2026년 3월, AI 코딩 도구 생태계에서 동시다발적으로 터진 세 가지 사건은 묘하게 같은 방향을 가리킨다. Claude Code의 51만 2000줄 소스코드가 단 하나의 .map 파일로 유출됐고, 같은 $200짜리 플랜에서 도구마다 가성비가 5배 이상 벌어진다는 실험 결과가 나왔으며, AI는 조용히 단순 코드 생성기를 넘어 작업 파이프라인 자체로 진화하고 있었다. 이 세 가지를 따로 읽으면 각각의 뉴스지만, 함께 읽으면 하나의 질문이 남는다. 지금 AI 코딩 도구를 어떻게 선택하고, 어디까지 신뢰해야 하는가.
유출 사건이 드러낸 것: 모르고 쓰던 것들
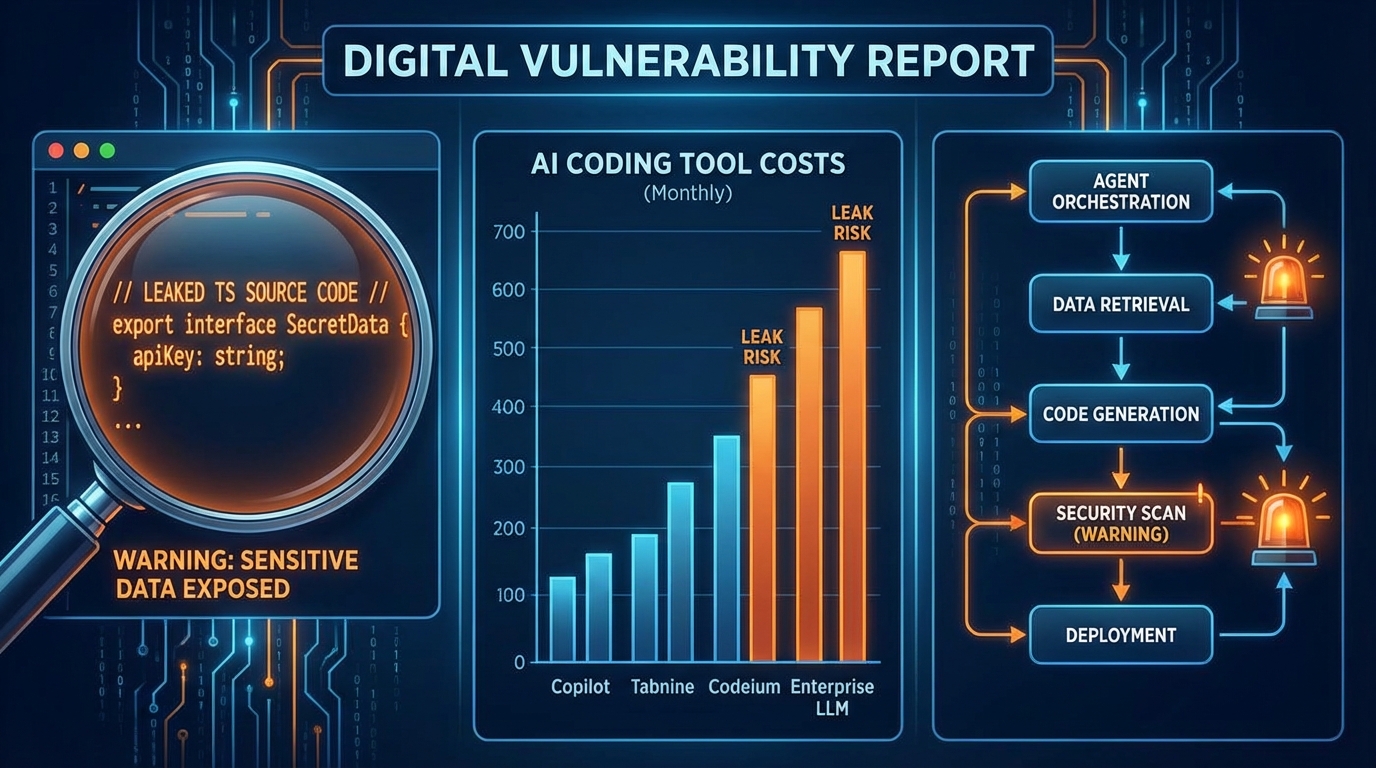
dev.to에 올라온 보고에 따르면, Anthropic은 프로덕션 npm 패키지에 소스맵 파일을 실수로 번들링했다. 소스맵은 빌드된 코드를 원본 TypeScript로 되돌리는 디버깅 도구다. 개발 환경에만 있어야 할 파일이 배포 패키지에 들어갔고, 그 안에 R2 스토리지 버킷 URL이 있었다. 클릭 한 번으로 1900개 파일, 51만 2000줄의 주석 달린 TypeScript 원본이 열렸다.
보안 관점에서는 명백한 공급망 보안 실패다. 하지만 흥미로운 반전이 있다. 개발자 Skanda의 지적처럼, Claude Code CLI는 원래 npm 패키지 내 minified JS로 로직을 읽을 수 있었다. 소스맵은 그것을 '읽기 좋게' 만들었을 뿐이다. Anthropic의 진짜 해자는 Claude 모델 자체이지 CLI 툴 구현이 아니다. 이 관점에서 유출의 '피해'는 생각보다 크지 않을 수 있다.
