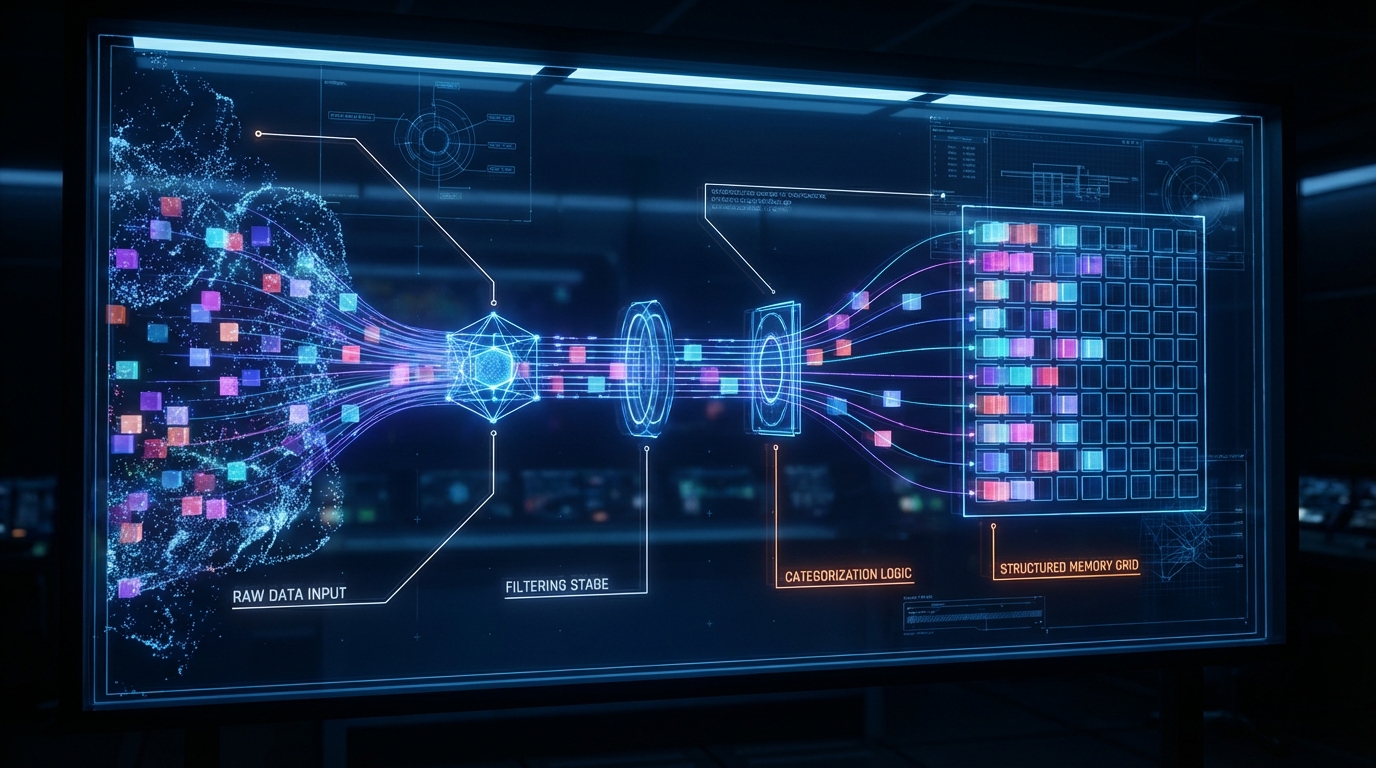
생성형 AI 시스템을 프로덕션에 배포하는 엔지니어들이 범하는 가장 치명적이고 보편적인 통계적 오류는 '벡터 데이터베이스(Vector DB)의 Top-K 검색(Retrieval)'을 '에이전트의 기억(Memory)'과 동일시하는 것이다. 최근 dev.to에 게재된 두 편의 아티클("A Vector Store Is Not an Agent Memory System", "My AI remembered the wrong thing...")은 이 아키텍처적 착각이 실제 운영 환경에서 어떻게 비용 폭점과 치명적인 환각(Hallucination)으로 이어지는지를 실측 데이터를 통해 가감 없이 폭로한다. 단순한 텍스트 청크(Chunk)를 코사인 유사도에 기반해 프롬프트에 주입하는(Stuffing) 방식은 초기 데모 환경에서는 그럴싸하게 작동하지만, 에이전트의 실행 주기(Horizon)가 길어질수록 컨텍스트 윈도우의 노이즈 비율을 기하급수적으로 끌어올리며 P99 레이턴시를 철저히 붕괴시킨다.
유튜브 숏츠 제작 자동화 파이프라인을 구축한 마이클 오니에크웨레(Michael Onyekwere)의 사례는 비구조화된 메모리가 어떻게 시스템의 신뢰성을 파괴하는지 보여주는 완벽한 대조군이다. 그의 에이전트 메모리에는 단 두 달 만에 330개의 결정(Decision) 및 버그 수정 내역이 적재되었다. 문제는 과거의 규칙("음성 오디오에 항상 loudnorm을 적용할 것")과 이를 뒤집은 최신 규칙("절대 loudnorm을 적용하지 말 것 - 노이즈 플로어가 상승함")이 동일한 가중치로 DB에 혼재되어 있었다는 점이다. 벡터 검색 관점에서 두 텍스트는 시맨틱 유사도가 매우 높게 산출된다. 에이전트가 이 모순된 두 청크를 동시에 검색해 프롬프트에 올리자, 모델은 폐기된 과거의 규칙을 채택했고 결과적으로 오디오 파이프라인 전체가 오염되었다. 이는 검색(Retrieval)이 독립적인 검증 기제 없이 인과관계(Causality)를 잃었을 때 발생하는 전형적인 프로덕션 장애다.
