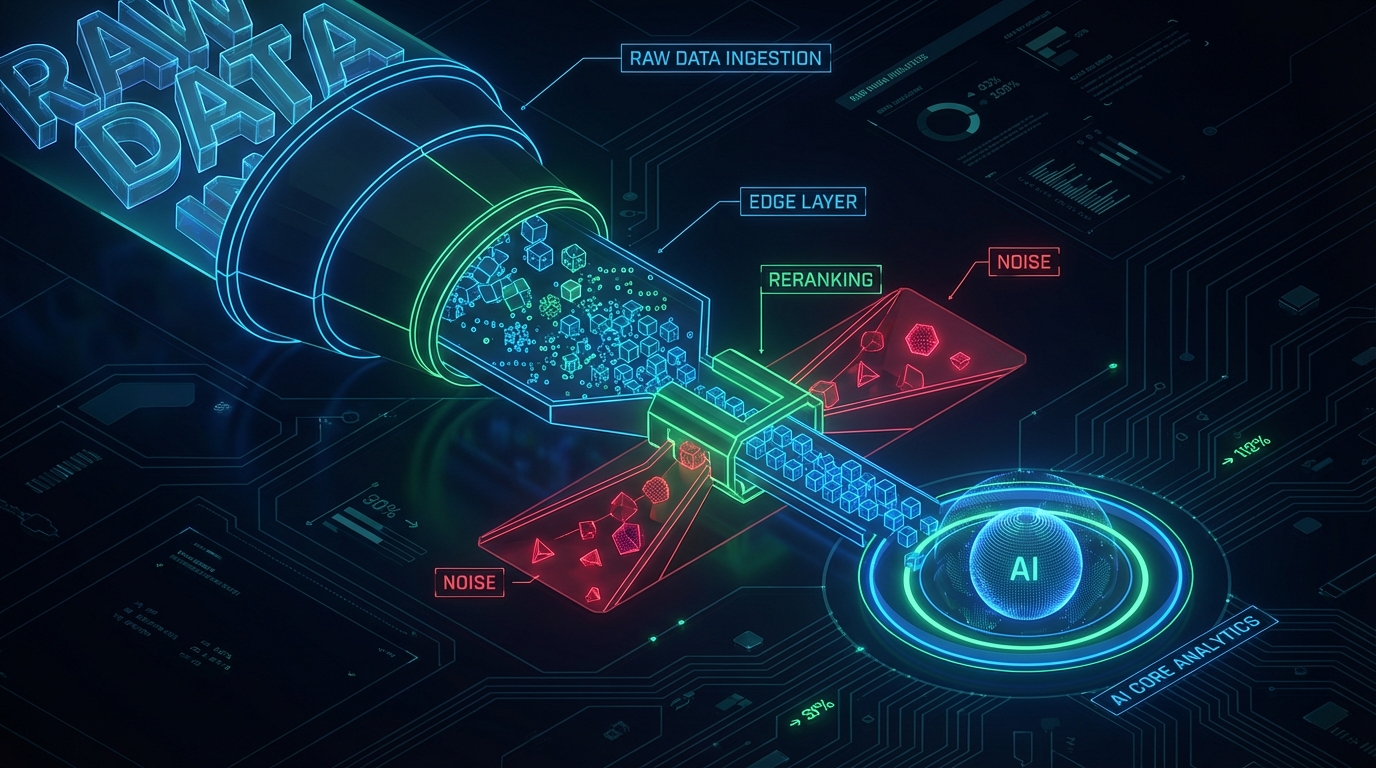
프로덕션 환경에서 RAG(Retrieval-Augmented Generation) 시스템을 운영해 본 엔지니어라면, 단순한 벡터 유사도(Vector Similarity) 기반의 검색이 얼마나 높은 환각(Hallucination) 비율과 직결되는지 뼈저리게 체감했을 것이다. 코사인 유사도가 0.85를 넘어가더라도, 해당 청크(Chunk)가 사용자의 질문에 대한 실질적인 해답(Answer Relevance)을 포함하고 있다는 통계적 보장은 없다. 생성형 AI 시스템의 신뢰성을 담보하기 위해서는 텍스트 전처리(Chunking)부터 검색(Retrieval), 그리고 재정렬(Reranking)에 이르는 파이프라인의 각 구성 요소를 독립적으로 측정하고 연산 비용과의 트레이드오프를 정량적으로 평가해야 한다.
