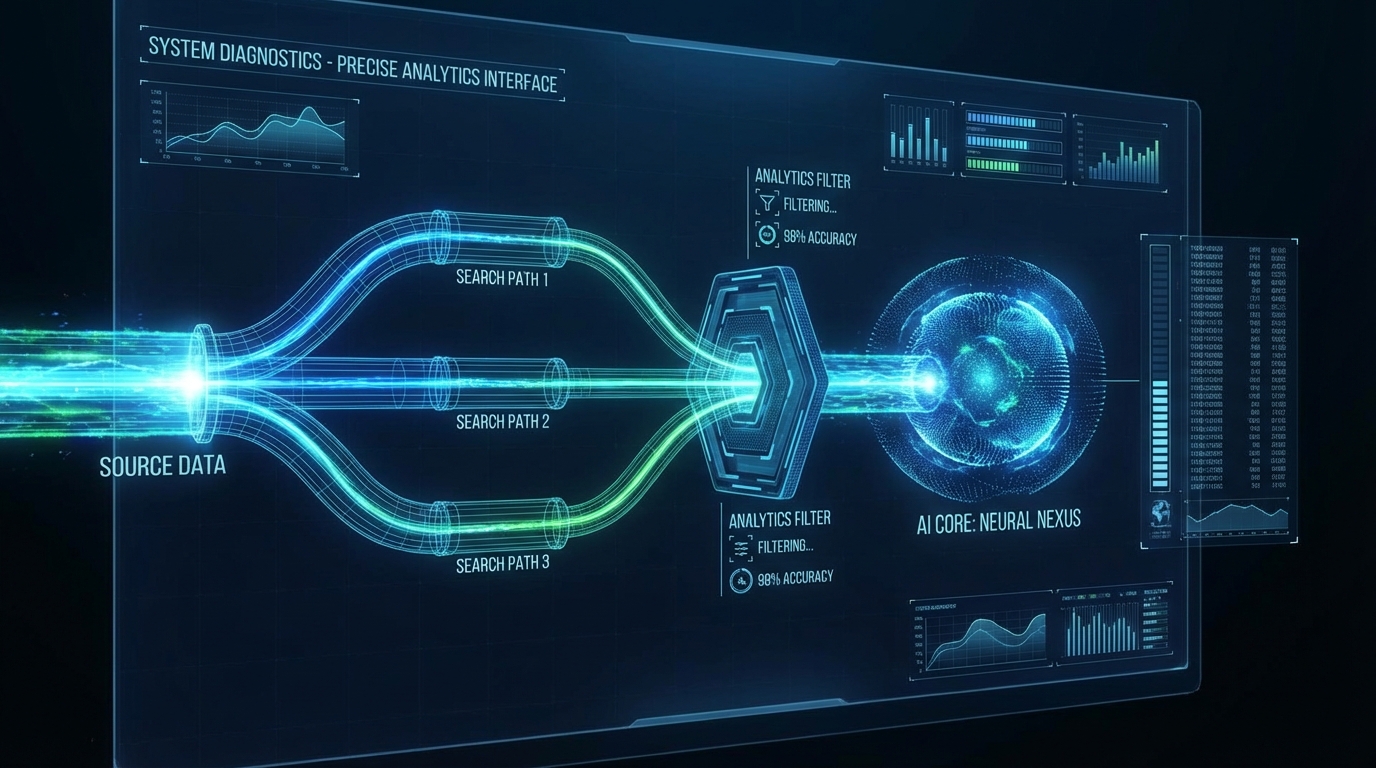
생성형 AI 프로덕션 환경에서 가장 빈번하게 관찰되는 안티패턴은 '단일 벡터 검색(Single-shot Retrieval)'과 '맹목적인 프롬프트 주입(Prompt Stuffing)'의 결합입니다. 이는 Retrieval 재현율(Recall) 저하와 LLM 추론 지연(Latency) 증가라는 이중고를 유발합니다. 최근 RAG 아키텍처의 성능 최적화를 다룬 두 건의 기술 분석 기사는, 검색 단계의 시맨틱 커버리지 확장과 생성 단계의 컨텍스트 통제라는 상충되는 목표를 어떻게 수학적, 구조적으로 타협할 것인가에 대한 명확한 해답을 제시합니다.
