실제 프로덕션 환경에서 RAG(검색증강생성) 시스템을 서빙해 본 데이터 파이프라인 엔지니어라면 누구나 직면하는 두 가지 치명적인 병목이 있다. 첫째는 사용자의 질의가 발생한 직후에만 트리거되는 '동기식(Synchronous) 검색 지연 시간(Latency)'이며, 둘째는 멀티홉(Multi-hop) 추론 시 발생하는 '컨텍스트 비대화(Context Bloat)' 현상이다. 최근 세일즈포스(Salesforce)와 크로마(Chroma)가 각각 공개한 새로운 에이전트 아키텍처는 이 두 가지 병목을 단순한 인프라 확장이 아닌, '비동기적 선제 검색(Pre-fetching)'과 '검색-생성의 분리'라는 모델링 관점에서 정량적으로 타파했다는 점에서 매우 중요한 실무적 시사점을 제공한다.
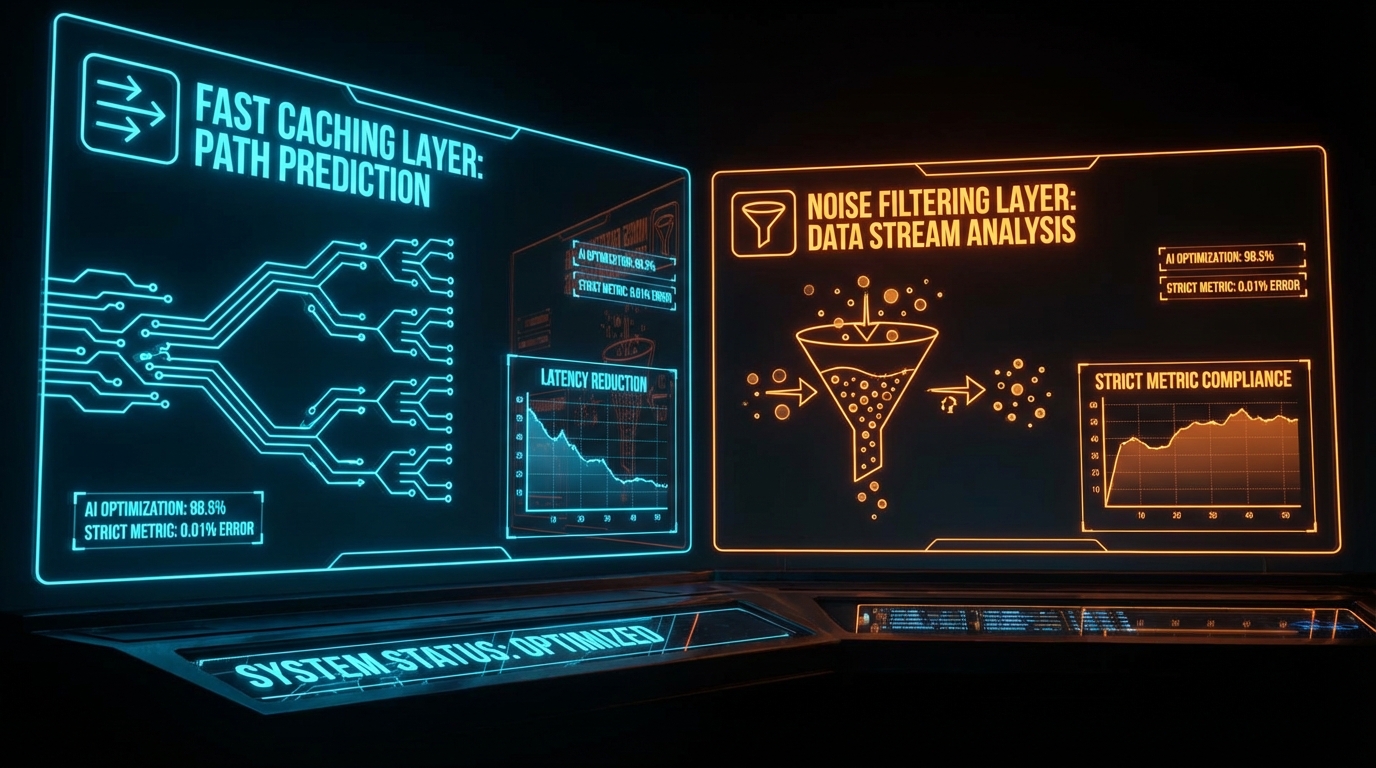
먼저 지연 시간(Latency) 문제를 살펴보자. 실시간 음성 AI의 자연스러운 대화 기준은 응답 시간 200ms 이내로 엄격하게 제한된다. 그러나 전통적인 단방향 RAG 파이프라인은 질의 임베딩, 벡터 DB 검색(통상 50~300ms 소요), 프롬프트 조립, 그리고 LLM 추론이라는 직렬적 I/O 스텝을 거치며 P99(상위 1% 지연 시간)가 수 초를 훌쩍 넘기기 일쑤다. 세일즈포스가 최근 공개한 '보이스에이전트RAG(VoiceAgentRAG)'는 이러한 직렬 구조를 '패스트 싱커(Fast Talker)'와 '슬로우 싱커(Slow Thinker)'라는 듀얼 에이전트 아키텍처로 분리하여 병목을 근본적으로 해소했다.