그럼에도 이 사건이 의미 있는 이유는 따로 있다. 유출된 코드에서 드러난 Claude Code의 내부 아키텍처—3단계 컨텍스트 압축 전략, 멀티 에이전트 권한 큐 시스템, 24시간 주기 메모리 통합 패턴—는 AI 코딩 도구가 얼마나 정교하게 설계된 시스템인지를 보여준다. 우리가 '도구'라고 부르는 것이 실은 수십 개의 에이전트 툴, 85개의 슬래시 커맨드, 복잡한 오케스트레이션 레이어를 갖춘 프로덕션 소프트웨어임을 확인한 것이다. 모르고 쓰던 것들이 수면 위로 올라온 셈이다.
같은 $200, 5배 차이: 가격 비교의 함정
dev.to에서 Andrew Shu가 진행한 12개의 실험은 더 실용적인 질문을 다룬다. 같은 $200/월 플랜에서 Claude Code Max 20x, Cursor Ultra, Codex Pro를 비교했을 때, 월간 에이전트 운용 시간은 각각 678시간, 138시간, 220시간으로 나왔다. 단순 용량 기준으로 Claude Code가 약 5배 더 많은 작업을 처리할 수 있다는 계산이다.
그런데 이 숫자를 그대로 받아들이면 함정에 빠진다. Cursor Ultra의 138시간은 두 개의 토큰 풀로 나뉜다. 프런티어 모델(Opus 등)용 API 크레딧은 약 18시간, Cursor가 자체 최적화한 Composer 모델용 크레딧은 약 120시간이다. 문제는 많은 개발자가 "Ultra를 샀으니 최고 모델을 써야지"라며 Opus만 쓰다가 예상보다 빠르게 크레딧을 소진한다는 것이다. Cursor는 사실상 Composer 모델 중심으로 사용하도록 설계된 플랜을 팔고 있는데, 마케팅은 SOTA 모델 접근을 앞세운다.
반면 속도 면에서는 반전이 있다. 실험에서 Composer 모델은 다른 모델 대비 2배 이상 빠른 작업 처리 속도를 보였다. 용량은 Claude Code가 우세하지만, 빠른 구현 속도가 필요한 작업에서는 Cursor Composer가 체감 생산성에서 앞설 수 있다. '에이전트 시간'이라는 새로운 단위로 도구를 평가하기 시작해야 한다는 것, 그리고 그 단위도 맥락에 따라 다르게 해석해야 한다는 것이 핵심 시사점이다.
파이프라인 통합: 도구 선택의 판이 바뀌고 있다
dev.to의 March 2026 AI Roundup은 더 긴 시야를 제시한다. 이번 달의 핵심은 "더 좋은 모델"이 아니라 "AI가 파이프라인 어디에 자리 잡느냐"의 문제였다. Andrej Karpathy의 AutoResearch는 에이전트가 실험 루프 자체를 돌리는 구조를 보여줬고, Cursor Automations는 Slack·GitHub·PagerDuty 이벤트에 반응하는 상시 실행 에이전트를 가능하게 했다. Cline Kanban은 병렬로 돌아가는 에이전트들을 관리하는 칸반 레이어를 제시했다.
이 흐름에서 가장 중요한 인식 전환은 이것이다. AI 코딩 도구의 가치는 더 이상 '코드 생성 품질' 하나로 평가할 수 없다. 오케스트레이션 능력, 트리거 설계, 병렬 작업 관리, 인간이 개입할 체크포인트 설계—이 모든 것이 도구의 실질적 가치를 구성한다. 어떤 에이전트를 얼마나 자율적으로 운용할 것인지, 그리고 어디서 인간이 다시 통제권을 가져와야 하는지를 설계하는 능력이 개발자의 핵심 역량이 되고 있다.
지금 AI 코딩 도구를 고를 때 봐야 할 것
세 사건을 종합하면 실용적인 선택 기준 세 가지가 나온다.
첫째, 투명성 검증. Claude Code 유출 사건은 역설적으로 내부 아키텍처를 오픈한 계기가 됐다. 하지만 내가 매일 쓰는 도구가 내 코드베이스에 어떻게 접근하고, 어떤 데이터를 외부로 보내는지는 여전히 불투명한 경우가 많다. npm 패키지를 직접 뜯어보거나, 네트워크 요청을 모니터링하거나, 오픈소스 여부를 확인하는 습관이 필요하다.
둘째, 비용 모델 해부. 월정액 숫자만 보지 말고, 토큰 풀 구조를 파악해야 한다. 내가 주로 사용하는 모델 티어가 어떤 풀에서 소진되는지, Composer 같은 자체 최적화 모델과 SOTA 프런티어 모델의 혼용 비율을 어떻게 설정할지가 실제 ROI를 결정한다.
셋째, 파이프라인 통합 가능성. 단순히 "코드를 잘 짜주느냐"가 아니라, 내 팀의 이슈 트래커·CI/CD·슬랙과 연동해서 자율적으로 작업을 처리할 수 있는지를 평가해야 한다. 오케스트레이션이 실제 제품이 되고 있는 지금, 통합 생태계 없이 코드 품질만 좋은 도구는 곧 한계를 만난다.
2026년의 AI 코딩 도구는 이제 '얼마나 스마트한가'보다 '내 워크플로우에서 어디까지 신뢰할 수 있는가'로 평가받는다. 유출된 소스코드가 무료 마스터클래스가 된 아이러니처럼, 이 생태계의 투명성과 신뢰 구조는 아직 개발 중이다. 도구를 선택하는 것은 결국 그 불완전함을 얼마나 감수할 것인지에 대한 결정이기도 하다.