먼저 검색의 한계를 정량적으로 입증한 dev.to의 'One query is never enough' 기사를 살펴보면, 사용자의 복합 질의를 단일 임베딩으로 압축할 경우 벡터 공간에서 심각한 의미 누락이 발생함을 알 수 있습니다. 예컨대 "Flask 앱의 느린 DB 연결 해결법"이라는 질의는 [Flask 패턴, DB 풀링, 성능 진단]이라는 세 개의 독립된 클러스터를 내포하지만, 단일 벡터는 특정 교집합에만 안착하여 '성능 진단'과 같은 핵심 문서를 상위 K개(Top-K) 결과에서 누락시킵니다. 이를 해결하기 위해 LangChain의 MultiQueryRetriever나 LlamaIndex의 SubQuestionQueryEngine을 활용하여 질의를 3개 이상으로 분해하고 RRF(Reciprocal Rank Fusion)로 병합하는 다중 쿼리 전략이 필수적입니다. 이는 컴퓨팅 코스트의 증가를 수반하지만, 시맨틱 커버리지를 확보하기 위한 불가피한 트레이드오프입니다.
그러나 검색 재현율을 높이기 위해 확보한 다량의 청크(Chunk)를 그대로 프롬프트에 밀어 넣는 것은 시스템의 붕괴를 초래합니다. dev.to의 'Prompt Stuffing Is Killing Your Agent' 기사는 6,000토큰 이상의 컨텍스트 블롭(Blob)이 LLM의 다중 추론 능력을 어떻게 마비시키는지 지적합니다. 토큰 사용량이 증가함에 따라 문맥 내 정보 검색(Needle-in-a-haystack) 정확도는 비례해서 하락하며, 불필요한 노이즈는 환각(Hallucination) 비율을 높이고 프로덕션 환경의 P99 레이턴시를 치명적으로 악화시킵니다. 더 많은 비용을 지불하고 오히려 생성 품질(Answer Relevance)을 떨어뜨리는 역설이 발생하는 것입니다.
이 트레이드오프를 해결하는 실무적 시사점은 '조건부 검색(Conditional Retrieval)'과 '검증 루프(Validation Loop)'를 결합한 에이전틱 RAG(Agentic RAG) 설계에 있습니다. 검색된 융합 데이터 전체를 LLM에 일괄 주입하는 대신, 라우팅 알고리즘을 통해 현재 추론 단계에 필수적인 컨텍스트만을 선별하여 제한적으로 주입해야 합니다. 또한, 각 검색 단계마다 예산(Token Budget)과 실행 횟수를 상태(State) 값으로 추적하여 임계치 도달 시 탐색을 중단하는 오케스트레이션이 필요합니다. 이는 API 호출 비용(COGS)을 정량적으로 통제하는 동시에, 깨끗한 컨텍스트 유지를 통해 모델의 재시도(Retry) 비용을 방어하는 핵심 기제입니다.
결론적으로, 신뢰성 있는 AI 시스템을 구축하기 위해서는 RAG 파이프라인의 각 구성 요소를 독립적인 메트릭으로 통제해야 합니다. 검색 단계에서는 다중 쿼리 확장으로 재현율(Recall)의 상한선을 높이고, 생성 단계에서는 에이전트의 조건부 필터링을 통해 컨텍스트 정밀도(Context Precision)를 극대화하는 이원화 전략이 요구됩니다. 앞으로의 LLM 시스템 벤치마크는 단순한 데모 환경의 응답 품질이 아니라, 트래픽이 집중되는 프로덕션 환경에서 토큰당 성능비와 런타임 지연을 엄밀하게 제어하는 '아키텍처의 결정론적 통제 능력'에 의해 판가름 날 것입니다.