계 기획: PM 운영 시스템으로 전제를 검증한다
EdgeCaser가 공개한 Shipwright는 'AI에게 PRD 써달라는 프롬프트'가 아니다. Claude Code 위에서 돌아가는 44개 원자 스킬, 7개 전문 에이전트, 16개 멀티스텝 워크플로우로 구성된 PM 운영 체계다. 핵심은 이진 패스/페일 게이트다. 산출물이 구조적·증거적 요건을 충족하지 못하면 다음 단계로 넘어가지 않는다.
실제 결과가 설득력 있다. LatAm 자격증 검증 프로젝트에서 Shipwright는 TAM/SAM/SOM 분석, 7개 자격증 레지스트리 API 실현 가능성 감사를 수행했다. 결론은 'FAIL'이었다—7개 중 0~1개만 쿼리당 2달러 이하로 상업적 접근이 가능했다. 핵심 전제가 코드 한 줄 짜기 전에 무너진 것이다. 이게 시스템이 제대로 작동한 증거다. 현실적으로 이 리서치 스택을 사람이 수행하면 4~8일이 걸린다.
테크 리드 관점에서 Shipwright가 흥미로운 이유는 산출물의 구조다. 모든 출력에는 의사결정 프레임(권고안, 지금 결정 vs 대기의 트레이드오프, 명시적 신뢰도, 담당자, 결정 날짜, 재검토 트리거)이 포함된다. 가정과 발견이 분리되고, 알 수 없는 것은 숨기지 않고 명시된다. 이는 AI가 만든 기획 문서가 팀의 판단 재료로 바로 쓰일 수 있는 조건이다.
2단계 개발: 멀티 에이전트가 드리프트를 차단한다
기획이 검증됐다면, 이제 구현이다. GitHub에서 11만 8천 개 이상의 스타를 받은 오픈소스 프레임워크들이 수렴한 답은 동일하다: plan → implement → review → fix 루프를 에이전트 간 분업으로 강제하라.
Superpowers(118,624 스타)는 규율 중심이다. 에이전트가 빌드 의도를 감지하면 코드 작성을 멈추고 스펙을 먼저 끌어낸다. 플랜의 각 태스크는 2~5분 단위로 쪼개지고, 정확한 파일 경로와 검증 단계가 명시된다. 서브 에이전트가 태스크를 마치면 두 단계 리뷰가 자동 실행된다: 스펙 일치 확인 → 코드 품질 확인. TDD는 선택이 아니라 강제다. 테스트 없이 작성된 코드는 삭제된다.
oh-my-claudecode(13,996 스타)는 멀티 프로바이더 유연성을 택했다. v4.4.0부터 tmux 워커를 통해 Claude, Codex, Gemini를 동시에 실행할 수 있다. 보안 리뷰는 Codex에, UI 작업은 Gemini에, 통합 작업은 Claude에 한 커맨드로 라우팅된다. 더 주목할 기능은 자동 스킬 학습이다. 디버깅 과정에서 수정 사항을 스킬 파일로 추출해 저장하고, 동일한 오류가 재발하면 해당 스킬을 자동 주입한다. 팀의 문제 해결 이력이 에이전트의 장기 기억이 된다.
두 프레임워크 모두 같은 구조에 수렴했다는 점이 신호다. 이건 CI/CD 파이프라인의 에이전트 버전이다. 각 스테이지를 인간이 아닌 에이전트가 채우고, 핸드오프는 자동화된다. 모델을 교체하기 전에 먼저 구조를 추가해야 한다.
3단계 테스트: AI 리뷰로 품질 게이트를 닫는다
개발이 끝났다고 워크플로우가 끝나는 게 아니다. 노코드 E2E 테스트 자동화 도구의 확산으로 테스트 케이스 생성의 허들은 낮아졌지만, 반대급부로 테스트 케이스 자체의 품질 관리가 공백이 됐다. dev.to의 AWS Builders 케이스는 이 공백을 MagicPod MCP 서버와 Claude 조합으로 메운다.
구조는 단순하다. MagicPod MCP 서버를 Claude Desktop에 연결하고, 리뷰 기준을 정의한 스킬 파일을 배치한다. "리뷰해줘" 한 마디면 AI가 테스트 케이스를 가져와 분석하고 리포트를 출력한다. 스킬 파일은 Agent Skills Open Standard 기반 마크다운으로, Claude Code·Cursor·Gemini CLI·Codex CLI에서 동일하게 쓸 수 있다.
이 구조가 팀에 의미 있는 이유는 개인 의존 리스크를 구조적으로 차단하기 때문이다. 소스 코드에는 PR 리뷰가 있고 GitHub가 있지만, 노코드 테스트 자동화 도구에는 그에 준하는 리뷰 환경이 없는 경우가 많다. 테스트 케이스를 만든 사람만 그 맥락을 아는 사일로 상태가 기본값이 된다. AI 리뷰는 이 구조적 공백에 게이트를 하나 추가하는 것이다.
세 층위를 하나의 루프로
세 사례가 그리는 구조는 명확하다.
- 기획: Shipwright가 전제를 검증하고 의사결정 프레임을 강제한다
- 개발: Superpowers/OMC가 멀티 에이전트 루프로 드리프트를 차단한다
- 테스트: MagicPod + Claude MCP가 품질 게이트를 자동화한다
세 단계 모두 공통된 설계 철학이 있다. AI는 자유롭게 두지 않는다. 플래닝 에이전트가 구현 에이전트를 체크하고, 패스/페일 게이트가 다음 단계로의 진입을 제어하며, 스킬 파일이 리뷰 기준을 명시화한다. 유연성은 구조 안에서만 허용된다.
팀에 AI-First 워크플로우를 도입할 때 가장 흔한 실수는 도구를 하나씩 추가하는 것이다. Copilot 쓰고, Claude Code 써보고, 테스트 자동화 도구 추가하고—그러나 각 도구가 독립적으로 작동하면 오히려 컨텍스트 단절이 생긴다. 세 사례가 공통으로 보여주는 것은 도구 선택보다 레이어 간 연결 설계가 먼저라는 점이다.
현실적인 진입 순서를 제안한다면: 테스트 리뷰 자동화부터 시작하라. 설치 5분, 즉각적인 피드백, 기존 워크플로우 변경 최소화. 팀이 AI 리뷰의 감각을 익히면, 개발 단계의 멀티 에이전트 구조를 실험할 준비가 된다. 기획 레이어의 PM 운영 시스템은 팀이 AI 생성물을 판단하는 능력이 쌓인 다음이 적기다. 한꺼번에 바꾸려 하면 학습 곡선이 팀을 삼킨다.