이러한 메모리 충돌을 수학적으로 통제하기 위해서는 데이터 파이프라인 단에서 '메모리 수명 주기 거버넌스(Memory Lifecycle Governance)'를 도입해야 한다. 첫 번째 방어선은 승인 제어(Admission Control)다. Workday AI의 A-MAC 프레임워크가 증명하듯, 모든 이벤트가 메모리에 저장되어서는 안 된다. 유입되는 텍스트 청크에 대해 중요도(Importance), 참신성(Novelty), 재사용성(Reusability) 등의 변수로 가중치 합산 점수(Weighted Score)를 계산하고, 통계적 유의성을 지닌 임계값(Admission Threshold)을 넘는 데이터만 장기 저장소에 적재해야 한다. 데이터의 무분별한 Upsert는 결국 컨텍스트 토큰의 낭비와 추론 비용 증가라는 선형적 경제 손실로 직결되기 때문이다.
두 번째 방어선은 망각(Forgetting)과 상태(State) 관리다. 지능적 에이전트는 망각을 버그가 아닌 피처(Feature)로 활용해야 한다. 최근 연구인 SleepGate나 A-MEM이 지적하듯, 시간 경과(Age)와 접근 빈도(Access Count)를 변수로 하는 감가상각 율(Decay Rate)을 적용해 임계치 이하의 메모리를 아카이빙(Archive)하거나 삭제해야 한다. 오니에크웨레가 구축한 오픈소스 도구 quilmem은 이를 실무적으로 훌륭히 구현해 냈다. 메모리 엔티티에 단순한 텍스트가 아니라 가설(hypothesis) → 활성(active) → 검증됨(validated) → 대체됨(superseded)이라는 상태(Status) 값을 부여한 것이다. 대체된 메모리는 벡터 검색 대상에서 하드-필터링(Hard-filtering) 됨으로써 에이전트는 오직 '현재 유효한 진실(Current Truth)'에만 접근하게 된다.
세 번째 방어선은 독립적인 충돌 탐지(Conflict Detection) 알고리즘이다. DB 내의 논리적 모순을 정량적으로 색인하는 것은 매우 까다로운 작업이다. quilmem의 초기 충돌 탐지 스크립트는 단순 키워드(예: "never")와 문서 스캔을 통해 무려 1,848개의 충돌(False Positives)을 뱉어냈다. 하지만 25% 이상의 토픽 오버랩(Topic Overlap)을 요구하고, 문서 전체가 아닌 문장 수준의 부정어(Negation) 매칭으로 알고리즘의 정밀도를 튜닝한 결과, 실제 프로덕션에 치명타를 입힐 수 있는 단 7개의 '진짜 모순'을 식별해 냈다. 이는 RAG 파이프라인 최적화에 있어 청크 단위의 미시적 튜닝이 에이전트의 논리적 오류율(Error Rate)을 얼마나 극적으로 낮출 수 있는지 증명하는 실측 데이터다.
최근 Long-Context LLM(예: 1M 토큰 윈도우)의 발전으로 인해 "모든 히스토리를 프롬프트에 때려 넣으면 메모리 시스템이 필요 없는 것 아닌가?"라는 반론이 제기되기도 한다. 하지만 최신 연구(Memory Systems or Long Contexts?)의 비용-성능 트레이드오프 분석에 따르면, 턴(Turn) 당 컨텍스트 비용은 프롬프트 길이에 비례해 기하급수적으로 증가한다. 대략 10턴, 약 100k 토큰 임계점을 넘어서는 순간, 정교한 메모리 거버넌스를 갖춘 RAG 시스템이 Long-Context 추론보다 훨씬 평탄한 비용 곡선(Cost Curve)을 그리며 압도적인 단위 경제성(Unit Economics)을 확보한다. 메모리 구조화는 단순한 아키텍처 선택이 아니라 MLOps 관점의 원가(COGS) 절감 전략인 셈이다.
결론적으로, 신뢰할 수 있는 에이전트 시스템(Agentic System)을 프로덕션에 안착시키기 위해서는 벡터 DB 구축을 넘어 '메모리 건강 지표(Memory Health Score)'를 상시 모니터링해야 한다. 원본 소스 파일의 해시(Hash)가 변경되었음에도 업데이트되지 않은 부패(Stale) 메모리, 대체(Supersede) 고리가 끊어진 고아 데이터, 명시적으로 검증(Validated)되지 않은 활성 데이터의 비율을 정량적으로 페널티화하여 점수를 산출하는 AgentOps 환경이 필수적이다. StructMemEval과 같은 벤치마크가 요구하듯, "데모에서 검색이 잘 되었다"는 감상적 평가를 버리고 "메모리 구조화가 실제 후행 의사결정의 정확도를 높이고 컨텍스트 I/O 병목을 줄였는가"를 P99 지표로 엄밀히 측정해야 할 때다.