고품질 RAG 파이프라인의 첫 번째 병목은 데이터 수집 및 청킹 단계에서 발생한다. 특히 한국어 텍스트의 경우, 단순한 글자 수 기반 분할이 아닌 의미론적 경계(Semantic boundary)를 보존하기 위해 형태소 분석이 필수적이다. 최근 Geeknews를 통해 공유된 'Garu' 프로젝트는 이 전처리 파이프라인의 아키텍처에 중대한 시사점을 던진다. 기존 형태소 분석기(Kiwi ~40MB, MeCab-ko ~50MB)가 무거운 서버 환경을 요구했던 것과 달리, Garu는 1.7MB(네트워크 전송 기준 약 1MB)의 초경량 모델과 WASM 엔진만으로 브라우저에서 직접 실행된다.
이 모델의 기술적 성취에서 주목해야 할 지점은 아키텍처의 전환을 통한 효율성 극대화다. 학습 파라미터가 0개인 순수 룩업(Lookup)과 Viterbi 디코딩 기반의 비신경망 아키텍처를 채택했음에도 불구하고, NIKL 모두의 말뭉치 기준 95.3%의 F1 점수를 달성했다(Kiwi 87.9%, MeCab-ko ~85%). 이를 MLOps 관점에서 해석하면, 클라이언트 사이드(Edge)로 형태소 분석 연산을 오프로딩(Offloading)함으로써 서버의 전처리 연산 비용(Compute Cost)을 제로에 가깝게 만들면서도 임베딩 품질의 기반이 되는 토큰화(Tokenization) 정확도를 SOTA 급으로 유지할 수 있다는 수학적 근거가 된다.
이렇게 최적화된 청크들이 벡터 DB에 색인된 후, 사용자의 쿼리가 들어오는 검색(Retrieval) 단계에서는 또 다른 품질 저하 요인이 발생한다. Dev.to에 게재된 Reranking 관련 아티클은 이를 '채용 프로세스'에 비유하여 정확히 짚어낸다. FAISS나 Pinecone을 활용한 임베딩 기반 검색은 이력서의 키워드를 스캔하여 후보군을 추려내는 '인사팀(HR)'의 역할에 불과하다. 빠르고 광범위하지만, '유사성(Similarity)'이 곧 '적합성(Suitability)'을 의미하지는 않는다. 바이 인코더(Bi-encoder) 구조의 한계로 인해, 의미적으로 겹치는 단어가 많을 뿐 실제 질문에 대한 답변이 누락된 노이즈 청크들이 Top-K에 포함되는 현상이 발생한다.
이러한 검색의 태생적 한계를 교정하는 실행 경계 방어 기제가 바로 크로스 인코더(Cross-Encoder) 기반의 재정렬(Reranking)이다. 아티클에서 소개된 Cohere Rerank 모델과 같은 시스템은 쿼리와 문서를 개별적으로 임베딩하여 비교하는 대신, 두 텍스트를 함께 읽고 맥락적 관계를 분석하여 정밀한 '관련성 점수(Relevance Score)'를 산출한다. 이는 서류를 통과한 후보자들을 심층 면접하여 실제 업무 적합성을 평가하는 '채용 매니저'의 역할과 동일하다. Reranking을 도입하면 Context Precision(검색된 컨텍스트 중 정답이 상위에 위치하는 비율)이 비약적으로 상승하며, LLM에 주입되는 노이즈를 차단할 수 있다.
물론 크로스 인코더를 파이프라인에 추가하면 쿼리당 추론 지연 시간(P99 Latency)과 연산 비용이 증가하는 명확한 트레이드오프가 존재한다. 그러나 전체 시스템 관점에서 보면 이는 압도적으로 남는 장사다. Garu와 같은 초경량 WASM 모델을 통해 전처리 단계의 서버 인프라 비용을 대폭 삭감하고, 여기서 확보된 리소스를 Reranking 계층에 재투자하는 아키텍처 설계가 가능하다. 재정렬을 통해 정제된 소수의 고품질 컨텍스트만 LLM의 프롬프트로 전달하면, 입력 토큰 낭비(Token Leakage)를 방지하여 LLM API 호출 비용을 절감하고 생성 결과의 사실성(Faithfulness)을 극대화할 수 있다.
결론적으로 프로덕션 레벨의 RAG 시스템은 더 이상 단일한 거대 모델의 마법에 의존해서는 안 된다. 엣지 환경에서의 결정론적이고 가벼운 텍스트 전처리(Garu), 효율적이고 넓은 1차 벡터 검색, 그리고 연산 집약적이지만 정밀한 2차 시맨틱 재정렬(Cohere Cross-Encoder)로 이어지는 다단 라우팅(Multi-stage Routing) 전략만이 성능과 비용이라는 두 마리 토끼를 잡을 수 있다. 시스템의 각 모듈을 독립적인 메트릭으로 평가하고 자원을 재분배하는 데이터 중심의 오케스트레이션이 생성형 AI 인프라 경쟁력의 핵심이 될 것이다.