이 구조의 핵심은 런타임의 추론 경로(Critical Path)에서 외부 DB I/O를 완전히 제거했다는 데 있다. 백그라운드에서 비동기적으로 동작하는 슬로우 싱커는 사용자의 대화 맥락을 기반으로 다음 질의를 '예측'하고 관련 문서를 로컬 시맨틱 캐시(Semantic Cache)에 선제적으로 적재(Pre-fetching)한다. 사용자와 직접 대면하는 패스트 싱커는 오직 이 캐시만 조회한다. 실험 데이터에 따르면, 이 아키텍처는 최대 80~95%의 놀라운 캐시 적중률(Hit Rate)을 달성했다. 캐시 적중 시 검색 지연 시간은 기존 110ms에서 0.35ms로 무려 316배 단축되었다. 이는 시스템의 병목을 'I/O 바운드'에서 '메모리 바운드'로 전환함으로써 실시간성을 확보한 수학적 최적화의 모범 사례다.
반면 크로마(Chroma)가 출시한 '컨텍스트-1(Context-1)'은 RAG 파이프라인의 또 다른 난제인 '컨텍스트 로트(Context Rot, 맥락 부패)'를 해결한다. 업계 일각에서는 거대언어모델(LLM)의 컨텍스트 윈도우 크기(Context Window Size)가 수백만 토큰으로 확장되면 RAG의 검색 품질 문제가 자연스레 해결될 것이라는 맹신이 존재했다. 그러나 무차별적인 프롬프트 스터핑(Prompt Stuffing)은 토큰 비용의 기하급수적 증가를 초래할 뿐만 아니라, 중간 맥락 상실(Lost in the middle) 현상으로 인해 Generation Quality(Answer Relevance)를 오히려 훼손한다. 특히 여러 문서를 교차 검증해야 하는 에이전틱 서치(Agentic Search) 환경에서는 탐색 턴이 길어질수록 성능이 급락하는 '성능 절벽(Performance cliff)'이 명확하게 관측된다.
컨텍스트-1은 검색과 생성을 완전히 분리한 200억(20B) 파라미터 규모의 '검색 전용 서브 에이전트'다. 이 모델의 가장 강력한 무기는 '자기 편집 컨텍스트(Self-editing context)' 기능이다. 사용자의 복합 질의를 하위 질의로 분해하고 턴당 평균 2.56회의 병렬 검색을 수행하는 과정에서, 시스템 스스로 불필요한 정보를 식별하여 문서를 제거한다. 실험 결과, 이 모델은 무려 94%의 정확도로 노이즈를 제거해 내며 컨텍스트를 3만 2천(32k) 토큰 이내로 억제했다. 이는 Context Precision(검색된 문서 중 정답과 관련된 문서의 비율)을 극대화하여 최종 추론 LLM의 연산 부담과 환각(Hallucination) 리스크를 동시에 통제하는 매우 경제적인 트레이드오프 설계다.
세일즈포스와 크로마의 접근법은 표면적으로는 달라 보이지만, 프로덕션 관점에서는 하나의 뚜렷한 아키텍처 패러다임을 지향한다. 바로 '역할 분리(Separation of Concerns)'를 통한 토큰 효율성과 파이프라인의 결정론적 통제다. 세일즈포스는 '시간축'을 동기와 비동기로 분리하여 지연 시간(Latency)을 최적화했고, 크로마는 '기능축'을 필터링(검색)과 추론(생성)으로 분리하여 토큰 비용(Cost)과 품질(Quality)을 최적화했다. 무거운 단일 SOTA 모델 하나로 모든 것을 해결하려는 'Monolithic LLM' 접근법은 실제 서빙 환경에서 유지보수 불가(Unmaintainable) 상태에 빠진다는 것을 방증한다.
결론적으로, 신뢰성 있는 AI 서비스를 구축하고자 하는 조직이라면 단순한 벡터 DB 연동을 넘어 시스템 아키텍처 단위의 튜닝을 고려해야 한다. 사용자의 P99 지연 시간에 민감한 서비스라면 슬로우 싱커를 활용한 '예측형 캐싱'을 도입하여 API 호출 비용과 응답 속도를 방어해야 한다. 또한, 복잡한 B2B 도메인 데이터 기반의 질의응답 시스템을 구축 중이라면, 무작정 더 큰 모델을 도입하기 전에 컨텍스트-1과 같은 특화된 필터링 모델을 통해 입력 토큰의 '신호 대 잡음비(SNR)'를 정량적으로 개선하는 파이프라인 구축이 선행되어야 할 것이다.